
Cas d'utilisation sur la gestion des métadonnées
par : Ekramul Hoque, Statistique Canada
Que sont les métadonnées?
Les métadonnées sont des données qui fournissent des renseignements sur d'autres données. En d'autres termes, il s'agit de « données sur des données ». Il s'agit de l'une des composantes essentielles de la gouvernance des données, car elle impose des règles de gestion en matière de collecte et de contrôle des données. Les scientifiques de données consacrent un temps considérable à rassembler et à comprendre les données. Nous pouvons générer des aperçus plus rapides lorsque nous avons accès aux métadonnées sous-jacentes.
Pourquoi une organisation a-t-elle besoin d'un système de gestion des métadonnées?
Lorsqu'une organisation dispose d'un système de gestion des métadonnées, cela signifie que ses employés peuvent ajouter des métadonnées dans leurs référentiels de manière rapide et précise sans aucune incidence sur l'accès aux données au sein de leurs systèmes. Cela permet d'accroître la créativité des flux de travail et de renforcer les processus opérationnels. Par exemple, l'une des activités principales de Statistique Canada consiste à effectuer une analyse statistique d'un large éventail de types et de quantités de données. Pour y parvenir efficacement, les analystes doivent être en mesure d'identifier rapidement les données les plus utiles pour en déterminer la structure et la sémantique.
Parmi les principaux avantages de la gestion des métadonnées, notons les suivants :
- Optimisation de l'utilisation des données pertinentes et accroissement de leur qualité
- Plateforme commune permettant à divers groupes d'utilisateurs des données de discuter et de gérer efficacement leur travail. Par exemple, les ingénieurs de données, qui travaillent avec des métadonnées techniques et des normes de type de données, peuvent fournir une assistance pour la génération et la consommation de métadonnées
- Délais de livraison de projets plus courts grâce à une meilleure intégration des données sur diverses plateformes
Naturellement, une analyse de données réussie repose sur une gestion solide des métadonnées. Une bonne gestion des métadonnées peut également améliorer la capacité en matière de découverte des données. Elle résume l'information fondamentale de base sur les données, ce qui facilite la recherche et le suivi.
L'automatisation des métadonnées est une tendance récente de l'industrie qui remplace le processus de plus en plus fastidieux de la mise en correspondance manuelle des données pendant la gestion des métadonnées. Parmi les principaux avantages de l'automatisation, citons l'assurance de la qualité des données et le raccourcissement des délais de réalisation des projets grâce à une meilleure intégration des données sur diverses plateformes. La gestion des métadonnées garantit la conformité à la réglementation grâce à la normalisation des données. Elle améliore également la productivité et réduit les coûts. La gestion des métadonnées permet de connaître les données existantes et leur valeur potentielle, favorisant ainsi la transformation numérique; celle-ci permet aux organisations de connaître les données dont elles disposent et leur valeur potentielle.Note de bas de page 1
Normalisation des données
Lorsque les données sont fournies par des partenaires externes, il est probable que leur système ou application ait été créé indépendamment. La normalisation des données établit une compréhension mutuelle de la signification et de la sémantique des données, ce qui permet aux utilisateurs de les interpréter et de les utiliser de manière appropriée.Note de bas de page 2
Dans le cadre du Collectif canadien de normalisation en matière de gouvernance des données, Statistique Canada a adopté les recommandations de l'initiative d'échange de données et de métadonnées statistiquesNote de bas de page 3 (SDMX), un projet international qui vise à normaliser et à moderniser les mécanismes et les processus d'échange de données et de métadonnées. Les règles SDMX sont maintenant diffusées sous l'égide de l'Organisation internationale de normalisation et sont approuvées à titre de norme officielle à Statistique Canada.
SDMX est un cadre qui permet de normaliser à la fois les données et les métadonnées. Bien qu'il soit bien implanté dans le Système des comptes nationaux de Statistique Canada, il est encore en phase initiale d'introduction dans d'autres secteurs de l'organisation. Cette méthode d'interopérabilité des données devrait permettre :
- de réduire les doublons;
- de mieux comprendre les concepts;
- de cerner les lacunes statistiques;
- de faciliter le rapprochement des données;
- d'approfondir les analyses.
La norme SDMX pourrait être exploitée, par harmonisation, dans un format « normatif léger et souple » permettant l'utilisation d'outils pour produire rapidement des couches d'infrastructure et d'interopérabilité, ce qui faciliterait l'échange rapide de l'information.
Catalogage des données
Le catalogage des données est un autre élément clé de la gestion des métadonnées. Cette expression est communément définie comme la découverte de données utiles à partir d'ensembles de données participants. Elle a pour objectif principal d'employer des méthodes cohérentes pour trouver les données et les renseignements qui leur sont associés. La figure 1 illustre comment les processus d'analyse changent lorsque les analystes utilisent un catalogue de données.
Figure 1 : Processus avec et sans catalogue de données. Graphique tiré d' Alation - Data Intelligence + Human Brilliance (le contenu de cette page est en anglais)

Figure 1 : Processus avec et sans catalogue de données
Voici deux graphiques.
Le premier graphique montre comment les processus fonctionnent sans catalogue de données. On y voit un cercle jaune comportant les mots « Documentation disponible et connaissance organisationel ». Une flèche pointe vers le bas vers une case bleue comportant la mention « Trouver les données ». De là, une flèche pointe à droite vers une autre case bleue comportant la mention « Obtenir les données », puis une autre pointe vers une troisième case bleue comportant la mention « Évaluer les données ». De celle-ci, une flèche pointe vers le haut vers la mention « Ne convient pas », où le lecteur est invité à reprendre le processus au cercle jaune. Notez qu'une autre flèche pointe à droite à partir de la case « Évaluer les données ». Au-dessus de cette flèche se trouve la mention « Essayer ». Elle mène le lecteur à une autre case bleue portant la mention « Comprendre les données ». Cette case est dotée d'une flèche pointant vers le haut jusqu'à la case « Ne convient pas » et d'une autre flèche pointant vers la droite jusqu'à la case bleue comportant les mots « Préparer les données ». Cette case bleue comporte également deux flèches – l'une pointant vers le haut jusqu'aux mots « Besoin de plus de données », où le lecteur est redirigé vers le cercle jaune pour recommencer à l'étape 1, et l'autre pointant vers la droite jusqu'à la case « Analyser les données »; de là, une autre flèche pointe à droite vers une case bleu marine comportant les mots « Partager l'analyse ». Ce graphique est censé représenter les essais et les erreurs sans catalogue de données.
Le graphique inférieur illustre le fonctionnement des processus quand on dispose d'un catalogue de données. On y voit un carré de couleur jaune comportant les mots « Catalogue de données ». À partir de cette case, deux flèches pointent vers le bas. L'une mène, à gauche, à une case bleue comportant la mention « Trouver les données » et l'autre, à droite, à une autre case bleue comportant la mention « Évaluer les données ». Les deux boîtes sont également reliées par une flèche allant de gauche à droite. De la case « Évaluer les données », une flèche pointe à droite vers une autre case bleue comportant la mention « Obtenir les données ». Une flèche pointe ensuite vers une autre case bleue comportant la mention « Comprendre les données », et la suivante mène à une autre case comportant les mots « Préparer les données ». À partir de cette boîte, une flèche pointant vers le haut signifie que vous avez besoin de plus de données et que vous devez recommencer à la boîte jaune comportant la mention « Catalogue de données »; si vous suivez la flèche pointant vers la droite, elle vous mène à la case bleue comportant les mots « Analyser les données ». Celle-ci comporte une flèche menant à la case bleu marine « Partager l'analyse ». Ce graphique illustre la rapidité du processus avec un catalogue de données, son efficacité et la confiance qu'il inspire.
Sans catalogue de données, les analystes recherchent des renseignements en étudiant la documentation antérieure, en collaborant avec des associés et en ayant recours à d'autres ensembles de données reconnaissables. Ce cycle exige une expérimentation et la nécessité « d'étendre et d'améliorer » les données. L'analyste doit ensuite consulter des ensembles de données déjà connus.
Le catalogue de données permet à l'analyste de rechercher des ensembles de données disponibles, d'évaluer les données et de prendre des décisions éclairées quant aux renseignements à utiliser. Il peut ensuite examiner et planifier l'information de manière efficace et avec plus de certitude.Note de bas de page 4 Le réseau de stockage et de distribution de données CKAN (le nom est derivé d'acronym du « Comprehensive Knowledge Archive Network ») a été créé pour soutenir ce processus.
Qu'est-ce que le CKAN?
CKAN - The world's leading open source data management system (le contenu de cette page est en anglais) est un système de gestion de données à code source ouvert destiné aux éditeurs de données nationaux et régionaux, aux gouvernements et aux organisations qui souhaitent publier des données, les faire connaître et les rendre ouvertes et accessibles à l'utilisation.
Pourquoi utiliser CKAN?
- Il s'agit d'un logiciel libre et gratuit, ce qui signifie que les utilisateurs conservent tous les droits sur les données et les métadonnées qu'ils stockent dans le logiciel.
- Le logiciel est encodé avec Python et JavaScript. Le code JavaScript, dans CKAN, est décomposé en modules, c'est-à-dire en petites unités indépendantes de code JavaScript. Dans les thèmes CKAN, on peut ajouter des fonctionnalités JavaScript en y intégrant ses propres modules. De cette façon, le code demeure simple et facile à tester, à déboguer et à maintenir, puisqu'il est décomposé en petits modules indépendants. Les développeurs sont autorisés à ajouter des extensions, c'est‑à‑dire des paquets en Python qui modifient ou étendent CKAN. Chaque extension contient un ou plusieurs modules d'extension qui doivent être ajoutés au fichier de configuration CKAN de l'utilisateur pour activer les fonctionnalités de l'extension.
- La gestion des utilisateurs et des données est ainsi assurée.
- De cette façon, on peut développer des extensions personnalisées.
- On y trouve également un point de terminaison de l'interface de programmation d'application (IPA), qui sert à stocker, à modifier, à extraire et à analyser les données.
Cas d'utilisation des métadonnées
À la fin de 2019, l'équipe Opérationnalisation de la science des données de Statistique Canada a commencé à utiliser le Programme intégré de la statistique des entreprises (PISE) de l'organisme. Le PISE est le système commun de traitement des données utilisé pour la plupart des enquêtes économiques de Statistique Canada.
L'objectif du projet est de vaincre les limites de l'espace analytique actuel. Une nouvelle solution permettra :
- de répondre au besoin d'une solution analytique en libre-service;
- d'accroître la capacité de connexion aux outils d'analyse;
- d'accroître la capacité de recherche et de découverte dans des ensembles de données;
- d'éviter la duplication des données;
- d'avoir moins recours à des modes d'accès uniformisés;
- d'utiliser l'analyse horizontale à partir de données extérieures au PISE.
Le PISE et la Division de la science des données se sont associés à l'infrastructure de données FAIR (IDF) pour déterminer si un prototype pouvait être créé à l'aide d'outils à code source ouvert.
L'IDF vise à produire un écosystème collaboratif de données et de métadonnées pour tous les fournisseurs et utilisateurs de données. Au cœur de cet espace figurent un catalogue de données, de même que des outils de gestion des données et des métadonnées.
Transfert de connaissances des analystes à l'administrateur avant la mise en place d'un système infonuagique
Le PISE dispose d'analystes qui souhaitent accéder aux enquêtes. Ces enquêtes sont gérées et mises à jour par un administrateur de l'équipe du PISE; cependant, le processus de mise à jour et de création d'accès entraîne des duplications et des redondances de données. De plus, les analystes ont du mal à faire des recherches parmi ces données et les métadonnées correspondantes, car elles sont disponibles dans des répertoires partagés.
Figure 2 : Goulot d'étranglement dans la validation de concept du PISE

Figure 2 : Goulot d'étranglement dans la validation de concept du PISE)
Il s'agit du processus de transfert des connaissances des analystes à l'administrateur avant l'établissement d'un système infonuagique. La figure montre d'abord une ampoule électrique, dans le coin supérieur gauche, au-dessus de laquelle se trouve le mot « Analyser ». En dessous, on voit trois personnes, qui sont des « analystes ». Une flèche pointe à droite vers l'image suivante dans la chronologie, à savoir un octogone dans lequel figure une icône « Non » au-dessus de laquelle se trouve le mot « Découvrabilité? ». De là, une flèche pointe à droite vers une icône avec des cercles superposés, ce qui signifie que les données sont en cours d'organisation. À droite, une flèche pointe également vers cette icône depuis l'icône d'administration. On voit plusieurs icônes de page sous l'icône de l'administrateur; sous celles-ci se trouvent les mots « Articles en double ».Transfert de connaissances des analystes à l'administrateur après la mise en place d'un système infonuagique
L'équipe a proposé une solution en trois points pour remédier au goulot d'étranglement :
- Le service de recherche de l'IDF : L'équipe de l'IDF a facilité l'enregistrement et la découverte des métadonnées grâce à une couche de virtualisation des donnéesNote de bas de page 5 Le moteur de recherche figure au-dessus d'Elastic Search et il y a des points de terminaison IPA qui permettent aux utilisateurs externes et internes de gérer leur actif en données.
- CKAN
- Le locataire de la plateforme Azure
Le PISE télécharge les données et les métadonnées dans CKAN et le service de recherche de l'IDF. Cela permet aux analystes de rechercher les données et les métadonnées et d'y avoir accès. Les deux systèmes sont synchronisés avec le locataire de la plateforme Azure pour gérer l'authentification des utilisateurs et le stockage des données.
Figure 3 : Solution présentée pour la validation de concept du PISE

Figure 3 : Solution présentée pour la validation de concept du PISE
Cette image illustre le processus de transfert de connaissances des analystes vers l'administrateur après l'établissement d'un système infonuagique. La figure montre d'abord une ampoule électrique, dans le coin supérieur gauche, au-dessus de laquelle se trouve le mot « Analyser ». Sous l'ampoule, on voit trois personnes et sous celles-ci, le mot « Analyste ». Deux flèches pointent à droite, vers une case au centre de l'image, au-dessus de laquelle se trouve le mot « Nuage ». Une des flèches partant de l'icône « Analyste » pointe vers l'icône « Moniteur », située au-dessus de la case « Nuage »; à proximité, on peut voir ce qui suit : « IDF : Service de recherche/Référentiel de métadonnées ». L'autre flèche pointe vers l'icône « CKAN », sous l'icône « Moniteur ». Sur le côté droit de la figure 3, on voit une icône représentant une seule personne; le mot « Admin » s'affiche sous celle-ci. À partir de cette icône, deux flèches pointent à gauche – la première revient à l'icône « Moniteur », tandis que l'autre va vers l'icône « CKAN ». On voit les deux postes travaillant dans le nuage, ce qui règle le problème du goulot d'étranglement illustré à la figure 3.Une solution de gestion des métadonnées
Pour être réussie, la mise en œuvre d'une solution de gestion des métadonnées doit comprendre : une stratégie en matière de métadonnées; l'intégration et la publication des métadonnées; la saisie et le stockage des métadonnées; ainsi que la gouvernance et la gestion des métadonnées. La stratégie de métadonnées garantit la cohérence de l'ensemble de l'écosystème de données d'une organisation. Elle explique pourquoi l'entreprise assure le suivi des métadonnées et recherche toutes les sources de métadonnées, de même que les méthodes qu'elle utilise. Une telle stratégie peut se révéler très complexe sur le plan du volume et des variations des données, de même que sur le plan des capacités technologiques de l'entreprise qui l'appuient. Le graphique ci-dessous donne un aperçu très général de la manière dont une telle stratégie peut être mise en œuvre.
Figure 4 : Infrastructure de métadonnées
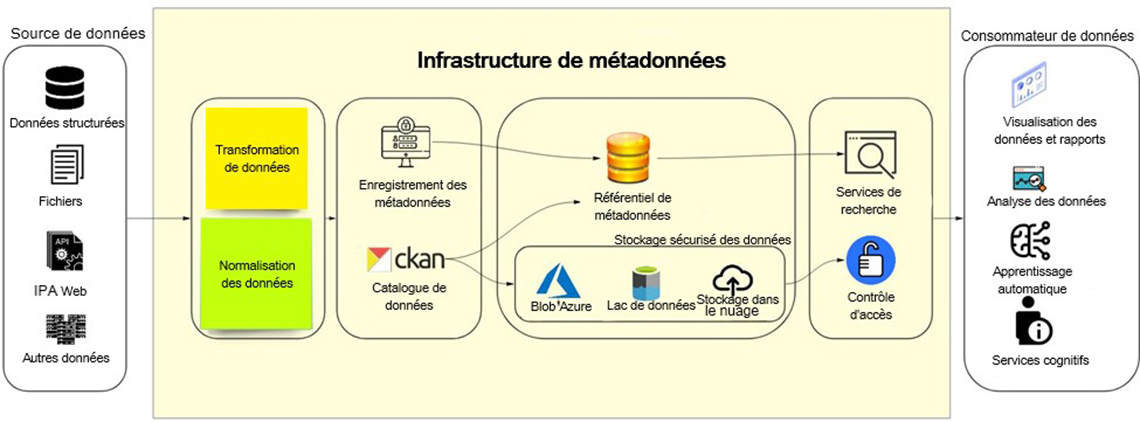
Figure 4 : Infrastructure de métadonnées
Le graphique présente un projet de mise en œuvre d'une infrastructure de métadonnées, dans laquelle les données sont généralement acheminées de leurs sources (de gauche à droite) vers leurs utilisateurs. Au début, on voit un marqueur ovale dont le titre est « Source de données ». On y trouve quatre icônes désignées par une étiquette ou un mot. Chacune des icônes est superposée et accompagnée d'une étiquette ou d'un mot correspondant en dessous. La première icône représente des cercles superposés, illustrant que les fichiers sont organisés. Sous celle-ci se trouve l'étiquette « Données structurées ». La deuxième icône représente deux pages; elle est assortie de l'étiquette « Fichiers ». La troisième icône représente une partie d'engrenage accompagnée de l'acronyme « IPA »; l'étiquette de cette icône est « IPA Web ». La quatrième et dernière icône du marqueur est constituée de trois images côte à côte, chacune comportant un disque de forme carrée; elles sont placées les unes sur les autres, pour illustrer qu'il y a plusieurs sources de données. L'étiquette ou mot situé se trouvant sous cette icône est « Autres données ».
Une flèche pointe de ce marqueur vers un plus grand marqueur de forme carrée intitulé « Infrastructure de métadonnées »; on voit, à l'intérieur de celui-ci, quatre autres marqueurs de forme ovale empilés horizontalement ou juxtaposés dans lesquels se trouvent des paires d'icônes et des étiquettes ou mots joints par des flèches pointant à droite. Le premier marqueur montre deux papillons adhésifs superposés. Le premier est de couleur jaune et porte la mention « Transformation de données ». Le second comporte, sur fond vert, la mention « Normalisation des données ».
Une flèche pointe vers le marqueur suivant, qui contient deux paires d'icônes et d'étiquettes placées les unes au-dessus des autres. La première icône est le bureau d'un ordinateur, contenant une icône de verrou comportant l'image de deux utilisateurs. L'étiquette ou le mot décrivant cette icône est « Enregistrement des métadonnées ». Juste en dessous, la deuxième icône indique « CKAN », avec « Catalogue de données » comme étiquette. Une flèche partant de la première icône va à une icône placée dans un autre marqueur. Elle mène à des cercles dorés superposés représentant des données organisées; l'étiquette en dessous de ceux-ci indique « Référentiel de métadonnées ». De la deuxième icône « CKAN » partent deux flèches pointant vers deux icônes différentes. La première flèche pointe aussi vers l'icône indiquant « Référentiel de métadonnées », et la seconde pointe vers une case intitulée « Stockage sécurisé des données », comme on peut le voir à droite. Dans cette case, il y a trois icônes dont les étiquettes sont placées horizontalement. La première icône est un triangle bleu représentant le « Blob Azure ». La deuxième icône, de forme cylindrique, est colorée en noir et en bleu et est étiquetée « Lac de données ». La dernière icône de ce marqueur représente un nuage avec une flèche pointant vers le haut; elle est intitulée « Stockage dans le nuage ».
Deux flèches en partent. La première va de l'icône « Référentiel de métadonnées » à une autre qui représente un navigateur et une loupe, qui est étiquetée « Services de recherche ». L'autre va de la case « Stockage sécurisé des données » vers une icône comportant un cadenas sur fond bleu, étiquetée « Contrôle d'accès ». Les deux icônes visées sont dans un marqueur séparé et elles sont superposées.
De là, une flèche pointe vers le dernier marqueur de cette image, intitulé « Utilisateur des données ». On y trouve quatre icônes désignées par une étiquette ou un mot. Chacune des icônes est superposée et accompagnée d'une étiquette ou d'un mot. La première icône représente le bureau d'un ordinateur sur lequel se trouvent des graphiques et des analyses. Sous cette icône figure l'étiquette « Visualisation des données et rapports ». La deuxième icône représente un navigateur accompagné d'un graphique et d'une loupe; sous celle-ci se trouvent les mots « Analyse des données ». La troisième icône présente une image partielle d'un cerveau auquel trois fils sont connectés; sous cette icône se figurent les mots « Apprentissage automatique ». La quatrième et dernière icône de ce marqueur présente une figure humaine et la lettre « i ». Sous celle-ci se trouve l'étiquette « Services cognitifs ».
Toute organisation dispose d'une liste de sources de données qui se présentent sous diverses formes, telles que des données structurées, des formats de fichiers plats ou des IPA Web. Ces données sont utilisées par les analystes aux fins de visualisation et d'établissement de rapports, de création d'analyses ou de prestation de services cognitifs. Une stratégie de gestion des métadonnées est essentielle pour garantir que les données sont bien interprétées et sont susceptibles de favoriser l'obtention de résultats.
La première étape de cette gestion est l'absorption des données; en général, cela nécessite un ensemble de transformations et de classifications. En cette matière, l'adoption d'une normalisation des données est un processus clé, car elle permettra d'établir une manière commune de structurer et de comprendre les données, en plus d'inclure les principes et les questions de mise en œuvre pour leur utilisation. L'objectif opérationnel de ce processus permettra également de procéder à une analyse et à un échange collaboratifs avec des partenaires externes.
Grâce à la normalisation, les administrateurs de données devraient être en mesure d'enregistrer l'actif en données et les métadonnées. Ils devraient avoir la possibilité d'absorber et d'enregistrer leurs métadonnées, ce qui rendra leur actif en données découvrable et leur permettra de continuer à gérer leurs données par l'intermédiaire d'une couche de virtualisation. Cela peut être réalisé en introduisant un outil de catalogage des données qui facilitera la mise en place d'une méthode cohérente de repérage des données et des renseignements disponibles pour les partenaires internes et externes de l'organisation.
Grâce à l'emploi de technologies à code source ouvert et d'une infrastructure infonuagique moderne, il est possible de créer une plateforme où ces partenaires peuvent importer des données brutes provenant de diverses sources vers un espace de stockage sécurisé (c'est-à-dire un lac de données ou un stockage en Blob). Plutôt que d'avoir une base de données « sur site » pour l'outil de catalogage des données ou d'enregistrement des métadonnées, comme Postgres ou autre, le stockage dans le nuage est un moyen plus évolutif et plus solide pour appuyer de tels systèmes. Il permettra non seulement de mettre à jour les données, de les synchroniser et de les partager facilement, mais aussi de gérer le contrôle d'accès aux éléments sensibles.
Les services de recherche peuvent être mis en œuvre à la dernière couche de cette stratégie, afin de rendre les données et les métadonnées accessibles aux utilisateurs finaux. Lorsqu'il y a une lacune au chapitre des données, les utilisateurs devraient être autorisés à la signaler, de sorte que les responsables puissent savoir quelles données sont nécessaires pour la combler. Toute la communication entre les composants du graphique peut se faire par l'intermédiaire d'IPA ou de SSH, pour permettre un système d'intégration modulaire.
Enfin, une organisation a besoin d'une structure de gouvernance des métadonnées, qui comprend une évaluation de la responsabilité, des cycles de vie et des statistiques des métadonnées, de même que de leur intégration dans les divers processus opérationnels.

Si vous avez des questions à propos de cet article ou si vous souhaitez en discuter, nous vous invitons à notre nouvelle série de présentations Rencontre avec le scientifique des données où le(s) auteur(s) présenteront ce sujet aux lecteurs et aux membres du RSD.
Mardi, le 21 juin
14h00 à 15h00 p.m. HAE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données. À bientôt !
- Date de modification :