
Création d'une Application Web tout-en-un pour la science des données à l'aide de Python : évaluation de l'outil en source ouverte Django
Par : Nikhil Widhani, Statistique Canada
Du fait des progrès technologiques considérables, de nombreux outils et techniques utilisés au sein de la communauté de la science des données effectuent une lente transition vers la source ouverte. Les outils en source ouverte sont des solutions sans frais dont le code base peut être modifié pour l'adapter aux besoins de l'utilisateur, lui fournissant ainsi souplesse et réduction des coûts. Des outils exclusifs permettent généralement de faire le travail de façon efficace, mais ils peuvent être coûteux et doivent toujours être adaptés aux besoins de l'organisation. Les outils exclusifs manquent souvent d'options de personnalisation et ne résolvent parfois qu'une partie d'un problème. Dans le cas d'enjeux plus complexes, comme créer une collection de microservices relatifs à diverses tâches, il peut être nécessaire d'utiliser simultanément plusieurs outils exclusifs.
Les outils en source ouverte, donnant à l'utilisateur un contrôle total du code base, permettent aux organisations d'appliquer des correctifs de sécurité en cas de nouvelles menaces et de maintenir la protection des renseignements personnels et la confidentialité des données. De nombreux projets en source ouverte peuvent être combinés pour former une solution centrale répondant à une exigence plus vaste.
Prenons l'exemple d'un projet permettant de créer un pipeline sécurisé pour l'ingestion de données. Des modules séparés de ce processus pourraient inclure d'extraire régulièrement de nouvelles données obtenues de manière éthique, d'exécuter des algorithmes d'apprentissage automatique responsables aux moments opportuns et de créer un tableau de bord permettant la visualisation des données. Dans le présent article, je vais expliquer le processus d'utilisation d'un cadre de travail Web Django, afin de créer une application Web tout-en-un prête pour la production fournissant de l'information, tout en protégeant les renseignements personnels et la confidentialité des données qu'elle utilise. Cette solution particulière a recours à un tableau de bord pour les clients et à une interface utilisateur graphique (IUG) pour les développeurs. L'IUG d'administration peut servir à exécuter régulièrement des tâches planifiées afin d'extraire de nouvelles données et d'exécuter un pipeline d'un clic de bouton.
Django est un cadre de travail Web en source ouverte fondé sur le langage de programmation Python et est utilisé par des firmes multinationales. Sa conception de base offre souplesse, sécuritéNote de bas de page 1 et évolutivité. Les applications développées avec Django peuvent être réutilisées pour d'autres projets sans devoir récrire le code. Parfois, il suffit de copier le code d'un projet à un autre. Pour créer ce type d'application Web, nous allons utiliser la trousse à outils Django et des modules externes, afin de développer une architecture souple, tout en gardant l'évolutivité à l'esprit. L'architecture proposée est représentée à la figure 1.
Figure 1 : Architecture proposée pour créer une application Web tout-en-un.
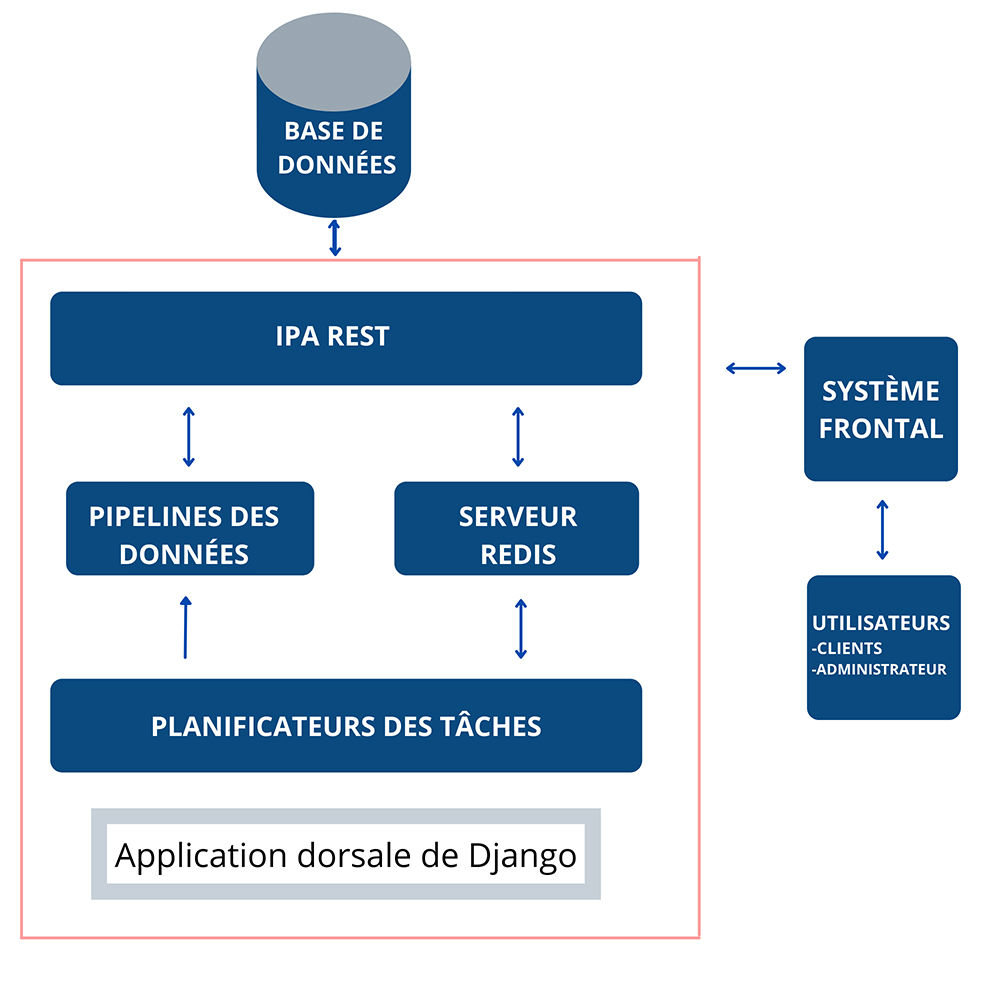
Description - Figure 1 : Architecture proposée pour créer une application Web tout-en-un
Architecture proposée pour créer une application Web tout-en-un. La base de données fonctionne avec l'application dorsale Django (qui comprend l'interface de programmation REST, le pipeline, le serveur Redis et un planificateur de tâches), puis avec le système frontal, comme l'ont développé ses utilisateurs ou administrateurs. Toutes les composantes de ce diagramme sont expliquées ci-dessous.
Composantes
Les composantes de l'architecture et ses fonctions sont la base de données, l'application dorsale, le pipeline, le planificateur de tâches et l'interface de programmation REST. Je vais détailler chacune de ces composantes.
Base de données
Une base de données recueille et stocke des données. Il s'agit de la composante principale d'un projet, puisque toutes les parties d'un projet sont liées aux données. Les bases de données peuvent être classées comme étant relationnelles et non relationnelles. Les bases de données relationnelles peuvent stocker des données de façon structurée dans des tableaux et permettre des relations avec d'autres tableaux. Par défaut, Django prend en charge des bases de données relationnelles, comme PostgreSQL (langage de requête structuré), SQLite et MySQL. Le choix dépend du type de projet; PostgreSQL pouvant être plus adapté à des projets de plus grande envergure, alors que SQLite peut être plus adapté à des projets moins importants, comme ceux comprenant moins de 100 000 lignes. MySQL est généralement utilisé lorsque les capacités de PostgreSQL, comme le soutien pour des données géospatiales ou des types de données avancées, ne sont pas nécessaires. Les bases de données non relationnelles n'utilisent pas le format d'un schéma tabulaire pour stocker les données. Elles ont plutôt recours à des modèles d'objets propres au type de données stockées. Elastic Search consiste en une base de données moderne axée sur les documents couramment utilisée pour effectuer des recherches rapides dans des millions de documents. Elastic Search pourrait être utilisée lorsque l'utilisateur doit stocker un volume important de données et de requêtes devant être exécutées en temps réel. Dans le présent projet, je vais utiliser SQLite qui est adaptée à la taille de la tâche.
Application dorsale
L'application dorsale effectue la majorité du travail. Utiliser Django comme cadre d'application dorsale facilite le travail en bénéficiant des améliorations apportées au cours des 15 ans de développement constant depuis sa parution le 21 juillet 2005.Note de bas de page 2 Les utilisateurs de Django peuvent également tirer profit d'une vaste communauté en ligne. De nombreux progiciels tiers sont en outre disponibles pour répondre à une variété de tâches. Dans les sections suivantes, je vais présenter les progiciels et trousses d'outils utilisés pour créer une application Web tout-en-un pour la science des données.
Pipeline
Dans le domaine de la science des données, un pipeline est un ensemble de codes ou de processus qui convertit des données brutes en données utilisables. Les pipelines peuvent parfois servir à extraire et à structurer des données à partir d'un format brut, alors que dans d'autres cas, ils peuvent utiliser des modèles d'apprentissage automatique afin d'extraire de l'information précieuse à partir des données. Il existe de nombreux cas d'utilisation de pipelines, mais la sélection d'un pipeline dépend des exigences du projet. Souvent, les projets de science des données font intervenir un ensemble de codes Python pouvant être exécutés pour effectuer certaines des opérations.
Planificateur de tâches
Un planificateur de tâches sert à effectuer des tâches asynchrones exécutées en arrière-plan sans interrompre d'autres processus de l'application. Pour des tâches chronophages comme le traitement de pipeline de données, on préfère souvent gérer ces tâches en arrière-plan grâce à des fils d'exécution, sans bloquer le flux normal de requêtes-réponses.Note de bas de page 3 Si votre application Web nécessite, par exemple, que vous téléversiez un document PDF numérisé à prétraiter avant d'invoquer un module d'extraction, l'utilisateur verra une page de chargement jusqu'à ce que le fichier soit traité. Parfois, la page de chargement peut s'afficher plus longtemps que prévu; un message d'erreur de dépassement de délai d'inactivité est alors reçu. Cette erreur se produit, car les navigateurs et les requêtes Web ne sont pas conçus pour attendre interminablement qu'une page se charge. Cela peut être résolu en prétraitant les données du PDF en arrière-plan et en envoyant un avis à l'utilisateur une fois le traitement terminé. Les planificateurs de tâches sont une manière pratique de résoudre ce comportement.
Par défaut, Django ne prend pas en charge la planification de tâches; toutefois, des applications Django tierces, comme Django-Celery,Note de bas de page 4 peuvent intégrer des files d'attente de tâches asynchrones. Ce progiciel peut être installé avec une commande pip install Django-Celery. Une documentation complète est disponible pour la bibliothèque et peut être consultée en cas de besoin. Un serveur d'agents comme Redis est nécessaire pour faciliter la communication entre le planificateur de tâches et l'application dorsale. Redis stocke les messages que produit l'application de file d'attente de tâches Celery décrivant le travail à faire. Redis sert également à stocker les résultats des listes d'attente de Celery, qui peuvent alors être extraits du système frontal pour présenter l'état de la progression à l'utilisateur. Django-Celery peut prendre en charge certains des cas d'utilisation suivants :
- exécuter des tâches cron d'extraction de données planifiées, afin de mettre ces nouvelles données à jour dans la base de données (p. ex. extraction de nouvelles données tous les jours à 4h00);
- nettoyage et restructuration des données;
- exécution de modèles d'apprentissage automatique dès que de nouvelles données sont ingérées;
- mise à jour de la base de données et application des modifications au tableau de bord.
Figure 2: Déroulement du processus d'un planificateur de taches.
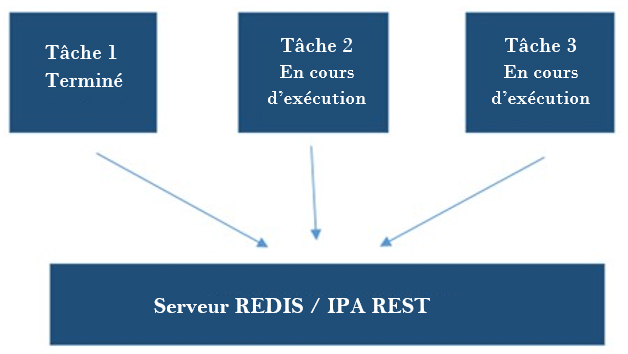
Description - Figure 2: Déroulement du processus d'un planificateur de taches
Déroulement du processus d'un planificateur de tâches. Le serveur Redis agit comme support pouvant lancer des tâches et suivre la progression.
Trois cases en haut sont libellées « Tâche 1 – Terminé », « Tâche 2 – En cours d’exécution » et « Tâche 3 – En cours d’exécution »; chacune pointant individuellement vers la case inférieure libellée « Serveur Redis / IPA REST ».
Figure 3 : Interface utilisateur du planificateur de tâches
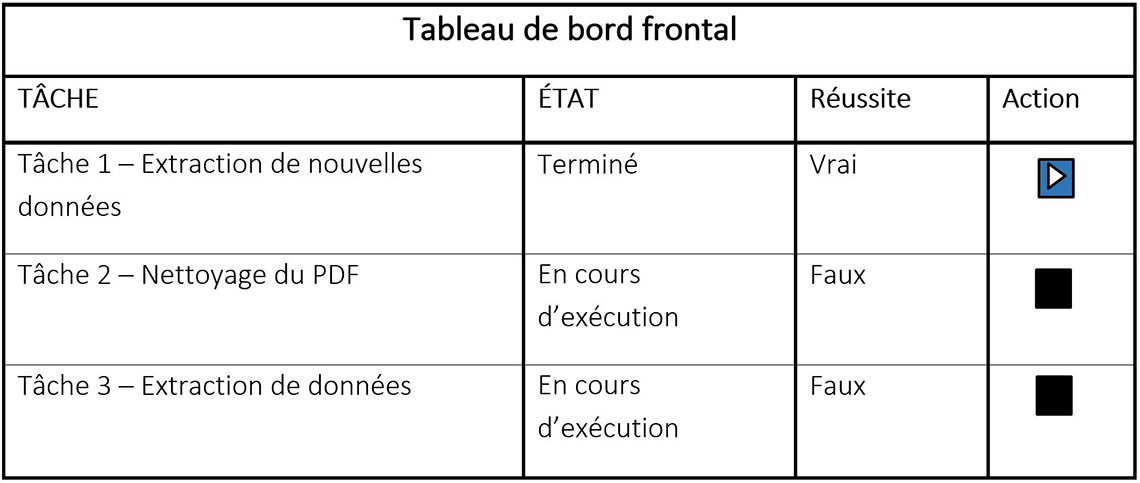
Description - Figure 3 : Interface utilisateur du planificateur de tâches
Interface utilisateur du planificateur de tâches pour le tableau de bord frontal. Le tableau présente également des renseignements utiles, tels que le nom de la tâche, son état et la valeur de sa réussite. La colonne Action comprend un bouton triangulaire d'exécution pour exécuter la tâche et un bouton carré d'arrêt pour mettre fin à la tâche en cours d'exécution.
Les tâches ainsi que leur état, leur réussite et l'action sont les suivantes :
Tâche 1 – Extraction de nouvelles données : état Terminé, réussite Vrai et l'action affiche un bouton triangulaire d'exécution blanc et bleu.
Tâche 2 – Nettoyage du PDF : état En cours d'exécution, réussite Faux et l'action affiche un bouton carré noir d'arrêt.
Tâche 3 – Extraction des données : état En cours d'exécution, réussite Faux et l'action affiche un bouton carré noir d'arrêt.
Exécuter ainsi un pipeline permet une meilleure utilisation des ressources; l'exécution des tâches de pipeline pouvant être planifiées la nuit, lorsqu'un moins grand nombre d'utilisateurs utilisent l'application. Séparer les tâches de production et les tâches de développement permet également un développement plus efficace. Toutes les parties distinctes du projet peuvent être combinées en une seule application prête pour la production. Enfin, exécuter le pipeline peut fournir aux utilisateurs un contrôle supplémentaire sur le produit, puisqu'ils peuvent facilement exécuter le pipeline comme ils le souhaitent.
Interfaces de programmation REST
Les interfaces de programmation (IPA) sont des microservices simplifiant le développement de logiciels. Elles sont souvent utilisées pour séparer des fonctions distinctes d'une application en services Web de moindre envergure. Lors de la recherche d'une adresse à l'aide d'un code postal, par exemple, une IPA REST de recherche d'adresses retournera toutes les adresses de voirie au sein de la zone du code postal. La réponse est souvent fournie au format JSON (notation d'objet JavaScript), une norme de l'industrie comprise par de nombreuses applications et de nombreux langages de programmation. Une IPA REST prend en charge de multiples méthodes; les plus courantes étant GET, POST, DELETE et UPDATE. Chaque méthode sépare la logique et permet de structurer le code. Ces méthodes s'expliquent d'elles-mêmes et sont respectivement responsables d'obtenir, d'ajouter ou de publier de nouvelles données, de supprimer et de mettre à jour des données. Utiliser des IPA REST dans des applications Web agit comme un intergiciel entre une base de données et un système frontal, protégeant la base de données de vulnérabilités en matière de sécurité.
Dans Django, il est possible de créer des IPA avec une simple réponse HTTP JSON. Toutefois, une trousse d'outils en source ouverte dédiée appelée Django-rest-framework permet de créer des IPA.Note de bas de page 5 Les avantages d'utiliser le cadre Django REST incluent, entre autres, les suivants :
- une IPA prête à utiliser pouvant être recherchée en ligne;
- des politiques intégrées d'authentification en matière de sécurité des données;
- des convertisseurs préconçus pouvant facilement convertir un objet Python en objet JSON;
- une documentation complète, personnalisable et prise en charge par divers autres modules Django externes.
Pour des cas d'utilisation similaires à ce qui est présenté dans cet article, le cadre Django REST peut être utilisé pour créer des IPA de données et d'extraction de tâches et de progression de pipeline lors d'une exécution en arrière-plan. Ces données peuvent être intégrées au système frontal pour indiquer la progression comme l'illustre la figure 4.
Figure 4 : Traitement des fichiers PDF

Description - Figure 4 : Traitement des fichiers PDF
Barre de progression indiquant la progression d'un code traitant des fichiers PDF. La barre indique 70 %. Lors du traitement d'un fichier PDF, la taille de la barre de progression, la valeur en pourcentage et le nombre de fichiers traités sont mis à jour pour refléter l'état du pipeline.
Le texte au-dessus de la barre de progression indique Exécution d'un pipeline d'extraction de PDF et le texte sous la barre de progression indique 7/10 fichiers traités. Il reste 2 minutes.
Sécurité
Il conviendrait de toujours considérer la sécurité lors de l'examen des options de cadre de travail. Dans le présent article, je mentionne le cadre Python de Django et certains de ses progiciels. Django est un cadre présentant de nombreuses fonctionnalités de sécurité. Il prend en charge le déploiement derrière des sites https et chiffrés à l'aide de SSL (couche de sockets sécurisée). Django ORM (mise en correspondance relationnelle d'objets) protège également contre des requêtes SQL de type injection, avec lesquelles des utilisateurs peuvent exécuter du code SQL indésirable dans la base de données. Il authentifie également des adresses Web au moyen d'une valeur « ALLOWED_HOSTS » (hôtes autorisés) dans le fichier de paramètres, qui comprend le nom d'hôte de la page Web. Ce paramètre évite des attaques « cross-site scripting » (injection de contenu) avec lesquelles des noms d'hôte fictifs peuvent être utilisés.
À Statistique Canada, bon nombre des applications Web Python sont déployées dans l'Espace de travail d'analyse avancée qui respecte les lignes directrices de StatCan en matière de sécurité, de protection des renseignements personnels et de confidentialité. Des éléments standard de protection de réseau, comme des pare-feu, la gestion du trafic, des droits d'utilisateur réduits pour le code de l'application et la séparation des préoccupations, servent tous à réduire la surface d'attaque générale pour tout vecteur potentiel. De plus, RBAC (contrôle de l'accès fondé sur le rôle) sert à limiter l'accès au tableau de bord, évitant que des utilisateurs indésirables accèdent aux applications. Diverses méthodes d'analyse et de détection des vulnérabilités permettent également de veiller au maintien de l'activité des applications sécurisées.
Conclusion
Dans le présent article, nous avons traité d'une possibilité de création d'application Web pouvant servir à exécuter automatiquement un pipeline, ainsi que de la composante de tableau de bord pour les clients. Nous avons également discuté de techniques et d'outils modernes pouvant être utilisés avec la programmation Python pour atteindre des résultats.
La composante frontale peut être créée à l'aide de Django et d'une combinaison de langages, tels que HTML (langage de balisage hypertexte), JavaScript et CSS (feuilles de style en cascade). D'autres cadres, comme React, peuvent également être utilisés. Ce type de système dorsal peut également être intégré à Microsoft PowerBI, à l'aide d'une IPA. Même si la création du système frontal est hautement subjective, utiliser des modèles Django pour le système frontal est utile, car il peut servir à créer une application Web tout-en-un. Dans ce cadre de travail, les possibilités sont infinies. L'architecture aide principalement à réduire le codage, les ressources et la maintenance, et facilite la création d'applications réutilisables pour des projets similaires. Elle consiste en de nombreuses composantes non isolées pouvant être réutilisées pour d'autres applications à l'aide d'une architecture de microservices.
L'article du Réseau de la science des données intitulé Déploiement de votre projet d'apprentissage automatique en tant que service développe plus en détail les pratiques mentionnées propres au développement de projets. Les techniques et concepts décrits dans le présent article sont également utiles aux diverses étapes du développement de projet et pourraient être intégrés lors du déploiement d'applications. Des liens vers la plupart des ressources figurent dans les références.
Pour de plus amples renseignements, veuillez communiquer avec nous à l'adresse statcan.datascience-sciencedesdonnees.statcan@statcan.gc.ca.
Répondez à notre bref sondage de 2 minutes
Nous avons besoin de votre aide pour améliorer le Réseau de la science des données. Merci de consacrer 2 minutes à répondre à quelques questions rapides. Vos commentaires sont bienvenus et précieux. C'est votre dernière chance de répondre au Sondage sur le bulletin d'information du Réseau de la science des données. Nous remercions ceux et celles qui y ont déjà répondu!
- Date de modification :