
Suivi des progrès réalisés vers l'embauche de 5 000 nouvelles personnes en situation de handicap (PSH) dans la fonction publique
Date : Mai 2022
Gestionnaire de programme : Directeur, Division des renseignements organisationnels en ressources humaines, du mieux-être et de la transformation
Directeur général, Direction de l'effectif et du milieu de travail
Mention du fichier de renseignements personnels (FRP)
Les renseignements personnels recueillis dans le cadre du projet pilote de carrefour de données sont décrits dans le Fichier de renseignements personnels de dotation (POE 902) et le Fichier de renseignements personnels ordinaire Équité en emploi et diversité (POE 918) du Secrétariat du Conseil du Trésor (SCT).
Les deux fichiers de renseignements personnels sont publiés sur le site Web de Statistique Canada sous la plus récente publication des Renseignements sur les programmes et les fonds de renseignements.
Description de l'activité statistique
Dans le cadre de la Stratégie sur l'accessibilité au sein de la fonction publique du CanadaNote de bas de page 1, le président du Conseil du Trésor a reçu le mandatNote de bas de page 2 de veiller à ce que des progrès soient réalisés pour respecter l'engagement du gouvernement visant l'embauche de 5 000 personnes en situation de handicap dans la fonction publique d'ici 2025. Le Bureau de l'accessibilité au sein de la fonction publique (BAFP) du Secrétariat du Conseil du Trésor du Canada effectue actuellement un suivi annuel des progrès réalisés pour respecter cet objectif d'embauche. Toutefois, les rapports sur l'état d'avancement accusent un retard de près d'un an parce que chaque ministère et organisme doit traiter ses données et produire ses propres rapports avant de les transmettre au SCT. Bien que le SCT exige une diffusion plus rapide des données, la production de rapports plus d'une fois par année imposerait un fardeau indu aux ministères et organismes.
En raison de l'expertise et du mandat particuliers de Statistique Canada dans le domaine de la collecte, du traitement et de l'analyse des données, le BAFP a communiqué avec l'organisme afin de discuter de la possibilité d'élaborer une approche visant à assurer le suivi des progrès presque en temps réel. À cette fin, Statistique Canada a conclu une entente avec le BAFP au titre de la Loi sur la statistiqueNote de bas de page 3 pour la création d'un carrefour de données dans le but de tirer parti de l'expertise de l'organisme. Statistique Canada recevra les microdonnées des organismes et des ministères dans un environnement protégé en veillant à l'application de normes et de définitions normalisées dans l'ensemble de la fonction publique afin d'assurer la qualité des données. Il suffira aux organismes et aux ministères de transmettre des bases de données normalisées plutôt que des rapports remplis, ce qui réduira le fardeau qui leur ait imposé. Ces données seront traitées par Statistique Canada afin de produire les rapports. Cela permettra de produire plus rapidement les rapports trimestriels et d'assurer la cohérence des règles de traitement. (Voir l'annexe 1 – Disability Data Hub).
Le carrefour de données sera hébergé dans l'environnement infonuagique protégéNote de bas de page 4 de Statistique Canada et sera divisé en quatre environnements protégés indépendants qui comportent chacun des mesures de sécurité et des contrôles d'accès particuliers (voir l'annexe 2 – Diagramme du flux de données et l'annexe 3 – Processus / Séquence du flux de données).
Les environnements permettront la réception, le traitement, la production et la transmission de rapports agrégés fondés sur quatre fichiers reçus des ministères et organismes (voir le cliché d'enregistrement à l'annexe 4) :
- Table de concordance (code d'identification de dossier personnel [CIDP] et pseudo-identifiant de l'employé)
- Données d'embauche (code du ministère ou de l'organisme, pseudo-identifiant de l'employé, date d'embauche, type d'embauche et date de fin des postes à durée déterminée)
- Données sur le départ (code du ministère ou de l'organisme, pseudo-identifiant de l'employé, date de départ, raison de départ et date d'embauche)
- Auto-identification des handicaps (code du ministère ou de l'organisme, pseudo-identifiant de l'employé, date de l'auto-identification, type de handicap [catégories génériques]Note de bas de page 5, version d'auto-identification)
- Le premier environnement est le Service de transfert électronique de fichiers (STEF)Note de bas de page 6 de Statistique Canada. Les ministères et organismes auront accès à deux canaux protégés indépendants du STEF permettant la transmission de fichiers de données à Statistique Canada. Le premier canal protégé du STEF servira à transmettre la table de concordance (fichier no 1), le seul fichier qui contient un identificateur direct (le CIDP de l'employé). Le deuxième canal protégé du STEF servira à transmettre les trois autres tables (les fichiers no 2, 3 et 4), qui comprennent uniquement des données transactionnelles anonymisées des Ressources humaines (RH) pour les embauches, les départs, les renseignements d'auto-identification des personnes en situation de handicap et le pseudo-identifiant. Au cours du processus d'échange de fichiers, la table de concordance et les trois autres ensembles de fichiers seront transmis par deux canaux indépendants afin de réduire le risque de réidentification des renseignements. Moins de cinq méthodologistes de Statistique Canada auront accès aux tables de concordance partagées au moyen du premier canal protégé du STEF selon le principe du besoin de savoir. Les trois autres fichiers de données partagés au moyen du deuxième canal protégé du STEF seront accessibles à l'équipe SDMX (échange de données et de métadonnées statistiques) de Statistique Canada (moins de cinq personnes).
- Le deuxième environnement est l'environnement protégé de traitement des données, auquel ont accès moins de cinq méthodologistes de Statistique Canada. Il est le plus important en ce qui concerne la sécurité des données. Les données reçues dans l'environnement du STEF seront transférées à cet environnement de traitement au moyen du réseau interne protégé de Statistique Canada vers les services de transfert infonuagiques. Dans cet environnement protégé, les méthodologistes procéderont à la réidentification des trois fichiers de données (nos 2, 3 et 4 ci-dessus) au moyen des CIDP des employés dans les tables de concordance afin de recréer l'historique professionnel de chaque embauche. Cela permettra la comparabilité interministérielle requise pour éliminer la double comptabilisation et assurer la qualité des données. La réidentification se fait à la phase initiale du traitement et, une fois terminée, les ensembles de données et les tables de concordance réidentifiées seront éliminés de façon sécuritaire, car ils ne seront plus nécessaires. Une fois cette étape terminée, l'information transférée d'un environnement à un autre ne comprendra plus de renseignements qui permettraient d'identifier des personnes.
- Le troisième environnement est une plateforme SDMXNote de bas de page 7 interne qui intégrera le deuxième ensemble de fichiers contenant des microdonnées de transactions des RH anonymisées concernant les embauches, les départs et les autodéclarations. Seuls les cinq méthodologistes ou moins de Statistique Canada et les membres de l'équipe SDMX de Statistique Canada, également moins de cinq, auront accès à ces fichiers de données. Cet environnement contiendra également la zone de transit pour les rapports statistiques sommaires, qui seront vérifiés aux fins de confidentialité avant d'être diffusés aux organismes et ministères qui n'auront accès qu'aux statistiques sommaires concernant leur propre organisation. Le contrôle de confidentialité vise à s'assurer que les renseignements ne permettent pas la réidentification; par exemple, les valeurs agrégées représentant moins de cinq employés seront exclues des rapports.
- Le quatrième et dernier environnement est une plateforme SDMX externe protégée qui contiendra les rapports statistiques sommaires officiels qui ne présentent que des résultats agrégés qui auront été vérifiés aux fins de confidentialité pour veiller à ce que les personnes ne puissent pas être identifiées directement ou indirectement (voir l'annexe 1). Chaque ministère et organisme n'aura accès qu'à ses propres rapports statistiques anonymisés, et le BAFP, qui est responsable de la déclaration de ces renseignements, aura accès à tous les rapports statistiques anonymisés. Les ministères ou organismes pourront choisir de partager leurs rapports statistiques anonymisés avec d'autres ministères ou organismes.
L'accès aux environnements est contrôlé par des autorisations d'accès aux fichiers par l'intermédiaire du Système de demande d'accès de l'organisme (SDAO)Note de bas de page 8 de Statistique Canada, et est accordé strictement selon le principe du besoin de savoir. Pour l'environnement protégé de traitement des données, qui n'est accessible qu'à moins de cinq méthodologistes de Statistique Canada, les demandes d'accès seront envoyées pour approbation au directeur général de la Direction des méthodes statistiques modernes et de la science des données, ou déléguées au directeur du Centre de coopération internationale et d'innovation en méthodologie. Tous les employés de Statistique Canada qui participent à la production de statistiques connaissent leur obligation de protéger la confidentialité et les sanctions juridiques s'appliquant à la divulgation illicite de renseignements.
Si un carrefour de données n'exige pas que tous les ministères et organismes utilisent le même système de gestion des ressources humaines pour consigner leurs données, il exige cependant qu'ils créent des fichiers utilisant un ensemble commun de normes et de définitions. Compte tenu du nombre de systèmes de gestion des RH différents qui existent au sein du gouvernement fédéral, l'approche fera l'objet d'une validation du concept pour évaluer sa faisabilité et le niveau d'effort nécessaire.
La validation du concept se déroulera en deux phases. La première phase utilisera les renseignements concernant Statistique Canada seulement et portera sur deux effectifs différents au sein de l'organisme, soit le personnel de l'ensemble de l'organisme et le personnel d'intervieweurs des Opérations des enquêtes statistiques). La deuxième phase de validation du concept mettra à l'essai l'approche auprès d'un nombre limité de ministères et d'organismes de tailles variables : la Commission de la fonction publique (CFP), l'Agence du revenu du Canada (ARC), Innovation, Sciences et Développement économique Canada (ISDE) et Développement économique Canada (DEC) pour les régions du Québec, afin d'évaluer leur capacité de fournir les données sur une base trimestrielle en utilisant les normes et les définitions normalisées proposées par le BAFP.
Si le concept est validé, le plan consiste à mettre en œuvre l'approche dans tous les ministères et organismes pour faire le suivi des progrès réalisés jusqu'au 31 mars 2025. Comme il est indiqué ci-dessus, les tables de concordance (fichier no 1) et les ensembles de données réidentifiés créés et contenus dans l'environnement de traitement seront éliminés de façon sécuritaire une fois achevé le traitement protégé des données. Les renseignements reçus par l'intermédiaire du deuxième canal protégé du STEF (fichiers no 2, 3 et 4) seraient conservés dans l'environnement infonuagique protégé de Statistique Canada jusqu'au 31 décembre 2027 afin d'assurer la disponibilité des données à des fins de contrôle de la qualité.
Raison du supplément
Bien que l'Évaluation générique des facteurs relatifs à la vie privée Note de bas de page 9 (EFVP) traite de la plupart des risques pour la protection des renseignements personnels et la sécurité liés aux activités statistiques menées par Statistique Canada, le présent supplément est réalisé afin d'évaluer si l'initiative qui porte sur des données de nature délicate présente d'autres risques, et veille à ce que des mesures d'atténuation adéquates soient en place pour protéger la confidentialité des renseignements personnels. Comme c'est le cas avec toutes les EFVP, le cadre de protection des renseignements personnels de Statistique Canada garantit que les éléments de protection de la vie privée et de contrôle de la vie privée sont consignés et appliqués.
Tout au long de l'élaboration de cette ÉFVP supplémentaire, Statistique Canada a consulté le BAFP, et un aperçu de l'EFVP a été présenté au BAFP et aux organismes partenaires (ARC, ISDE, CFP et DEC).
Nécessité et proportionnalité
L'utilisation de renseignements personnels pour le carrefour de données peut être justifiée par le Cadre de nécessité et de proportionnalité de Statistique Canada :
- Nécessité : Le carrefour de données permettra de mesurer presque en temps réel les progrès réalisés par le gouvernement en vue d'atteindre son objectif d'embaucher 5 000 personnes en situation de handicap dans la fonction publique, ce qui permettra d'orienter les efforts des ministères et organismes pour :
- maximiser les talents et les compétences disponibles;
- mettre en place un effectif national qui représente mieux et comprend mieux la population canadienne;
- appuyer la concrétisation d'engagements plus vastes visant à établir un gouvernement plus inclusif et plus représentatif.
- Table de concordance (code d'identification de dossier personnel [CIDP] et pseudo-identifiant de l'employé)
- Données d'embauche (code du ministère ou de l'organisme, pseudo-identifiant de l'employé, date d'embauche, type d'embauche et date de fin des postes à durée déterminée)
- Date sur le départ (code du ministère ou de l'organisme, pseudo-identifiant de l'employé, date de départ, raison de départ et date d'embauche)
- Auto-identification des handicaps (code du ministère ou de l'organisme, pseudo-identifiant de l'employé, date de l'auto-identification, type de handicap [catégories génériques], version d'auto-identification)
Le pseudo-identifiant, bien qu'il soit généré au hasard par les ministères et organismes, sera uniforme dans tous les fichiers de données de chaque ministère et organisme. Au cours de la phase de traitement dans le deuxième environnement, Statistique Canada entreprendra un processus de validation pour s'assurer que le pseudo-identifiant est bel et bien uniforme. Étant donné que la mesure des nouvelles embauches nettes exige le suivi des embauches et départs à l'extérieur de la fonction publique, une étape de traitement supplémentaire veille à ce qu'une personne qui change de ministère ou d'organisme ne soit pas comptabilisée deux fois. Étant donné que le CIDP est un identificateur unique qui suit la personne lorsqu'elle passe d'une organisation à l'autre, une table de concordance transmise séparément au moyen d'un canal protégé unique du STEF est nécessaire pour coupler le pseudo-identifiant dans les fichiers de données au CIDP. Ce fichier est chiffré lorsqu'il est envoyé par le STEF, ce qui assure un double cryptage. Les renseignements serviront uniquement à produire des statistiques. Ils ne serviront pas à des fins administratives et seront éliminés dès que la phase de traitement des données sera terminée. - Efficacité : À la suite d'une demande présentée par le BAFP, les renseignements des ministères ou organismes qui participent à la validation du concept seront transmis au carrefour de données pour la période allant du 1er avril 2020 au 31 octobre 2022. Les enregistrements individuels seront ensuite transmis chaque trimestre à l'aide de définitions et de concepts normalisés. Cela permettra un traitement et une dérivation cohérents des indicateurs. Si la validation du concept est réussie, les dossiers individuels de tous les ministères et organismes seront transmis chaque trimestre.
- Proportionnalité : Les données sur la dotation et l'auto-identification sont de nature délicate. Ainsi, une attention particulière a été portée au fait de ne recueillir que le minimum de renseignements nécessaires à la production de rapports. Par exemple, les détails sur la classification du poste (groupe et niveau) ne sont pas demandés. Toutes les variables requises pour la consignation dans le carrefour de données proviennent des systèmes administratifs afin d'éviter d'imposer un fardeau de réponse aux employés. Le cliché d'enregistrement des fichiers se trouve à l'annexe 4.
Statistique Canada met en œuvre des règles strictes pour protéger l'ensemble de ses fonds de données, et ses règles respectent ou surpassent les exigences de la Loi sur la statistique, de la Loi sur la protection des renseignements personnels ainsi que des politiques et des directives fédérales connexes. Par exemple, seuls les agrégats seront présentés et les dénombrements de moins de cinq personnes seront supprimés afin d'éviter toute possibilité d'identification ou de réidentification des personnes.
Les avantages des résultats obtenus, c'est-à-dire des rapports plus précis et en temps opportuns sur les progrès réalisés, appuieront l'intention souhaitée d'établir un milieu de travail plus inclusif dans la fonction publique fédérale, et sont jugés proportionnels aux risques pour la vie privée. - Solutions de rechange : Une solution de rechange serait d'utiliser l'approche du carrefour de données, mais d'opter pour la transmission de macrodonnées ou de données agrégées par les organismes partenaires et ainsi éviter la transmission de renseignements de nature délicate au carrefour de données. Bien que cette solution soit réalisable et permette la publication des résultats, elle exigerait que les ministères ou organismes procèdent eux-mêmes au traitement des données, ce qui pourrait entraîner des incohérences dans le traitement et des problèmes liés à la qualité et à l'intégrité des données. Une deuxième possibilité serait le statu quo, mais il s'est avéré qu'il en résulte un manque d'activité mesurable et des insuffisances potentielles dans la réalisation des objectifs d'équité en matière d'emploi du gouvernement du Canada.
Facteurs d'atténuation
Certains renseignements contenus dans le carrefour de données peuvent être considérés comme étant de nature délicate en ce qui a trait à l'auto-identification des personnes en situation de handicap. Toutefois, le risque global de préjudice a été jugé gérable avec les mesures de protection existantes de Statistique Canada qui sont décrites dans l'Évaluation générique des facteurs relatifs à la vie privée de Statistique Canada. Il s'agit notamment du chiffrement des fichiers transmis au carrefour de données dans un environnement sécurisé, d'un accès restreint aux environnements du carrefour de données en fonction d'un protocole d'autorisation et d'un accès limité en fonction du principe du besoin de savoir pour les processus de traitement et de validation.
Conclusion
Cette évaluation conclut que, grâce aux mesures de protection existantes de Statistique Canada et aux facteurs d'atténuation décrits ci-dessus, les risques résiduels sont tels que Statistique Canada est disposé à accepter et à gérer le risque.
Approbation officielle
Le présent supplément à l'Évaluation des facteurs relatifs à la vie privée a été examiné et recommandé aux fins d'approbation par le dirigeant principal de la protection des renseignements personnels, le directeur général de la Direction des méthodes statistiques modernes et de la science des données, ainsi que la statisticienne en chef adjointe du Secteur de la statistique sociale, de la santé et du travail de Statistique Canada.
Le statisticien en chef du Canada exerce les pouvoirs délégués en vertu de l'article 10 de la Loi sur la protection des renseignements personnels pour Statistique Canada, et est responsable des opérations de l'organisme, y compris du secteur de programme cité dans ce supplément à l'Évaluation des facteurs relatifs à la vie privée.
Le statisticien en chef du Canada a approuvé L'Évaluation des facteurs relatifs à la vie privée.
Annexe 1 – Carrefour de données sur l'incapacité
Page 1 (page d'accueil) :

Description : Page 1 (page d'accueil)
Nouvelles embauches nettes – Personnes en situation d'handicap (PSH)
But
Fournir le progrès actuel et historique vers l'accomplissement de 5 000 nouveaux employés qui se sont identifiés comme personnes en situation d'handicap (PSH) à travers la fonction publique entre le premier avril 2020 et le 31 mars 2025.
Population
Les employés indéterminés et termes (plus de 3 mois) qui se sont identifiés comme personnes en situation d'handicap (PSH) et ont été embauchés ou ont quittés entre le premier avril 2020 et le 31 mars 2025. Les embauches et départs incluent les mouvements externes seulement et par conséquent n'incluent pas les mouvements entre les ministères.
Support
Veuillez nous contacter pour signaler des erreurs ou problèmes
| Terminologie | Définition |
|---|---|
| Pourcentage de toutes les embauches | Pourcentage d'embauches reliées aux personnes en situation d'handicap, parmi l'ensemble des embauches (PSH et non-PSH) |
| Nouvelles embauches nettes | La différence entre le nombre d'embauches et de départs au cours d'une période spécifique. Un nombre positif indique qu'il y a eu plus d'embauches que de départs d'employés, et une valeur négative indique qu'il y a eu plus de départs que d'embauches |
| Nouvelles embauches nettes cumulatives | La différence entre le nombre total d'embauches et départs du 1er avril 2020 jusqu'à la période spécifiée |
| PSH | Personnes en situation d'handicap |
| Date | Détail |
|---|---|
| 28 mars 2022 | Ajouté données reliées pour STC et SSO |
| 23 mars 2022 | Ajouté filtre pour la période de temps pour les graphiques présentant le progrès chronologique. Changé le type de graphique pour les types d'embauches et de départs à un graphique chronologique (auparavant des barres totales) |
Page 2 (Rapports statistiques agrégés) :
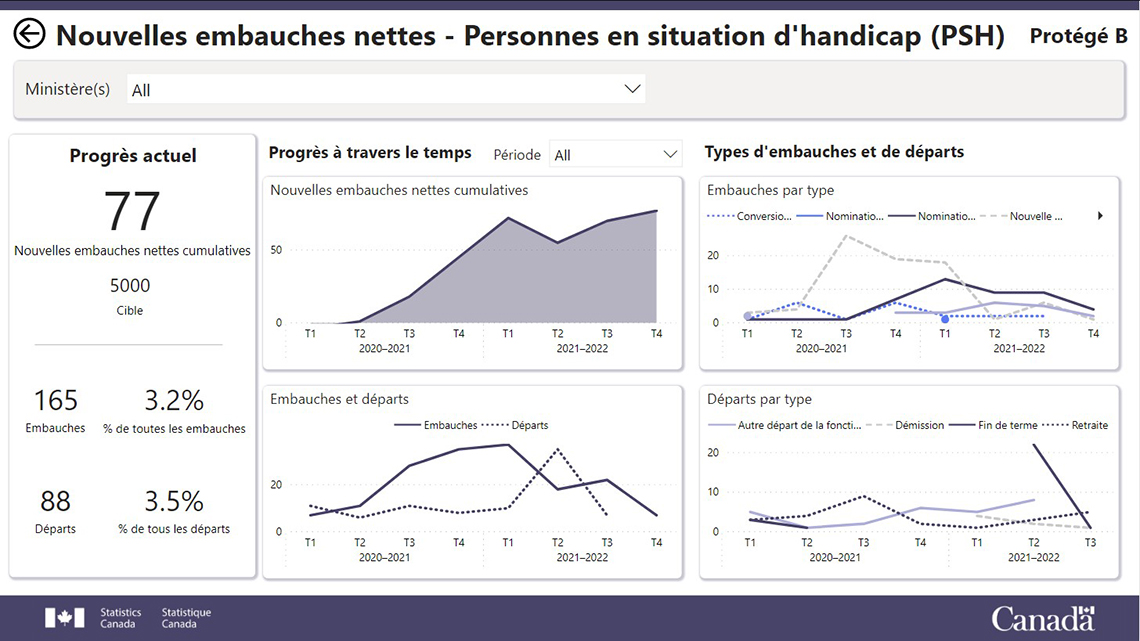
Description : Page 2 (Rapports statistiques agrégés)
Nouvelles embauches nettes – Personnes en situation d'handicap (PSH)
Liste défilante pour choisir les ministères.
Progrès actuel
- 77 nouvelles embauches nettes cumulatives
- Cible de 5000
- 165 embauches représentant 3.2% de toutes les embauches.
- 88 départs représentant 3.5% de toutes les embauches.
Progrès à travers le temps
- Nouvelles embauches nettes cumulatives: Ce graphique démontre les nouvelles embauches nettes cumulatives dans le temps, par trimestre et exercice financier.
- Embauches et départs: Ce graphique linéaire démontre le nombre d'embauche ainsi que les nombre de départs dans le temps, par trimestre et exercice financier.
Type d'embauches et de départs
- Types d'embauche: Ce graphique linéaire démontre le nombre d'embauches par type, soit les indéterminés, les nouveaux indéterminés, les déterminés et les nouveaux déterminés dans le temps, par trimestre et exercice financier.
- Types de départs: Ce graphique linéaire démontre le nombre de départs par type, soit la fin des déterminés, autre départ, démission et retraite dans le temps, par trimestre et exercice financier.
Annexe 2 – Diagramme du flux de données
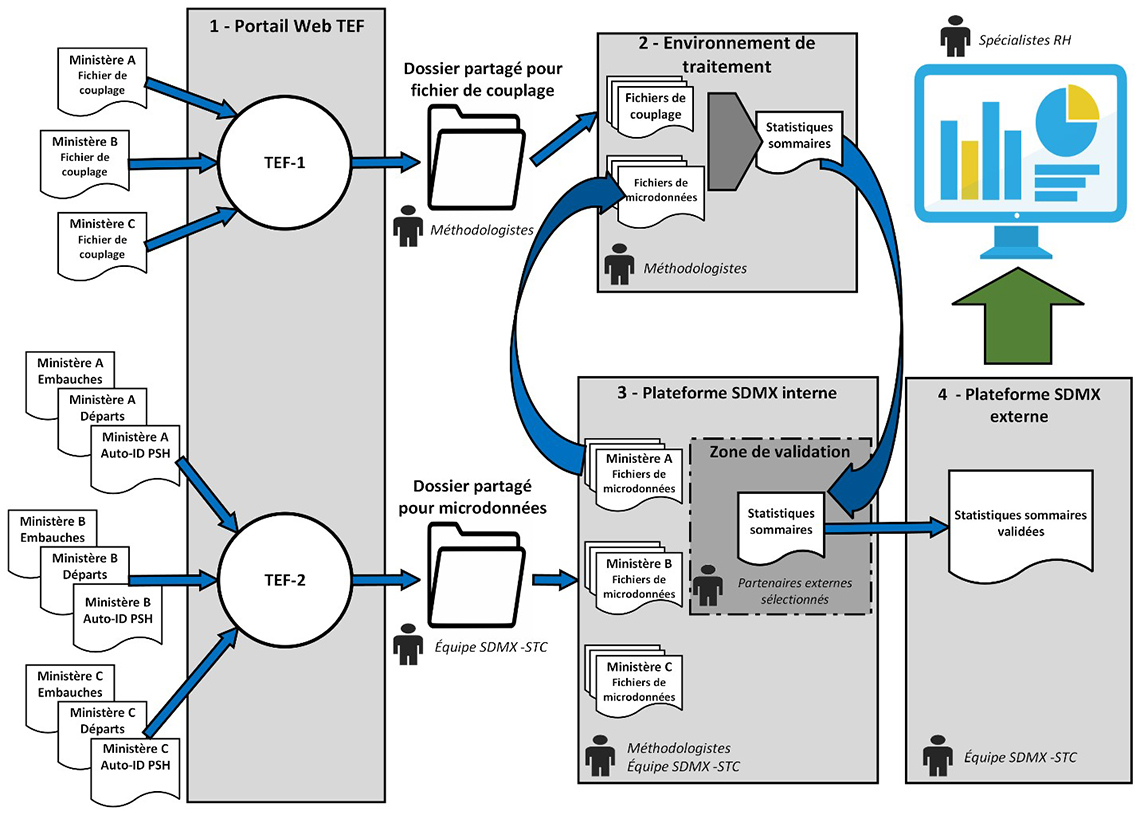
Description : Diagramme du flux de données
- Il existe deux canaux indépendants pour transmettre des fichiers à Statistique Canada, en utliisant le Service de transfert électronique de fichiers (STEF). Le premier canal sécurisé (STEF-1) sera utilisé pour envoyer/recevoir le tableau de concordance/liaison, qui est le seul fichier qui comprend un identifiant direct (le CIDP de l'employé).
- Le canal sécurisé STEF-2 sera utilisé pour la transmission de trois autres tableaux, qui ne comprennent que des données transactionnelles anonymisées des Ressources Humaines (RH) pour les embauches, les départs et les informations d'auto-identification du handicap, chacun liant au pseudo-identifiant.
- Le fichier de concordance/liaison, reçu par l'intermédiaire de STEF-1, auquel seuls cinq méthodologistes de Statistique Canada ont accès, constitue l'environnement sécurisé de traitement des données. Dans cet environnement sécurisé, les méthodologistes vont ré-identifier les trois fichiers de données avec les CIDP des employés en utilisant les tables de concordance/liaison afin de recréer la chronologie professionnelle de chaque embauche.
- Les fichiers contenant les informations d'embauche, de départ et d'auto-identification du handicap, reçus par STEF-2, seront sécurisés dans la plateforme interne d'échange de données et de métadonnées statistiques (SDMX). L'ensemble des fichiers, qui contiennent les données transactionnelles RH dépersonnalisées, sera traité par moins de cinq méthodologistes de Statistique Canada et par l'équipe SDMX de Statistique Canada. Cet environnement contiendra également la zone de transit pour les rapports statistiques sommaires, dont la confidentialité sera vérifiée par des partenaires externes sélectionnés.
- Les rapports statistiques sommaires officiels, qui ne présentent que des résultats agrégés dont la confidentialité a été vérifiée afin de s'assurer que les personnes ne peuvent être identifiées directement ou indirectement, se trouveront dans le quatrième et dernier environnement, soit une plateforme SDMX externe sécurisée.
- Ces statistiques sommaires vérifiées seront ensuite envoyées aux spécialistes des RH.
Annexe 3 – Processus / Séquence du flux de données
- Étape 1 : Configurer 2 environnements différents dans le Service de transfert électronique de fichiers (STEF) pour chacun des ministères/agences participants (TEF-1 & TEF-2).
- Étape 2 : Les clients généreront 2 ensembles de fichiers, le fichier de couplage (ensemble 1) et les fichiers de données (ensemble 2).
- Étape 3 : Les clients se connecteront au portail Web TEF, et soumettront le fichier de liaison (ensemble 1) à l'environnement TEF-1.
- Étape 4 : Les clients se connecteront au portail Web TEF, et soumettront les fichiers de données (ensemble 2) à l'environnement TEF-2.
- Étape 5 : Les fichiers de données du TEF-2 seront validés et téléchargés dans la plateforme interne sécurisée SDMX sur l'environnement principal du nuage. Les résultats de la validation seront renvoyés aux clients, en utilisant l'environnement TEF-2. Si les fichiers de données contiennent des erreurs de validation, les clients devront corriger ces erreurs, regénérer les fichiers de données et les resoumettre.
- Étape 6 : Nos méthodologistes copieront le fichier de liaison du TEF-1 à un dossier sécurisée – ce processus devrait être automatisé.
- Étape 7 : Nos méthodologistes extrairont les fichiers de données de la plateforme interne sécurisée SDMX et les copieront dans un dossier sécurisé.
- Étape 8 : Nos méthodologies traiteront les données et téléchargeront les statistiques sommaires dans la plateforme interne sécurisée SDMX (zone de transit).
- Étape 9 : Les donnée seront vérifiées pour fin de publication et copiées sur la plateforme externe sécurisée SDMX.
- Étape 10 : Le tableau de bord PowerBI sera actualisé avec la plateforme externe sécurisée SDMX, et sera mis à la disposition des départements/agences participants.
Annexe 4 - Cliché d'enregistrement
Fichier de couplage de CIDP
Le fichier de couplage de CIDP rendra possible la tâche de couplage des enregistrements des employés qui consiste à trouver des enregistrements dans les différents ensembles de données, ce qui est nécessaire pour le rapprochement des données RH des employés qui ont travaillé au sein de plusieurs départements.
| DEPT_AGEN | PRI | GEN_ID |
|---|---|---|
| STC | 88 987 789 | z32i6t0 |
| STC | 95 998 782 | jwt66sa |
| STC | 25 985 125 | lvn49sa |
| STC | 35 678 985 | sv472fe |
| STC | 44 566 974 | etw52ed |
Exemple du fichier CSV
DEPT_AGEN, PRI, GEN_ID
STC, 88 987 789, z32i6t0
STC, 95 998 782, jwt66sa
STC, 25 985 125, lvn49sa
STC, 35 678 985, sv472fe
STC, 44 566 974, etw52ed
Colonnes de données
DEPT_AGEN : Indique le département ou l'agence pour lequel le fichier de données est fourni – code à 3 lettres.
PRI : Un numéro attribué pour associer de façon unique une personne à ses dossiers personnels dans la fonction publique fédérale. L'acronyme est PRI (CIDP en français). Le dernier chiffre est un chiffre de contrôle modulos-11. Le PRI est composé de 8 chiffres, mais il est sauvegardé dans le champ précédemment occupé par le numéro d'assurance sociale (9 chiffres).
GEN_ID : Un numéro désidentifié attribué pour associer une personne de façon unique. Le GEN_ID est généré pour chaque numéro de PRI dans le cadre du suivi de l'embauche de 5000 personnes handicapées d'ici 2025. L'utilisation du GEN_ID doit être comparable entre les différents fichiers de données tels que les embauches, les départs et l'auto-identification des handicaps.
Règles de validation
- Les champs PRI et GEN_ID sont obligatoires et doivent contenir des valeurs valides dans le fichier.
- Le champ PRI doit être unique dans cette table de données.
- Le champ GEN_ID doit être unique dans cette table de données.
Convention de nomenclature
Le fichier doit être nommé selon le format suivant : NNH-PWD_Linkage_DEPT_YYYY-QQ.csv, où DEPT est remplacé par le département d'où provient le fichier, YYYY est remplacé par les quatre premiers chiffres de l'année fiscale en cours (par exemple, l'année fiscale 2022-2023 serait 2022), et QQ est remplacé par les dernières informations trimestrielles contenues dans le fichier cumulatif. Par exemple, pour Statistique Canada qui fournit les dernières informations jusqu'au dernier trimestre (Q4) de 2021-22, le nom du fichier serait NNH-PWD_Linkage_STC_2021-Q4.csv
Fichier de données d'embauche
| DATAFLOW | FREQ | DEPT_AGEN | GEN_ID | HIRE_TYPE | TIME_PERIOD | OBS_VALUE | END_DATE | NOTE |
|---|---|---|---|---|---|---|---|---|
| STC_HR:DF_HIRE(1.1) | D | STC | z32i6t0 | TERM_NEW | 2021-01-04 | 1 | 2021-07-02 | |
| STC_HR:DF_HIRE(1.1) | D | STC | jwt66sa | S | 2020-08-29 | 1 | 2020-12-31 | |
| STC_HR:DF_HIRE(1.1) | D | STC | lvn49sa | C | 2021-05-03 | 1 | 2021-08-27 | |
| STC_HR:DF_HIRE(1.1) | D | STC | sv472fe | IND_NEW | 2020-12-03 | 1 | ||
| STC_HR:DF_HIRE(1.1) | D | STC | etw52ed | IND_EXT | 2022-01-07 | 1 | ||
| STC_HR:DF_HIRE(1.1) | D | STC | tw583gf | TERM_EXT | 2021-05-27 | 1 | 2021-07-31 |
Exemple du fichier CSV
DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,HIRE_TYPE,TIME_PERIOD,OBS_VALUE,END_DATE,NOTE
STC_HR:DF_HIRE(1.1),D,STC, z32i6t0,TERM_NEW,2021-01-04,1,2021-07-02,
STC_HR:DF_HIRE(1.1),D,STC, jwt66sa,S,2020-08-29,1,2020-12-31,
STC_HR:DF_HIRE(1.1),D,STC, lvn49sa,C,2021-05-3,1,2021-08-27,
STC_HR:DF_HIRE(1.1),D,STC, sv472fe,IND_NEW,2020-12-03,1, ,
STC_HR:DF_HIRE(1.1),D,STC, etw52ed,IND_EXT,2022-01-07,1, ,
STC_HR:DF_HIRE(1.1),D,STC, tw583gf,TERM_EXT,2021-05-27,1,2021-07-31,
Colonnes de données
DATAFLOW : Une référence au flux de données décrivant les données qui doivent être représentées. Dans ce cas, la valeur "STC_HR:DF_HIRE(1.1)" doit être saisie dans la colonne DATAFLOW pour l'ensemble de données représentant les données d'embauche.
FREQ : Une référence indiquant la "fréquence" des événements dans l'ensemble de données. Elle implique indirectement le type de "référence temporelle" et est utilisée pour identifier l'événement de location par rapport au temps. Dans ce cas, la valeur "D" pour "daily" (quotidien) doit être saisie dans la colonne FREQ pour ce type de données.
DEPT_AGEN : Indique le département ou l'agence pour lequel le fichier de données est fourni - code à 3 lettres.
GEN_ID : Un numéro désidentifié attribué pour associer une personne de façon unique. Le GEN_ID est généré pour chaque numéro de PRI dans le cadre du suivi de l'embauche de 5000 personnes handicapées d'ici 2025. L'utilisation du GEN_ID doit être comparable entre les différents fichiers de données tels que les embauches, les départs et l'auto-identification des handicaps.
HIRE_TYPE : Une référence indiquant le type d'embauche. La valeur doit être codée selon la liste suivante de codes valides:
- IND_NEW : Nouvelle nomination pour période indéterminée
- IND_TERM : Conversion de déterminée à indéterminée
- IND_EXT : Nomination indéterminée d'une autre organisation
- TERM_NEW : Nouvelle nomination pour période déterminée
- TERM_EXT : Nomination déterminée d'une autre organisation
- C : Occasionnel
- S : Étudiant
- _U : Inconnu
TIME_PERIOD : La date à laquelle l'employé a été embauché. La valeur doit respecter le format de date AAAA-MM-JJ. Doit correspondre à la date d'embauche du contrat.
OBS_VALUE : La valeur de ce champ doit être "1". La valeur OBS_VALUE doit être incluse pour être conforme au cadre SDMX.
END_DATE : Ce champ est optionnel pour les nomination pour période indéterminée (IND_NEW, IND_TERM, IND_EXT). Il représente la date de fin pour les nominations pour période déterminées.
NOTE : Ce champ est optionnel. Des commentaires ou des notes peuvent être fournis pour donner des informations contextuelles sur l'embauche.
Règles de validation
- Les champs DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,HIRE_TYPE,TIME_PERIOD et OBS_VALUE sont obligatoires et doivent contenir des valeurs valides dans le fichier.
- Les champs DEPT_AGEN, GEN_ID, HIRE_TYPE et TIME_PERIOD sont les caractéristiques essentielles de ce tableau, chaque ligne de ce tableau doit avoir une combinaison unique de valeurs pour ces caractéristiques.
Convention de nomenclature
Le fichier doit être nommé selon le format suivant : NNH-PWD_Hires_DEPT_YYYY-QQ.csv, où DEPT est remplacé par le département d'où provient le fichier, YYYY est remplacé par les quatre premiers chiffres de l'année fiscale en cours (par exemple, l'année fiscale 2022-2023 serait 2022), et QQ est remplacé par les dernières informations trimestrielles contenues dans le fichier cumulatif. Par exemple, pour Statistique Canada qui fournit les dernières informations jusqu'au dernier trimestre (Q4) de 2021-22, le nom du fichier serait NNH-PWD_Hires_STC_2021-Q4.csv
Fichier de données de départ
| DATAFLOW | FREQ | DEPT_AGEN | GEN_ID | DEPARTURE_TYPE | TIME_PERIOD | OBS_VALUE | HIRE_DATE | NOTE |
|---|---|---|---|---|---|---|---|---|
| STC_HR:DF_DEPARTURE(1.1) | D | STC | z32i6t0 | RET | 2022-01-25 | 1 | 1991-05-27 | |
| STC_HR:DF_DEPARTURE(1.1) | D | STC | jwt66sa | END_TERM | 2021-08-20 | 1 | 2021-01-04 | |
| STC_HR:DF_DEPARTURE(1.1) | D | STC | lvn49sa | END_TERM | 2021-04-30 | 1 | 2021-01-11 | |
| STC_HR:DF_DEPARTURE(1.1) | D | STC | sv472fe | RES | 2021-06-13 | 1 | 2020-12-03 | |
| STC_HR:DF_DEPARTURE(1.1) | D | STC | etw52ed | _O | 2021-07-07 | 1 | 1991-10-08 | |
| STC_HR:DF_DEPARTURE(1.1) | D | STC | tw583gf | RET | 2021-05-27 | 1 | 1999-12-13 |
Exemple du fichier CSV
DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DEPARTURE_TYPE,TIME_PERIOD,OBS_VALUE,HIRE_DATE,NOTE
STC_HR:DF_DEPARTURE(1.1),D,STC, z32i6t0,RET,2022-01-25,1,1991-05-27,
STC_HR:DF_DEPARTURE(1.1),D,STC, jwt66sa,END_TERM,2021-08-20,1,2021-01-04,
STC_HR:DF_DEPARTURE(1.1),D,STC, lvn49sa,END_TERM,2021-04-30,1,2021-01-11,
STC_HR:DF_DEPARTURE(1.1),D,STC, sv472fe,RES,2021-06-13,1,2020-12-03,
STC_HR:DF_DEPARTURE(1.1),D,STC, etw52ed,_O,2021-07-07,1,1991-10-08,
STC_HR:DF_DEPARTURE(1.1),D,STC, tw583gf,RET,2020-10-07,1,1999-12-13,
Colonnes de données
DATAFLOW : Une référence au flux de données décrivant les données qui doivent être représentées. Dans ce cas, la valeur "STC_HR:DF_DEPARTURE(1.1)" doit être saisie dans la colonne DATAFLOW pour l'ensemble de données représentant les données de départ.
FREQ : Une référence indiquant la "fréquence" des événements dans l'ensemble de données. Elle implique indirectement le type de "référence temporelle" et est utilisée pour identifier l'événement de location par rapport au temps. Dans ce cas, la valeur "D" pour "daily" (quotidien) doit être saisie dans la colonne FREQ pour ce type de données.
DEPT_AGEN : Indique le département ou l'agence pour lequel le fichier de données est fourni - code à 3 lettres.
GEN_ID : Un numéro désidentifié attribué pour associer une personne de façon unique. Le GEN_ID est généré pour chaque numéro de PRI dans le cadre du suivi de l'embauche de 5000 personnes handicapées d'ici 2025. L'utilisation du GEN_ID doit être comparable entre les différents fichiers de données tels que les embauches, les départs et l'auto-identification des handicaps.
DEPARTURE_TYPE : Une référence indiquant le type d'embauche. La valeur doit être codée selon la liste suivante de codes valides:
- EXT : Départ vers une autre organisation
- END_TERM : Fin de terme
- RES : Démission
- RET : Retraite
- _O : Autre départ de la fonction publique
- _U : Inconnu
TIME_PERIOD : La date de départ de l'employé. La valeur doit respecter le format de date AAAA-MM-JJ.
OBS_VALUE : La valeur de ce champ doit être "1". La valeur OBS_VALUE doit être incluse pour être conforme au cadre SDMX.
HIRE_DATE : Ce champ est optionnel. Il représente la date à laquelle l'employé a été embauché.
NOTE : Ce champ est optionnel. Des commentaires ou des notes peuvent être fournis pour donner des informations contextuelles sur le départ.
Règles de validation
- Les champs DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DEPARTURE_TYPE,TIME_PERIOD et OBS_VALUE sont obligatoires et doivent contenir des valeurs valides dans le fichier.
- Les champs DEPT_AGEN, GEN_ID, DEPARTURE_TYPE et TIME_PERIOD sont les caractéristiques essentielles de ce tableau, chaque ligne de ce tableau doit avoir une combinaison unique de valeurs pour ces caractéristiques.
Convention de nomenclature
Le fichier doit être nommé selon le format suivant : NNH-PWD_Departures_DEPT_YYYY-QQ.csv, où DEPT est remplacé par le département d'où provient le fichier, YYYY est remplacé par les quatre premiers chiffres de l'année fiscale en cours (par exemple, l'année fiscale 2022-2023 serait 2022), et QQ est remplacé par les dernières informations trimestrielles contenues dans le fichier cumulatif. Par exemple, pour Statistique Canada qui fournit les dernières informations jusqu'au dernier trimestre (Q4) de 2021-22, le nom du fichier serait NNH-PWD_Departures_STC_2021-Q4.csv
Fichier de données d'auto-identification des handicaps
| DATAFLOW | FREQ | DEPT_AGEN | GEN_ID | DISABILITY_TYPE | TIME_PERIOD | OBS_VALUE | SELF_ID_VERSION | NOTE |
|---|---|---|---|---|---|---|---|---|
| STC_HR:DF_SELF_ID(1.1) | D | STC | z32i6t0 | 99 | 2022-01-25 | 1 | 1 | |
| STC_HR:DF_SELF_ID(1.1) | D | STC | jwt66sa | 16 | 2022-01-26 | 1 | 1 | |
| STC_HR:DF_SELF_ID(1.1) | D | STC | lvn49sa | 12 | 2005-11-15 | 1 | 1 | |
| STC_HR:DF_SELF_ID(1.1) | D | STC | sv472fe | 19 | 2022-02-15 | 1 | 1 | |
| STC_HR:DF_SELF_ID(1.1) | D | STC | etw52ed | 99 | 2022-01-26 | 1 | 1 | |
| STC_HR:DF_SELF_ID(1.1) | D | STC | tw583gf | 99 | 2018-07-30 | 1 | 1 |
Exemple du fichier CSV
DATAFLOW,FREQ,DEPT_AGEN,GEN_ID,DISABILITY_TYPE,TIME_PERIOD,OBS_VALUE,SELF_ID_VERSION,NOTE
TC_HR:DF_SELF_ID(1.1),D,STC, z32i6t0,99,2022-01-25,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, jwt66sa,16,2022-01-26,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, lvn49sa,12,2005-11-15,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, sv472fe,19,2022-02-15,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, etw52ed,99,2022-01-26,1,1,
STC_HR:DF_SELF_ID(1.1),D,STC, tw583gf,99,2018-07-30,1,1 ,
Colonnes de données
DATAFLOW : Une référence au flux de données décrivant les données qui doivent être représentées. Dans ce cas, la valeur "STC_HR:DF_SELF_ID(1.1)" doit être saisie dans la colonne DATAFLOW pour l'ensemble de données représentant les données d'auto-identification des handicaps.
FREQ : Une référence indiquant la "fréquence" des événements dans l'ensemble de données. Elle implique indirectement le type de "référence temporelle" et est utilisée pour identifier l'événement de location par rapport au temps. Dans ce cas, la valeur "D" pour "daily" (quotidien) doit être saisie dans la colonne FREQ pour ce type de données.
DEPT_AGEN : Indique le département ou l'agence pour lequel le fichier de données est fourni - code à 3 lettres.
GEN_ID : Un numéro désidentifié attribué pour associer une personne de façon unique. Le GEN_ID est généré pour chaque numéro de PRI dans le cadre du suivi de l'embauche de 5000 personnes handicapées d'ici 2025. L'utilisation du GEN_ID doit être comparable entre les différents fichiers de données tels que les embauches, les départs et l'auto-identification des handicaps.
DISABILITY_TYPE : Une référence indiquant le type d'handicap. La valeur doit être codée selon la liste suivante de codes valides:
- 16 : Trouble de la vision
- 19 : Trouble de l'audition
- 13 : Trouble de la parole
- 12 : Trouble de mobilité
- 11 : Difficultés avec la souplesse ou la dextérité
- 23 : Autre (version 1)
- 31 : Trouble de santé mentale
- 32 : Trouble sensoriel ou lié àl'environnement
- 33 : Maladie ou douleur chronique
- 34 : Trouble cognitif
- 35 : Déficience intellectuelle
- 99 : Autre trouble ou handicap (version 2)
- _N : Préfère ne pas préciser
TIME_PERIOD : La date à laquelle l'employé s'est auto-identifié. La valeur doit respecter le format de date AAAA-MM-JJ.
OBS_VALUE: La valeur de ce champ doit être "1". La valeur OBS_VALUE doit être incluse pour être conforme au cadre SDMX.
SELF_ID_VERSION : Ce champ est optionnel. Lorsque disponible, il représente la version du questionnaire d'auto-identification.
NOTE : Ce champ est optionnel. Des commentaires ou des notes peuvent être fournis pour donner des informations contextuelles sur l'auto-identification.
Règles de validation
- Les champs DATAFLOW, FREQ, DEPT_AGEN, GEN_ID, DISABILITY_TYPE, TIME_PERIOD et OBS_VALUE sont obligatoires et doivent contenir des valeurs valides dans le fichier.
- Les champs DEPT_AGEN, GEN_ID, DISABILITY_TYPE et TIME_PERIOD sont les caractéristiques essentielles de ce tableau, chaque ligne de ce tableau doit avoir une combinaison unique de valeurs pour ces caractéristiques.
Convention de nomenclature
Le fichier doit être nommé selon le format suivant : NNH-PWD_SelfID_DEPT_YYYY-QQ.csv, où DEPT est remplacé par le département d'où provient le fichier, YYYY est remplacé par les quatre premiers chiffres de l'année fiscale en cours (par exemple, l'année fiscale 2022-2023 serait 2022), et QQ est remplacé par les dernières informations trimestrielles contenues dans le fichier cumulatif. Par exemple, pour Statistique Canada qui fournit les dernières informations jusqu'au dernier trimestre (Q4) de 2021-22, le nom du fichier serait NNH-PWD_ SelfID_STC_2021-Q4.csv