
S’attaquer à la surcharge de renseignements : l’application d’intelligence artificielle « Document Cracker » d’Affaires mondiales Canada rationalise les efforts de réponse aux crises
Par : l’équipe de science des données d’Affaires mondiales Canada
Introduction
Lorsqu’une crise mondiale survient, les représentants du gouvernement sont souvent confrontés au défi de passer au crible un déluge de nouveaux renseignements pour trouver ceux qui sont importants et qui les aideront à gérer efficacement la réponse du Canada. Par exemple, à la suite de l’invasion de l’Ukraine par la Russie en février 2022, une proportion importante des missions diplomatiques du Canada ont commencé à rédiger des rapports de situation sur les développements locaux liés au conflit. Compte tenu du nombre élevé de ces rapports de situation, ainsi que des comptes rendus de réunions, des déclarations tirées de réunions internationales et des rapports des médias d’information, il est rapidement devenu impossible pour les décideurs individuels de lire manuellement tous les renseignements pertinents mis à leur disposition.
Pour relever ce défi, l’équipe de science des données d’AMC a mis au point un outil de recherche et d’analyse de documents appelé Document Cracker (ci-après « DocCracker ») qui aide les représentants à trouver rapidement les renseignements dont ils ont besoin. À la base, DocCracker offre deux fonctions essentielles : 1) la possibilité d’effectuer des recherches dans un grand nombre de documents à l’aide d’une plateforme d’indexation sophistiquée; 2) la possibilité de surveiller automatiquement les nouveaux documents pour y trouver des sujets particuliers, des tendances émergentes et des mentions de personnes, de lieux ou d’organisations clés. Dans le contexte de l’invasion russe, ces fonctions de l’application visent à permettre aux représentants du Canada de relever rapidement les questions urgentes, d’adopter une position privilégiée par rapport à celles-ci et de suivre l’évolution des positions des autres pays. Grâce à de tels renseignements, l’application peut jouer un rôle clé en aidant les responsables à concevoir et à mesurer les répercussions actuelles de la réponse du Canada à la crise.
Veuillez prendre note que même si DocCracker a été mis au point expressément en réponse aux événements en Ukraine, l’application a également été conçue comme application multilocataire qui peut fournir des interfaces de recherche et de suivi distinctes pour de nombreuses questions mondiales en même temps. Par exemple, l’agrandissement de l’application est en cours pour soutenir l’analyse des événements géopolitiques au Moyen-Orient.
Aperçu de l’application
Du point de vue de l’utilisateur, l’interface de DocCracker comprend une page de destination qui comporte une barre de recherche et une variété de fiches de contenu qui suivent les mises à jour récentes concernant des régions géographiques et des personnes d’intérêt précises. L’utilisateur peut se concentrer sur ces mises à jour récentes ou effectuer une recherche, qui renvoie une liste de documents classés. La sélection d’un document permet d’accéder à la transcription sous-jacente, ainsi qu’à l’ensemble des liens vers des documents connexes. Les utilisateurs peuvent également accéder aux métadonnées associées à chaque document, qui comprennent des listes de sujets, d’organisations, de personnes, de lieux et de phrases clés extraites automatiquement. En tout temps, une bannière située en haut de la page de l’application permet aux utilisateurs d’accéder à une série de tableaux de bord qui mettent en évidence les tendances globales et propres à la mission concernant une liste prédéfinie de 10 sujets importants (p. ex. la sécurité alimentaire, les crimes de guerre et la crise de l’énergie).
Pour permettre ces expériences utilisateur, DocCracker met en œuvre un pipeline logiciel qui : a) charge les nouveaux documents disponibles à partir d’un éventail de sources de données internes et externes; b) « déchiffre » ces documents en appliquant une variété d’outils de traitement du langage naturel pour extraire des données structurées; c) utilise ces données structurées pour créer un index de recherche qui prend en charge les requêtes et la création de tableaux de bord. La figure 1 ci-dessous donne un aperçu visuel du pipeline.

Figure 1 : Pipeline de traitement de DocCracker
Pendant la phase de « chargement » du pipeline, les sources de données internes et externes sont intégrées et prétraitées pour extraire des métadonnées de base, telles que le type de rapport, la date du rapport, l’emplacement de la source, le titre et l’URL du site Web. Pendant la phase de « déchiffrage » du pipeline, les documents téléchargés sont soumis à une série d’outils de traitement du langage naturel afin de fournir des étiquettes thématiques, de déterminer les entités nommées, d’extraire des résumés et de traduire en anglais tout texte qui n’est pas en anglais. Pendant la phase d’« indexation » définitive du pipeline, les documents déchiffrés sont utilisés pour créer un index de recherche qui prend en charge les requêtes documentaires souples et la création de tableaux de bord qui fournissent des instantanés agrégés des caractéristiques des documents utilisés pour alimenter cet index de recherche.
Détails de la mise en œuvre
DocCracker est hébergé en tant qu’application Web dans l’environnement infonuagique de Microsoft Azure et il s’appuie sur les services Azure pour prendre en charge chaque étape du traitement.
Ingestion des données
Au cours de la phase de « chargement », les documents sont rassemblés dans un conteneur de stockage Azure, soit par des extractions automatiques effectuées à partir de sources externes (p. ex. le fil de nouvelles Factiva, les bases de données non protégées d’AMC), soit au moyen de téléchargements manuels. Ensuite, une série de scripts Python est exécutée pour éliminer les documents en double ou erronés et procéder à un nettoyage préliminaire du texte et à l’extraction de métadonnées. Étant donné que les documents englobent une variété de formats de fichiers (.pdf, .txt, .msg, .docx, etc.), différentes méthodes de nettoyage et d’extraction sont appliquées à différents types de documents. Dans tous les cas, cependant, la bibliothèque d’expressions normales de Python est utilisée pour éliminer le texte non pertinent (p. ex. les signatures de courriel, les listes de copies conformes invisibles) et extraire les métadonnées pertinentes (p. ex. le titre ou l’objet des courriels, la date de soumission).
Les expressions normales fournissent une syntaxe puissante permettant de préciser des ensembles de chaînes à rechercher dans un corps de texte. Officiellement, une expression normale donnée définit un ensemble de chaînes de caractères qui peuvent toutes être reconnues par un automate d’états finis qui subit des transitions d’état à la réception de chaque caractère de l’étendue du texte d’entrée; si ces transitions d’état font en sorte que l’automate saisisse un état d’« acceptation », alors l’étendue de l’entrée devient un membre de l’ensemble des chaînes de caractères recherchées. Lorsqu’elles sont détectées, ces chaînes peuvent être soit supprimées (pour nettoyer les données), soit extraites (pour recueillir des métadonnées). Presque tous les langages de programmation prennent en charge les expressions normales, et elles constituent souvent un outil de premier recours dans les projets de nettoyage et d’ingénierie des données.
Traitement du langage naturel
Une fois les documents prétraités, ils sont divisés en portions de texte d’un maximum de 5 120 caractères afin de satisfaire aux exigences de longueur d’entrée de nombreux services de traitement du langage naturel d’Azure. Chaque portion de texte est traitée pour supprimer l’information non linguistique, comme les URL, les espaces blancs vides et les puces. Les portions sont ensuite transférées dans un nouveau conteneur de stockage pour subir un traitement supplémentaire à l’aide d’une variété de modèles d’apprentissage automatique.
Pour relever les mentions de personnes, d’organisations et de lieux, chaque portion de texte est traitée à l’aide d’un service Azure qui effectue la reconnaissance d’entités nommées. Ce service permet de mettre en correspondance des portions de texte avec un ensemble prédéfini de types d’entités. Ensuite, des services semblables sont utilisés pour extraire des phrases clés et quelques phrases de résumé de chaque document, tout en effectuant des traductions en ligne des textes qui ne sont pas en anglais. Enfin, un service d’analyse de sentiments est utilisé pour fournir des évaluations des sentiments portant sur des organisations précises, qui seront affichées sur la page de destination de l’application. Les résultats de chaque service Azure sont enregistrés dans une base de données SQL sous forme d’attributs de métadonnées associés aux documents sous-jacents qui ont été traités.
Pour améliorer ces résultats obtenus avec Azure, l’équipe de science des données d’AMC a également mis au point un modèle d’étiquetage thématique personnalisé qui relève la présence de l’un des 10 sujets d’intérêt précis dans chaque portion de texte. Ce modèle s’appuie sur une technique appelée « BERT » (Bidirectional Encoder Representations from Transformers, ou représentations de l’encodeur bidirectionnel à partir de transformeurs en français) pour analyser des portions de texte et déterminer quels sujets prédéfinis sont présents dans le texte. Le modèle fournit une liste des sujets trouvés, qui peut aller de 0 à 10 étiquettes thématiques.
Comme le montre la figure 2 ci-dessous, le modèle a été élaboré de manière itérative au moyen de volumes croissants de données d’entraînement étiquetées. Lors du troisième cycle d’entraînement du modèle, des résultats de classification très précis ont été obtenus pour 8 des 10 sujets, tandis que des résultats moyennement précis ont été obtenus pour 2 des 10 sujets. La vérification du modèle a été effectuée en utilisant 30 % des échantillons de données étiquetées, tandis que l’entraînement du modèle a été réalisé en utilisant les 70 % d’échantillons restants. Au total, environ 2 000 échantillons étiquetés ont été utilisés pour élaborer le modèle.
Bien qu’il s’agisse d’une petite quantité de données par rapport aux approches habituelles de développement de systèmes d’apprentissage automatique supervisé, l’un des principaux avantages de l’utilisation d’une architecture BERT est que le modèle est d’abord préentraîné au moyen d’une grande quantité de textes non étiquetés avant d’être ajusté avec précision pour effectuer une tâche d’intérêt. Lors du préentraînement, le modèle apprend simplement à prédire les mots manquants qui ont été supprimés de manière aléatoire dans un corpus textuel. En accomplissant cette tâche, le modèle crée des représentations internes très précises des propriétés statistiques du langage humain. Ces représentations peuvent ensuite être réutilisées efficacement au cours de la phase d’ajustement pour apprendre des décisions de classification efficaces à partir d’un petit nombre d’exemples étiquetés.
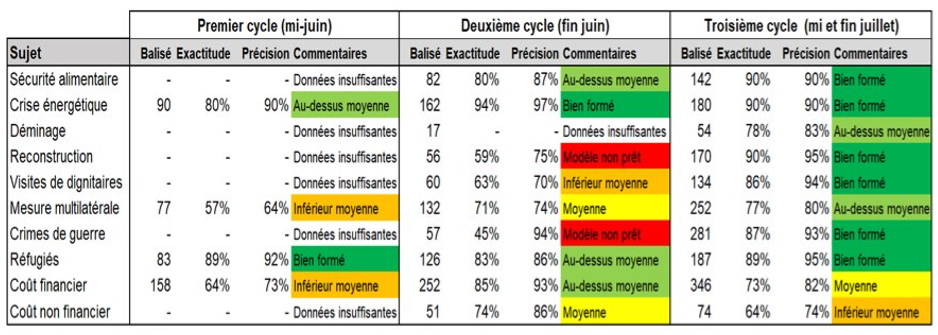
Figure 2 : Résultats de l’entraînement du modèle d’IA DocCracker
Les résultats de l’évaluation sont présentés après trois cycles d’entraînement pour un modèle de détermination de sujets personnalisé qui effectue une classification à étiquettes multiples pour relever jusqu’à 10 sujets prédéfinis dans une portion de texte d’entrée. Grâce aux augmentations progressives de la quantité de données d’entraînement, le modèle de réseau neuronal basé sur un transformateur obtient des résultats très précis pour presque tous les sujets.
Enfin, les résultats du modèle thématique sont enregistrés dans la base de données SQL en tant qu’attributs de métadonnées supplémentaires pour chaque document sous-jacent. Cette base de données contient maintenant tous les documents qui ont été intégrés, ainsi qu’une riche collection de métadonnées obtenues à l’aide des techniques de traitement du langage naturel décrites précédemment. Grâce à cette combinaison de documents et de métadonnées, il est possible de créer un index de recherche qui permet aux utilisateurs d’effectuer des recherches souples dans les documents et de créer des visualisations de tableau de bord informatives.
Indexation
Dans sa forme la plus simple, un index de recherche est une collection d’un ou de plusieurs tableaux qui fournissent des liens entre les termes de recherche et les ensembles de documents qui correspondent à ces termes. Lorsqu’un utilisateur effectue une requête de recherche, celle-ci est décomposée en un ensemble de termes qui sont utilisés pour rechercher des documents dans l’index. Un algorithme de classement est ensuite utilisé pour hiérarchiser les documents qui correspondent à chaque terme de manière à obtenir une liste ordonnée des documents les plus pertinents par rapport à la requête de recherche.
Dans DocCracker, le service de recherche cognitive d’Azure est utilisé pour créer automatiquement un index à partir de la base de données SQL produite au cours des étapes précédentes du pipeline de traitement. Une fois cet index créé, il est facile de créer une page de destination qui permet aux utilisateurs d’entrer des requêtes de recherche et d’obtenir des documents pertinents. Les métadonnées utilisées pour créer l’index peuvent aussi être exportées vers des fichiers CSV afin de créer des tableaux de bord permettant de suivre une série de mesures variant dans le temps de l’évolution de la situation en Ukraine. Par exemple, en sélectionnant les champs de métadonnées pour les étiquettes des sujets et les dates, il est possible d’afficher la fréquence à laquelle différents sujets ont été mentionnés au fil du temps. De même, en sélectionnant des entités nommées, il est possible de visualiser les personnes ou les organisations qui ont été mentionnées le plus souvent au cours d’une période donnée. On peut aussi facilement faire le suivi du volume de rapports émanant des différentes missions à l’aide d’une méthode de sélection semblable.
Dans l’ensemble, l’index de recherche fournit une représentation structurée des nombreux rapports de situation, rapports et articles de presse non structurés qui ont été intégrés dans DocCracker. En ayant cette représentation structurée en main, il devient possible de mettre en place des capacités de recherche et de suivi qui facilitent l’important travail d’analyse effectué par les représentants d’AMC chargés de gérer la réponse du Canada à l’invasion russe.
Prochaines étapes
Compte tenu de la rapidité toujours croissante avec laquelle les crises internationales sont rapportées, il est essentiel de mettre au point des outils comme DocCracker qui aident les analystes à tirer des renseignements de grands volumes de données textuelles. Pour parfaire la version actuelle de cet outil, l’équipe de science des données d’AMC travaille simultanément sur plusieurs améliorations. Tout d’abord, l’allocation de Dirichlet latente est évaluée pour déterminer automatiquement les nouveaux sujets à mesure qu’ils sont abordés dans les documents entrants, ce qui permet d’informer les analystes sur les nouvelles questions qui pourraient nécessiter leur attention. Ensuite, des modèles de transformateurs génératifs préentraînés sont utilisés pour résumer automatiquement de multiples documents, ce qui aide ainsi les analystes à produire plus rapidement des notes d’information pour les décideurs supérieurs. Enfin, des modèles de détection des positions sont en cours d’élaboration afin de déterminer automatiquement les positions adoptées par les différents pays sur des questions diplomatiques précises (p. ex. la question de la fourniture de systèmes d’armes avancés à l’Ukraine). En ayant de tels modèles en main, les analystes devraient être en mesure de suivre la manière dont les pays adaptent leurs positions sur une question donnée en réponse à la fois aux incitations diplomatiques et à l’évolution des conditions géopolitiques.
Dans l’ensemble, à mesure que des outils comme DocCracker sont plus largement utilisés, nous nous attendons à voir émerger une série de nouvelles applications axées sur la technologie sous-jacente. Pour discuter de ces applications ou pour en savoir plus sur les efforts continus de l’équipe de science des données d’AMC dans ce domaine, veuillez envoyer un courriel à l’adresse suivante : datascience.sciencedesdonnees@international.gc.ca.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 15 juin
De 13 00 h à 16 00 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :