
Pilot project to monitor the hiring progress of 5,000 net new Persons with Disabilities (PWD) in the Public Service
Date: May 2022
Program manager: Director, Human Resources Business Intelligence and Wellness
Director General, Workforce and Workplace Branch
Reference to Personal Information Bank (PIB)
Personal information collected trough the Data Hub pilot project is described in the Treasury Board Secretariat (TBS) Staffing Personal Information Bank (PSE 902) and the Employment Equity and Diversity Personal Information Bank (PSE 918).
The two Personal Information Banks are published on the Statistics Canada website under the latest Information about Programs and Information Holdings chapter.
Description of statistical activity
As part of the Accessibility Strategy for the Public Service of CanadaFootnote 1, the President of the Treasury Board has been mandatedFootnote 2 with ensuring that progress is made to fulfill the Government's commitment to hire 5,000 new public servants with disabilities by 2025. The Treasury Board of Canada Secretariat's Office of Public Service Accessibility (OPSA) is currently monitoring the progress of this hiring objective on an annual basis. The progress reports however have a lag of almost one year due to the fact that each department must process their data and generate their own reports prior to sending them to TBS. While TBS requires data on a more timely basis, reporting more than once annually would impose an undue burden on departments.
In light of Statistics Canada's particular expertise and mandate in the field of data gathering, processing and analysis, the OPSA reached out to the agency to discuss whether an approach could be developed to monitor progress in near real-time. To this end, Statistics Canada has entered into an agreement with the OPSA and is developing, under the authority of the Statistics ActFootnote 3, a disability data hub with the purpose of leveraging the agency's expertise. Statistics Canada will receive the microdata from agencies and departments in a secure environment ensuring that common standards and definitions are used across the public service, and hence ensure data quality. Agencies and departments will only be required to transmit standard databases instead of completed reports, therefore reducing burden. The data will be processed by Statistics Canada to generate reports. This will allow the production of more timely quarterly reports and ensure coherence in the processing rules. (See Appendix 1 – Disability Data Hub).
The Disability Data Hub will reside in Statistics Canada's secured cloud environmentFootnote 4 and is divided into four independent secure environments that each have specific security measures and access controls (See Appendix 2 – Data Flow Chart, and Appendix 3 – Process/Data Flow Sequence).
The environments will allow for the reception, processing, production and transmission of aggregate reports based on four files received from departments (see Appendix 4 for the Record Layout):
- Concordance table (employee Personal Record Identifier (PRI) and employee pseudo-identifier)
- Hire data (department code, employee pseudo-identifier, hire date, hire type & the end date for determinate positions)
- Departure date (department code, employee pseudo-identifier, departure date, departure reason & the hire date)
- Disability Self-ID (department code, employee pseudo-identifier, self-id date, disability type (general category)Footnote 5, self-identification version)
- The first environment is Statistics Canada's Electronic File Transfer Services (EFTS)Footnote 6. Departments will have access to two independent secure EFTS channels to transmit their data files to Statistics Canada. The first EFT secure channel will be used to send the concordance table (file #1), which is the only file that includes a direct identifier (the employee PRI). The second EFT secure channel will be used for the transmission of the three other tables (files #2, #3 and #4), which include only anonymized Human Resources (HR) transactional data for hires, departures, disability self-identification information, and pseudo-identifier. During the file exchange process, the concordance table and the other three sets of files will be transmitted through two independent channels to reduce the risk of potentially re-identifying the information. The concordance tables, that are shared via the first EFT secure channel, will be accessible to fewer than five Statistics Canada methodologists that have a need-to-know, and the other three data files, that are shared via the second EFT secure channel, will be accessible to Statistics Canada's Statistical Data and Metadata eXchange (STC SDMX) team (fewer than five).
- The second environment, which is only accessible by the fewer than five Statistics Canada methodologists, is the secure data processing environment, and is the most critical with regard to data security. The data received in the EFTS environment will be transitioned to this processing environment by way of Statistics Canada's secured internal network to Cloud transfer services. Within this secure environment, the methodologists will re-identify the three data files (#2, 3 & 4 listed above) with the employee PRIs using the concordance tables in order to recreate the professional time line of each hire. This will allow for interdepartmental comparability required to eliminate double counting and ensure data quality. This is done at the initial phase of processing and once completed, the re-identified data sets and the concordance tables will be securely disposed of as they will no longer be needed. Once this is stage is completed, the information transitioning from one environment to another will not include any identifiable information.
- The third environment is a secure internal Statistical Data and Metadata eXchange (SDMX) platformFootnote 7 that will ingest the second set of files, which contain de-identified HR transactional (micro) data for hires, departures and self-IDs. Only the fewer than five Statistics Canada's methodologists and the Statistics Canada SDMX team (also fewer than five) will have access to these data files. This environment will also contain the staging area for the summary statistical reports which will be vetted for confidentiality prior to being released to agencies and departments who will have access only to the summary statistics of their own organisation. The confidentiality vetting seeks to ensure the information cannot be re-identified; for example, aggregate values representing fewer than five employees will not be included in the reports.
- The fourth and final environment is a secure external SDMX platform that will contain the official summary statistical reports which present only aggregate results that will have been vetted for confidentiality to ensure individuals cannot be directly or indirectly identified (see Appendix 1). Each department will have access only to their own anonymized statistical reports, and the OPSA, who is responsible for the reporting of that information, will have access to all anonymized statistical reports. Departments could opt to share their anonymized statistical reports with other departments.
Access to the environments is controlled by file permissions through Statistics Canada's Corporate Access Request System (CARS)Footnote 8 and is granted strictly on a need-to-know basis. For the secure data processing environment, which is only accessible by fewer than five Statistics Canada methodologists, access requests will be sent for approval to the Director General, Modern Statistical Methods and Data Science, or as delegated to the Director, International Cooperation and Methodology Innovation Center. All Statistics Canada employees involved in the production of statistics are aware of their obligation to protect confidentiality and of the legal penalties for wrongful disclosure.
A data hub does not require that all departments use the same Human Resources system to record their data, but it does require that they create files that use a common set of standards and definitions. Given the number of different HR systems that exist within the federal government, a proof of concept will be conducted to assess effort and feasibility of using such an approach.
The proof of concept will be conducted in two phases. The first phase will use Statistics Canada's information only, and will report on the organisation's two different employment workforces (the agency and its Statistical Survey Operations interviewer workforce). Phase two of the proof of concept will test the approach with a limited number of departments and agencies of varying sizes —Public Service Commission (PSC), Canada Revenue Agency (CRA), Innovation, Science and Economic Development (ISED), and Canada Economic Development for Quebec Regions (CED)— to assess their ability to provide the data on a quarterly basis using the uniform standards and definitions proposed by the OPSA.
If the proof of concept is successful, the plan is to implement the approach across all departments to monitor progress until March 31, 2025. As stated above, the concordance tables (file #1) and the re-identified data sets created and contained in the processing environment will be securely disposed of once the secure data processing is completed. The information received through the second independent EFT secure channel (files #2, #3 and #4) would be retained in Statistics Canada's secured cloud environment until December 31, 2027, to ensure the availability of the data for quality control purposes.
Reason for supplement
While the Generic Privacy Impact Assessment Footnote 9 (PIA) addresses most of the privacy and security risks related to statistical activities conducted by Statistics Canada, this supplementary PIA assesses whether this initiative involving particularly sensitive information presents any additional risks, and ensures adequate mitigation measures are in place to protect the privacy of individual information. As is the case with all PIAs, Statistics Canada's privacy framework ensures that elements of privacy protection and privacy controls are documented and applied.
Throughout the development of this Supplementary PIA, Statistics Canada consulted with the OPSA, and an overview of the PIA was presented to the OPSA and partnering organisations (CRA, ISED, PSC and CED).
Necessity and Proportionality
The use of personal information for the Data Hub is justified against Statistics Canada's Necessity and Proportionality Framework:
- Necessity:
The Disability Data Hub will allow the measurement in near real-time of the Government's progress towards its goal of hiring 5,000 net new Persons With Disabilities (PWD) in the Public Service, thus informing departments on their efforts towards:- maximizing available talent and skills
- reflecting a national workforce that better represents and better understands the Canadian population; and,
- supporting the achievement of broader commitments towards a more inclusive and representative government.
- Concordance table (employee Personal Record Identifier (PRI) and employee pseudo-identifier)
- Hire data (department code, employee pseudo-identifier, hire date, hire type & the end date for determinate positions)
- Departure data (department code, employee pseudo-identifier, departure date, departure reason & the hire date)
- Disability Self-ID (department code, employee pseudo-identifier, self-id date, disability type (generic categories), self-identification version)
The pseudo-identifier, while randomly generated by departments, will be consistent across data files within each department. During the processing phase, in the second environment, Statistics Canada will undertake a validation process to ensure this is the case. Because the measurement of net new hires requires that hirings and separations from outside the public service be tracked, an additional processing step ensures that an individual who moves to another department is not counted twice. Given that the PRI is a unique identifier that follows an individual as they move between organisations, a concordance table, transmitted separately through a unique secure EFT channel, is required to link the pseudo-identifier in the data files to the PRI. This file is encrypted when it is sent through the EFTS, ensuring double encryption. The information will be used only for producing statistics. It will not be used for any administrative purposes and will be disposed of as soon as the data processing phase is completed. - Effectiveness:
Following a request from the OPSA, information from the departments who participate in the proof of concept will be transmitted to the data hub for the period between April 1, 2020, and October 31, 2022. Individual records will then be transmitted on a quarterly basis using standard definitions and concepts. This will allow for consistent processing and derivation of the indicators. If the proof of concept is successful, individual records form all departments will then be transmitted on a quarterly basis. - Proportionality:
Data on staffing and self-identification are sensitive. As such, careful consideration was made to ensure that only the minimum information required to generate reports is collected. For example, details on the classification of the position (group and level) are not asked. All the variables required as part of the data hub are obtained from administrative systems to avoid imposing response burden on employees. The record layout of the files is provided in Appendix 4.
Statistics Canada has strict rules to safeguard all its data holdings, and these rules adhere to or exceed the requirements of the Statistics Act, the Privacy Act and relevant federal policies and directives. For example, only aggregates will be presented and counts of fewer than five will be supressed to ensure no possibility of identification or reidentification of individuals.
The benefits of the findings (more accurate and timely reporting of the progress made) will support the desired intent to have a more inclusive workplace in the federal public service and is believed to be proportional to the potential risks to privacy. - Alternatives:
One alternative would be to use the data hub approach, but to receive macro/aggregated data from partnering organizations, hence avoiding the transmission of any sensitive information by the organizations to the data hub. While feasible and allowing for the publication of results, this would require that departments process the data themselves, which could lead to processing inconsistencies and ensuing data quality and integrity issues. A second alternative would be the status quo, but it has shown to result in a lack of a measurable activity and potential insufficiencies in meeting the Government of Canada employment equity objectives.
Mitigation factors
Some information contained in the data hub can be considered sensitive as it relates to disability self-identification. However, the overall risk of harm has been deemed manageable with existing Statistics Canada safeguards that are described in Statistics Canada's Generic Privacy Impact Assessment. These include the encryption of the files transmitted to the data hub through a secured environment, restricted access to the data hub environments based on a permission protocol, and limited access on a need-to-know basis for the processing and validation processes.
Conclusion
This assessment concludes that, with the existing Statistics Canada safeguards and mitigation factors listed above, any remaining risks are such that Statistics Canada is prepared to accept and manage the risk.
Formal approval
This Supplementary Privacy Impact Assessment has been reviewed and recommended for approval by Statistics Canada's Chief Privacy Officer, Director General for Modern Statistical Methods and Data Science, and Assistant Chief Statistician for Corporate Services and Management field.
The Chief Statistician of Canada has the authority for section 10 of the Privacy Act for Statistics Canada, and is responsible for the Agency's operations, including the program area mentioned in this Supplementary Privacy Impact Assessment.
This Privacy Impact Assessment has been approved by the Chief Statistician of Canada.
Appendix 1 – Disability Data Hub
Page 1 (Welcome Page):
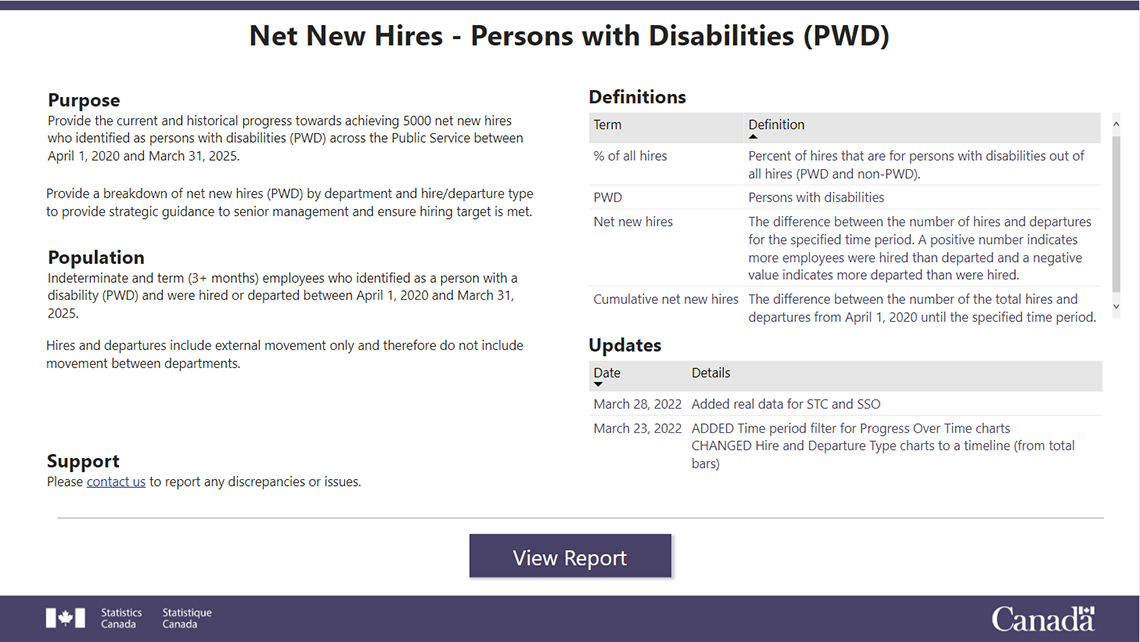
Description: Page 1 (Welcome Page)
Net New Hires – Persons with Disabilities (PWD)
Purpose
Provide the current and historical progress towards achieving 5000 net new hires who identified as persons with disabilities (PWD) across the public service between April 1, 2019 and March 31, 2025.
Provide a breakdown of net new hires (PWD) by department and hire/departure type to provide strategic guidance to senior management and ensure hiring target is met.
Population
Indeterminate and term (3+ months) employees who identified as a person with a disability (PWD) and were hired or departed between April 1, 2020 and March 31, 2025.
Hires and departures include external movement only and therefore do not include movement between departments.
Support
Please contact us to report any discrepancies or issues
| Term | Definition |
|---|---|
| Percentage of all Hires | Percent of hires (PWD) out of all hires (total of PWD and non-PWD) |
| Net new hires | The difference between the number of hires and departures for the specific time period. A positive number indicates more employees were hired than departed and a negative value indicates more departed than were hired. |
| Cumulative net new hires | The difference between the number of the total hires and departures between April 1, 2020 until the specified time period. |
| Date | Details |
|---|---|
| March 28, 2022 | Added real data for STC and SSO |
| March 23, 2022 | Added time period filter for Progress Over Time charts. Changed Hire and Departure Type charts to a timeline (from total bars) |
Page 2 (Aggregate Statistical Reports):
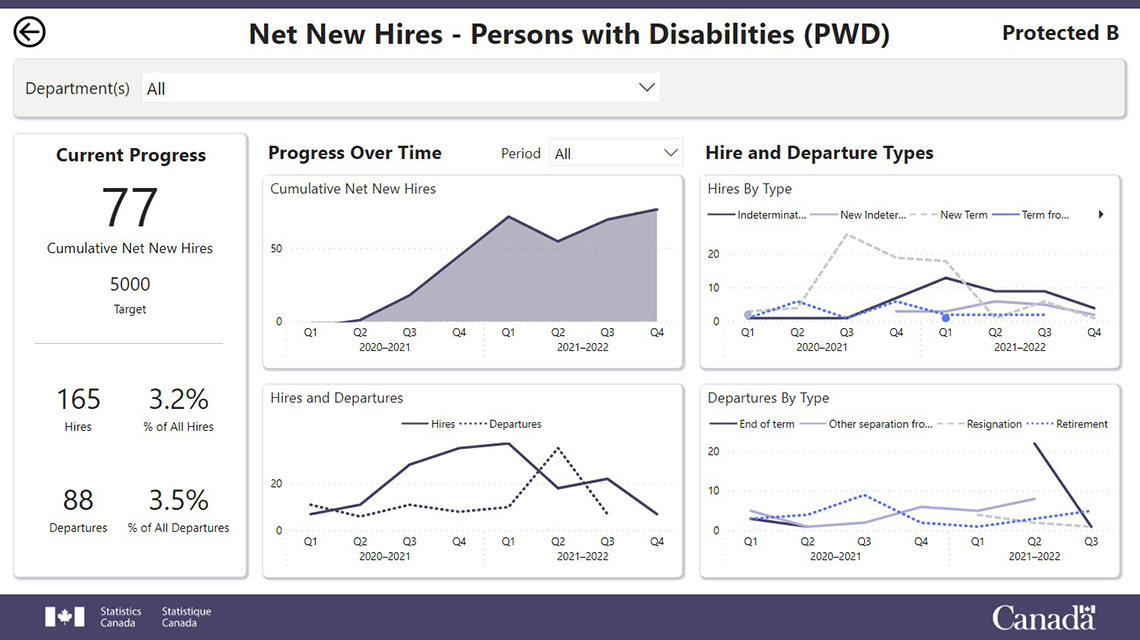
Description: Page 2 (Aggregate Statistical Reports)
Net New Hires – Persons with Disabilities (PWD)
Drop down list to choose Departments.
Current Progress
- 77 Cumulative Net New Hires.
- 5000 target.
- 165 hires represents 3.2% of all hires.
- 88 departures represents 3.5% of all departures.
Progress Over Time
- Cumulative Net New Hires: This chart tracks the cumulative net new hires over time, by quarter and fiscal year.
- Hires and Departures: This line graph charts the number of hires against the number of departures over time, by quarter and fiscal year.
Hire and Departure Types
- Hires by Type. This line graph charts the number of hires by type, including indeterminate, new indeterminate, new term, and term, over time, by quarter and fiscal year
- Departures by Type. This line graph charts the number of departures by type, including end of term, other separation, resignation, and retirement, over time, by quarter and fiscal year.
Appendix 2 – Data Flow Chart
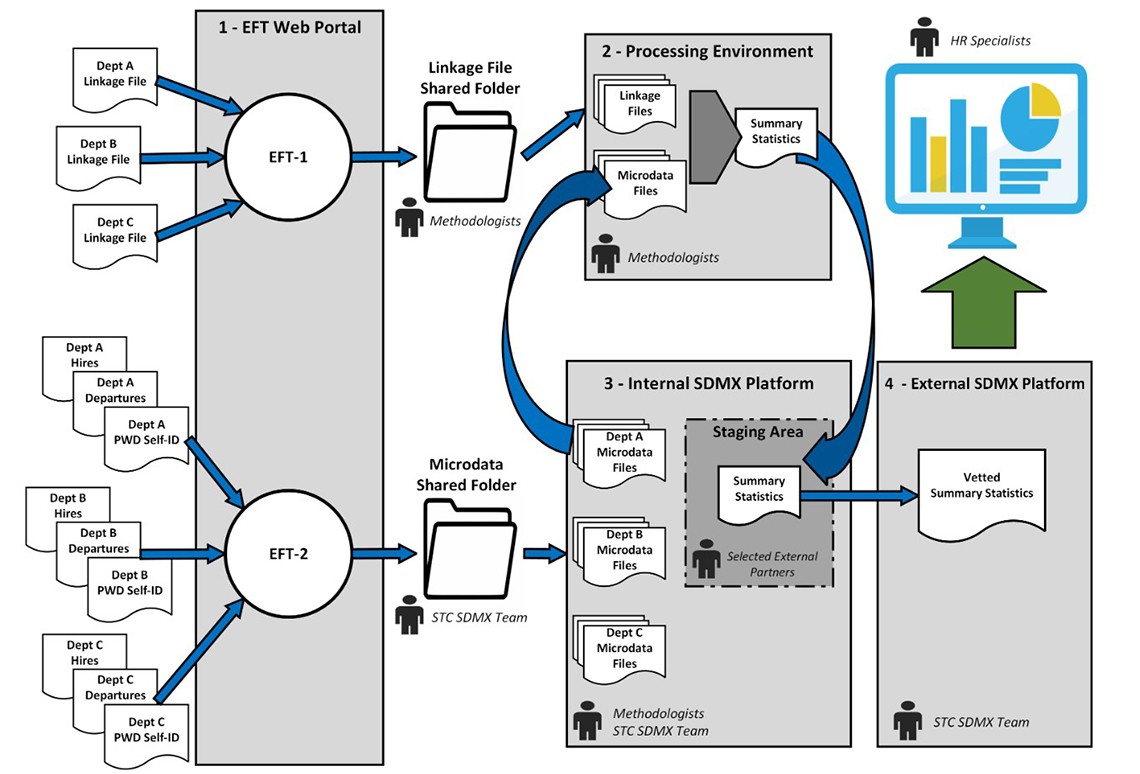
Description: Data Flow Chart
- There are two independent EFT service channels to transmit data files to Statistics Canada. The first environment is Statistics Canada's Electronic File Transfer (EFT) Web Portal #1. This EFT-1 secure channel will be used to send/receive the concordance/linkage table, which is the only file that includes a direct identifier (the employee PRI).
- The EFT-2 secure channel will be used for the transmission of three other tables, which include only anonymized Human Resources (HR) transactional data for hires, departures, disability self-identification information, and a pseudo-identifier.
- The linkage file, received through EFT-1, which is only accessible by five Statistics Canada methodologists, is the secure data processing environment. Within this secure environment, the methodologists will re-identify the three data files with the employee PRIs using the concordance tables in order to recreate the professional time line of each hire.
- The files containing the hire, departure and disability self-identification informations, received through EFT-2, will be secured in the internal Statistical Data and Metadata eXchange (SDMX) platform. The set of files, which contain the de-identified HR transactional data, will be processed by less than five Statistics Canada's methodologists and the Statistics Canada SDMX team. This environment will also contain the staging area for the summary statistical reports which will be vetted for confidentiality by selected external partners.
- The official summary statistical reports, which present only aggregate results that will have been vetted for confidentiality to ensure individuals cannot be directly or indirectly identified will be in the fourth and final environment is a secure external SDMX platform.
- These vetted summary statistics will then be sent to the HR specialists.
Appendix 3 - Process / Data Flow Sequence
- Step 1: Setup 2 different EFTS environments per participating department (EFT-1 & EFT-2).
- Step 2: The clients will generate 2 sets for files, the linkage file (set 1) and data files (set 2).
- Step 3: The clients will logon to the EFTS Web Portal and will submit the linkage file (set 1) to the EFTS-1 environment.
- Step 4: The clients will logon to the EFT Web Portal and will submit the data files (set 2) to the EFTS-2 environment.
- Step 5: The EFTS-2 data files will be validated and loaded onto the secure internal SDMX platform on the cloud main environment. The validation results will be sent back to the clients using the EFTS-2 environment. If the data files contain validation errors, the clients will need to fix the errors, re-generate the data files and re-submit the data files.
- Step 6: Our methodologists will copy the EFTS-1 linkage file to a secure folder, this process should be automated.
- Step 7: Our methodologists will extract the data files from the secure internal SDMX platform and copy them to a secure folder.
- Step 8: Our methodologists will process the data and upload the summary statistics in a secure internal SDMX platform (staging area).
- Step 9: The data will be vetted for release and copied to the secure external SDMX platform using the .STAT Data Lifecycle Manager (DLM).
- Step 10: The PowerBI dashboard will be refreshed against the external SDMX platform and made available to the participating departments.
Appendix 4 - Record Layout
PRI Linkage file
The PRI Linkage file will support the employee record linkage (data matching) task of finding records in the various data sets, it is necessary when joining HR data for employees that have worked in multiple departments.
Example
| DEPT_AGEN | PRI | GEN_ID |
|---|---|---|
| STC | 88 987 789 | z32i6t0 |
| STC | 95 998 782 | jwt66sa |
| STC | 25 985 125 | lvn49sa |
| STC | 35 678 985 | sv472fe |
| STC | 44 566 974 | etw52ed |
CSV example
DEPT_AGEN, PRI, GEN_ID
STC, 88 987 789, z32i6t0
STC, 95 998 782, jwt66sa
STC, 25 985 125, lvn49sa
STC, 35 678 985, sv472fe
STC, 44 566 974, etw52ed
Data Columns
DEPT_AGEN: A reference indicating the reporting department or agency for this dataset.
PRI: A number assigned to uniquely associate a person with their personal records in the federal Public Service. The acronym is PRI. The last digit is a modulus-11 check digit. The PRI is 8 digits long, but is stored in the field previously occupied by the (9 digit) Social Insurance Number.
GEN_ID: A de-identified number assigned to uniquely associate a person. The GEN_ID is generated for every PRI numbers in scope for monitoring the hiring of 5000 persons with disabilities by 2025. The use of the GEN_ID must be comparable between various data files such as hires, departures and self-identification of disabilities.
Validation Rules
- The fields PRI & GEN_ID are mandatory fields and must contain valid values in the files.
- The field PRI must be unique in this data table.
- The field GEN_ID must be unique in this data table.
Naming convention
The file should be named using the following format: NNH-PWD_Linkage_DEPT_YYYY-QQ.csv, where DEPT is replaced by the department the file is originating from, YYYY is replaced by the first four digits of the current fiscal year (for example, fiscal year 2022-2023 would be 2022), and QQ is replaced by latest quarterly information contained in the cumulative file. For example, for Statistics Canada showing the latest information up to the last quarter (Q4) of 2021-22, we would have: NNH-PWD_Linkage_STC_2021-Q4.csv
Hire Data file
| DATAFLOW | FREQ | DEPT_AGEN | GEN_ID | HIRE_TYPE | TIME_PERIOD | OBS_VALUE | END_DATE | NOTE |
|---|---|---|---|---|---|---|---|---|
| STC_HR:DF_HIRE(1.1) | D | STC | z32i6t0 | TERM_NEW | 2021-01-04 | 1 | 2021-07-02 | |
| STC_HR:DF_HIRE(1.1) | D | STC | jwt66sa | S | 2020-08-29 | 1 | 2020-12-31 | |
| STC_HR:DF_HIRE(1.1) | D | STC | lvn49sa | C | 2021-05-03 | 1 | 2021-08-27 | |
| STC_HR:DF_HIRE(1.1) | D | STC | sv472fe | IND_NEW | 2020-12-03 | 1 | ||
| STC_HR:DF_HIRE(1.1) | D | STC | etw52ed | IND_EXT | 2022-01-07 | 1 | ||
| STC_HR:DF_HIRE(1.1) | D | STC | tw583gf | TERM_EXT | 2021-05-27 | 1 | 2021-07-31 |
CSV example
DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,HIRE_TYPE,TIME_PERIOD,OBS_VALUE,END_DATE,NOTE
STC_HR:DF_HIRE(1.1),D,STC, z32i6t0,TERM_NEW,2021-01-04,1,2021-07-02,
STC_HR:DF_HIRE(1.1),D,STC, jwt66sa,S,2020-08-29,1,2020-12-31,
STC_HR:DF_HIRE(1.1),D,STC, lvn49sa,C,2021-05-3,1,2021-08-27,
STC_HR:DF_HIRE(1.1),D,STC, sv472fe,IND_NEW,2020-12-03,1, ,
STC_HR:DF_HIRE(1.1),D,STC, etw52ed,IND_EXT,2022-01-07,1, ,
STC_HR:DF_HIRE(1.1),D,STC, tw583gf,TERM_EXT,2021-05-27,1,2021-07-31,
Data Columns
DATAFLOW: A reference to the dataflow describing the data that needs to be represented. In this case the value "STC_HR:DF_HIRE(1.1)" must be captured within the DATAFLOW column for the dataset representing hires data.
FREQ: A reference indicating the "frequency" of the events in the dataset. It indirectly implies the type of "time reference" and is used to identify the hire event with respect to time. In this case the value "D" for daily must be captured within the FREQ column for this type of data.
DEPT_AGEN: A reference indicating the reporting department or agency for this dataset.
GEN_ID: A de-identified number assigned to uniquely associate a person. The GEN_ID is generated for every PRI numbers in scope for monitoring the hiring of 5000 persons with disabilities by 2025. The use of the GEN_ID must be comparable between various data files such as hires, departures and self-identification of disabilities.
HIRE_TYPE: A reference indicating the type of hire. The value must be coded to the following list of valid codes;
- IND_NEW: New indeterminate
- IND_TERM: Term to indeterminate
- IND_EXT: Indeterminate from other organization
- TERM_NEW: New term
- TERM_EXT: Term from other organization
- C: Casual
- S: Student
- _U: Unknown
TIME_PERIOD: The date for which the employee was hired. The value must comply to the YYYY-MM-DD date format. Has to be the contract hire date.
OBS_VALUE: The value for this field must be "1", the OBS_VALUE must be included to comply with SDMX framework.
END_DATE: This field is optional for indeterminate hires (IND_NEW, IND_TERM, IND_EXT), it represents the end date for determinate hires.
NOTE: This field is optional, comments or notes can be provided to provide contextual information on the hiring event.
Validation Rules
- The fields DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,HIRE_TYPE,TIME_PERIOD,OBS_VALUE are mandatory fields and must contain valid values in the files.
- The DEPT_AGEN, GEN_ID, HIRE_TYPE and TIME_PERIOD fields are the essential characteristics of this table, each row in this table has to have a unique combination of values for those characteristics.
Naming convention
The file should be named using the following format: NNH-PWD_Hires_DEPT_YYYY-QQ.csv, where DEPT is replaced by the department the file is originating from, YYYY is replaced by the first four digits of the current fiscal year (for example, fiscal year 2022-2023 would be 2022), and QQ is replaced by latest quarterly information contained in the cumulative file. For example, for Statistics Canada showing the latest information up to the last quarter (Q4) of 2021-22, we would have: NNH-PWD_Hires_STC_2021-Q4.csv
Departure Data file
| DATAFLOW | FREQ | DEPT_AGEN | GEN_ID | DEPARTURE_TYPE | TIME_PERIOD | OBS_VALUE | HIRE_DATE | NOTE |
|---|---|---|---|---|---|---|---|---|
| STC_HR:DF_ DEPARTURE(1.1) | D | STC | z32i6t0 | RET | 2022-01- 25 | 1 | 1991-05-27 | |
| STC_HR:DF_ DEPARTURE(1.1) | D | STC | jwt66sa | END_TERM | 2021-08- 20 | 1 | 2021-01-04 | |
| STC_HR:DF_ DEPARTURE(1.1) | D | STC | lvn49sa | END_TERM | 2021- 04-30 | 1 | 2021- 01-11 | |
| STC_HR:DF_ DEPARTURE(1.1) | D | STC | sv472fe | RES | 2021-06-13 | 1 | 2020-12-03 | |
| STC_HR:DF_ DEPARTURE(1.1) | D | STC | etw52ed | _O | 2021-07-07 | 1 | 1991-10-08 | |
| STC_HR:DF_ DEPARTURE(1.1) | D | STC | tw583gf | RET | 2021-05-27 | 1 | 1999-12-13 |
CSV example
DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DEPARTURE_TYPE,TIME_PERIOD,OBS_VALUE,HIRE_DATE,NOTE
STC_HR:DF_DEPARTURE(1.1),D,STC, z32i6t0,RET,2022-01-25,1,1991-05-27,
STC_HR:DF_DEPARTURE(1.1),D,STC, jwt66sa,END_TERM,2021-08-20,1,2021-01-04,
STC_HR:DF_DEPARTURE(1.1),D,STC, lvn49sa,END_TERM,2021-04-30,1,2021-01-11,
STC_HR:DF_DEPARTURE(1.1),D,STC, sv472fe,RES,2021-06-13,1,2020-12-03,
STC_HR:DF_DEPARTURE(1.1),D,STC, etw52ed,_O,2021-07-07,1,1991-10-08,
STC_HR:DF_DEPARTURE(1.1),D,STC, tw583gf,RET,2020-10-07,1,1999-12-13,
Data Columns
DATAFLOW: A reference to the dataflow describing the data that needs to be represented. In this case the value "STC_HR:DF_DEPARTURE(1.1)" must be captured within the DATAFLOW column for the dataset representing departures data.
FREQ: A reference indicating the "frequency" of the events in the dataset. It indirectly implies the type of "time reference" and is used to identify the hire event with respect to time. In this case the value "D" for daily must be captured within the FREQ column for this type of data.
DEPT_AGEN: A reference indicating the reporting department or agency for this dataset.
GEN_ID: A de-identified number assigned to uniquely associate a person. The GEN_ID is generated for every PRI numbers in scope for monitoring the hiring of 5000 persons with disabilities by 2025. The use of the GEN_ID must be comparable between various data files such as hires, departures and self-identification of disabilities.
DEPARTURE_TYPE: A reference indicating the type of departure. The value must be coded to the following list of valid codes;
- EXT: Departure to another organization
- END_TERM: End of term
- RES: Resignation
- RET: Retirement
- _O: Other separation from public service
- _U: Unknown
TIME_PERIOD: The date for which the employee has departed. The value must comply to the YYYY-MM-DD date format.
OBS_VALUE: The value for this field must be "1", the OBS_VALUE must be included to comply with SDMX framework.
HIRE_DATE: This field is optional, when available, it represents the start date for which the employee was hired.
NOTE: This field is optional, comments or notes can be provided to provide contextual information on the departure event.
Validation Rules
- The fields DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DEPARTURE_TYPE,TIME_PERIOD,OBS_VALUE are mandatory fields and must contain valid values in the files.
- The DEPT_AGEN, GEN_ID, DEPARTURE_TYPE and TIME_PERIOD fields are the essential characteristics of this table, each row in this table has to have a unique combination of values for those characteristics.
Naming convention
The file should be named using the following format: NNPWD_Departures_DEPT_YYYY-QQ.csv, where DEPT is replaced by the department the file is originating from, YYYY is replaced by the first four digits of the current fiscal year (for example, fiscal year 2022-2023 would be 2022), and QQ is replaced by latest quarterly information contained in the cumulative file. For example, for Statistics Canada showing the latest information up to the last quarter (Q4) of 2021-22, we would have: NNPWD_Departures_STATCAN_2021-Q4.csv
Disability Self-ID Data file
| DATAFLOW | FREQ | DEPT_AGEN | GEN_ID | DISABILITY_TYPE | TIME_PERIOD | OBS_VALUE | SELF_ID_VERSION | NOTE |
|---|---|---|---|---|---|---|---|---|
| STC_HR:DF_ SELF_ID(1.1) | D | STC | z32i6t0 | 99 | 2022-01- 25 | 1 | 1 | |
| STC_HR:DF_ SELF_ID(1.1) | D | STC | jwt66sa | 16 | 2022-01-26 | 1 | 1 | |
| STC_HR:DF_ SELF_ID(1.1) | D | STC | lvn49sa | 12 | 2005-11-15 | 1 | 1 | |
| STC_HR:DF_ SELF_ID(1.1) | D | STC | sv472fe | 19 | 2022-02-15 | 1 | 1 | |
| STC_HR:DF_ SELF_ID(1.1) | D | STC | etw52ed | 99 | 2022-01- 26 | 1 | 1 | |
| STC_HR:DF_ SELF_ID(1.1) | D | STC | tw583gf | 99 | 2018-07-30 | 1 | 1 |
CSV example
DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DISABILITY_TYPE,TIME_PERIOD,OBS_VALUE,SELF_ID_VERSION,NOTE
STC_HR:DF_SELF_ID(1.1),D,STC, z32i6t0,99,2022-01-25,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, jwt66sa,16,2022-01-26,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, lvn49sa,12,2005-11-15,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, sv472fe,19,2022-02-15,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, etw52ed,99,2022-01-26,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, tw583gf,99,2018-07-30,1,1,
Data Columns
DATAFLOW: A reference to the dataflow describing the data that needs to be represented. In this case the value "STC_HR:DF_SELF_ID(1.1)" must be captured within the DATAFLOW column for the dataset representing disability data.
FREQ: A reference indicating the "frequency" of the events in the dataset. It indirectly implies the type of "time reference" and is used to identify the hire event with respect to time. In this case the value "D" for daily must be captured within the FREQ column for this type of data.
DEPT_AGEN: A reference indicating the reporting department or agency for this dataset.
GEN_ID: A de-identified number assigned to uniquely associate a person. The GEN_ID is generated for every PRI numbers in scope for monitoring the hiring of 5000 persons with disabilities by 2025. The use of the GEN_ID must be comparable between various data files such as hires, departures and self-identification of disabilities.
DISABILITY_TYPE: A reference indicating the type of disability. The value must be coded to the following list of valid codes;
- 16: Seeing disability
- 19: Hearing disability
- 13: Speech disability
- 12: Mobility disability
- 11: Challenges with flexibility or dexterity
- 23: Other (version 1)
- 31: Mental health disability
- 32: Sensory or environmental disability
- 33: Chronic health condition or pain
- 34: Cognitive disability
- 35: Intellectual disability
- 99: Other disability (version 2)
- _N: Prefer not to specify
TIME_PERIOD: The date for which the employee has self identified. The value must comply to the YYYY-MM-DD date format.
OBS_VALUE: The value for this field must be "1", the OBS_VALUE must be included to comply with SDMX framework.
SELF_ID_VERSION: This field is optional, when available, it represents the version of the disability questionnaire.
NOTE: This field is optional, comments or notes can be provided to provide contextual information on the self-id event.
Validation Rules
- The fields DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DISABILITY_TYPE,TIME_PERIOD,OBS_VALUE are mandatory fields and must contain valid values in the files.
- The DEPT_AGEN, GEN_ID, DISABILITY_TYPE and TIME_PERIOD fields are the essential characteristics of this table, each row in this table has to have a unique combination of values for those characteristics.
Naming convention
The file should be named using the following format: NNPWD_SelfID_DEPT_YYYY-QQ.csv, where DEPT is replaced by the department the file is originating from, YYYY is replaced by the first four digits of the current fiscal year (for example, fiscal year 2022-2023 would be 2022), and QQ is replaced by latest quarterly information contained in the cumulative file. For example, for Statistics Canada showing the latest information up to the last quarter (Q4) of 2021-22, we would have: NNPWD_ SelfID_STATCAN_2021-Q4.csv