
Par Christian Ritter, William Spackman, Todd Best, Serge Goussev, Greg DeVilliers et Stephen Theobald, Statistique Canada
Introduction
Statistique Canada (StatCan) est passé à une stratégie qui accorde la priorité aux données administratives (Stratégie des données de Statistique Canada). Parallèlement, l'organisme a également étudié et exploité l'apprentissage automatique (AA) (Projets en science des données) de façon accrue, non seulement en raison du volume et de la vitesse des nouvelles données, mais aussi en raison de leur diversité, certaines parties des données étant non structurées ou semi-structurées. Le Cadre pour l'utilisation responsable de l'apprentissage automatique (Utilisation responsable de l'apprentissage automatique à Statistique Canada) a permis d'orienter l'adoption de l'AA par StatCan en vue de la réalisation d'investissements à l'appui d'applications et de méthodes fiables. Cette adoption a également mis l'accent sur le développement d'un code de niveau de production et d'autres pratiques exemplaires (Code de niveau de production dans le domaine de la science des données). L'un des types de pratiques exemplaires élaborés met l'accent sur la transparence, la reproductibilité, la rigueur, l'évolutivité et l'efficacité — des processus également connus sous le nom d'opérations d'apprentissage automatique, ou MLOps. Le présent article propose un aperçu des investissements réalisés et des projets d'élaboration de MLOps à StatCan, en se concentrant sur le cas d'utilisation des statistiques sur les prix, en particulier pour l'Indice des prix à la consommation (IPC) canadien.
À l'instar de nombreux organismes nationaux de statistique (ONS), le programme de l'IPC de StatCan tire avantage de l'AA supervisé pour classer de nouveaux produits uniques (UN Task Team on Scanner Data, 2023 (en anglais seulement)) provenant de sources de données de rechange (p. ex. données de lecteurs optiques, extraites du moissonnage du Web ou administratives) dans les classes de produits utilisées pour l'IPC. Les données administratives de l'économie de consommation soulèvent une préoccupation particulière, à savoir le dynamisme au fil du temps, avec l'arrivée de nouveaux produits sur le marché et le retrait d'anciens produits. Du point de vue de l'AA, cette évolution au fil du temps peut être considérée comme le déplacement progressif de la répartition des données à classer pour chaque mois, par rapport à la répartition sur laquelle un modèle d'AA a été entraîné, ce qui donne lieu à une dégradation graduelle du modèle (voir la figure 1 pour obtenir une visualisation du concept). Comme le montrent Spackman et coll., 2023 (en anglais seulement) et Spackman et coll., 2024 (en anglais seulement), une classification erronée peut également avoir des répercussions sur un indice de prix. Une approche fiable est donc nécessaire pour combiner l'observation des données et des modèles, la validation des enregistrements pour corriger les classifications erronées, et un réentraînement fréquent pour s'assurer que les indices de prix ne sont touchés par aucune classification erronée. Le cadre des MLOps permet de répondre à ces préoccupations grâce à un processus fiable de production d'AA.
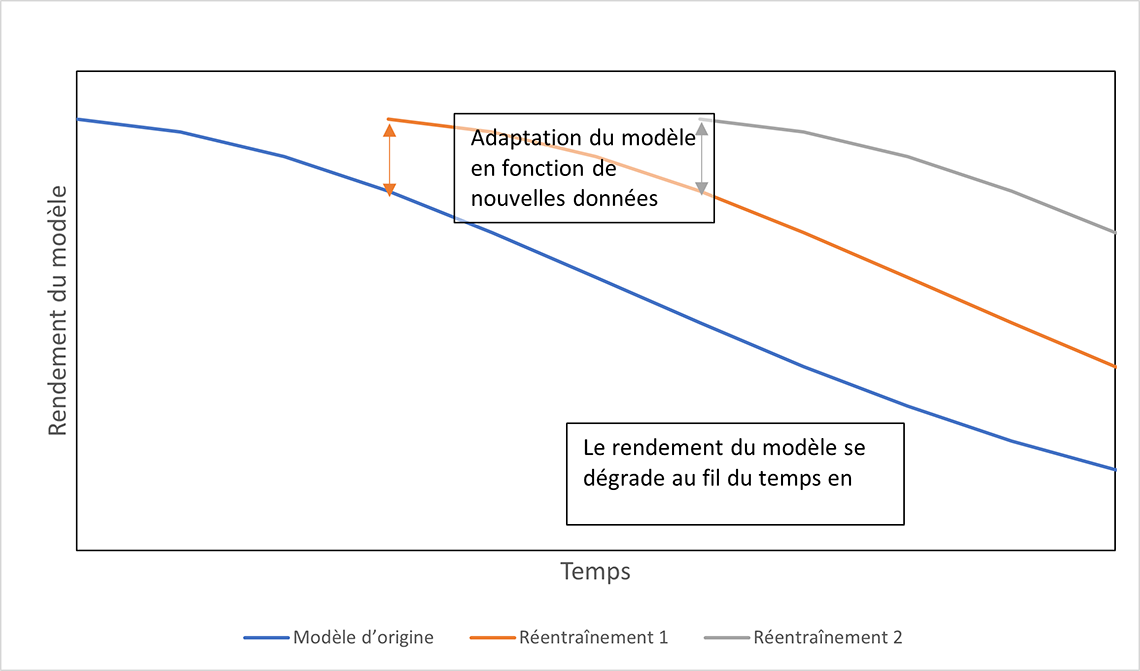
Description - Figure 1 : Dérive conceptuelle et réentraînement — incidence sur le rendement du modèle
Le rendement de la classification sur les nouveaux produits observés dans les données recueillies grâce au moissonnage du Web baisse de façon constante au fil du temps. Cependant, le réentraînement du modèle sur une base périodique (p. ex. tous les trois mois) permet d'améliorer le rendement.
Pourquoi le cadre des MLOps est-il utile dans cette situation?
L'application de l'AA à un processus de production nécessite un examen approfondi de plusieurs besoins opérationnels de l'utilisateur final notamment des suivants :
- Efficacité globale, telle que la rentabilité de la gestion
- Capacité d'effectuer l'inférence de modèle sur la production de mégadonnées avec leurs 5V (volume, véracité, vitesse, variété et valeur)
- Assurance d'une utilisation transparente et efficace des algorithmes très complexes
- Assurance d'un rendement fiable et acceptable du modèle en continu assorti d'un risque faible
- Assurance de l'utilisation de nombreux modèles, en parallèle ou au moyen de mises à jour
- Gestion de la dépendance complexe de cadres et de progiciels d'AA en accès libre
- Satisfaction des besoins organisationnels en matière de gouvernance.
Pour répondre à ces besoins opérationnels, le modèle courant d'AA n'est qu'un infime élément dans le contexte du processus global de production d'AA, comme il est souligné par Sculley et coll., 2015 (en anglais seulement), et comme l'illustre la figure 2.
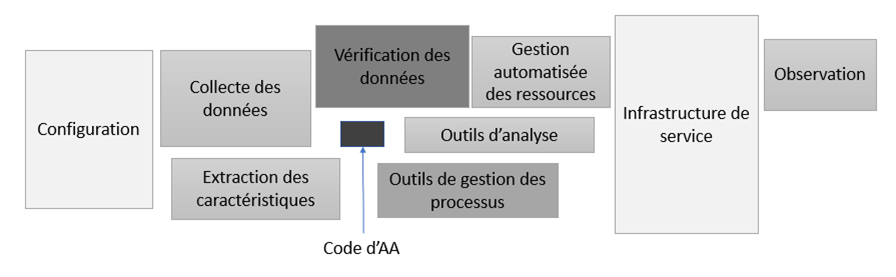
Description - Figure 2 : Profondeur technique cachée dans les systèmes d'AA, adaptée de la figure 1 dans Sculley et coll., 2015.
L'AA, comme la modélisation elle-même, est en fait une petite composante de nombreuses composantes plus importantes lorsqu'il s'agit de systèmes de production fiables. Par exemple, la configuration est un sujet important, et il est indispensable de disposer d'un traitement pour servir, observer ou analyser le modèle et le rendement. L'élaboration de processus de vérification des données, de gestion des ressources et des processus, et de collecte et d'extraction de données, sont autant d'éléments dans lesquels il est également nécessaire d'investir.
De manière générale, des efforts considérables sont déployés depuis des décennies pour répondre à des besoins opérationnels semblables (en particulier dans le secteur financier), mais ces efforts ont été grandement renforcés lorsque l'AA s'est généralisé dans toutes les industries et que des besoins supplémentaires sont apparus, notamment la nécessité de traiter des mégadonnées et des réseaux neuronaux de plus en plus complexes. Le cadre des MLOps est le processus de production d'AA qui vise à répondre à tous les besoins opérationnels courants susmentionnés. Le cadre des MLOps d'aujourd'hui peut être considéré comme un paradigme ou une approche permettant la livraison automatisée, efficace, transparente et itérative de modèles d'AA en production, tout en se concentrant sur les exigences opérationnelles et réglementaires. Il présente donc de nombreux avantages, en particulier pour StatCan. Le cadre des MLOps couvre les méthodologies statistiques (p. ex. détection des dérives, classification erronée), les pratiques exemplaires en matière de génie logiciel (p. ex. DevOps), et l'infrastructure et les outils (infonuagiques) (p. ex. conception des systèmes, observation, solutions évolutives).
L'approche automatisée et itérative du cadre des MLOps s'inspire des pratiques DevOps du génie logiciel, ce qui, dans le contexte de l'AA, aide à réaliser des économies et à accroître la vitesse de création et de déploiement des modèles, permettant ainsi l'utilisation de nombreux modèles. En outre, la gouvernance et la transparence s'améliorent grâce à l'utilisation du cadre des MLOps. Le processus de création de modèles, avec son approche complexe en plusieurs étapes tenant compte des dépendances de données et de logiciels, est représenté par des pipelines d'entraînement. Un (ré)entraînement fréquent des modèles (réentraînement continu) est souvent nécessaire pour atténuer la dégradation de l'exactitude des modèles d'AA imputable à la dérive des données.
En complément, le processus de déploiement des modèles s'inspire souvent du génie logiciel avec le concept de « déploiement » du logiciel, du modèle et de ses dépendances, dans un environnement de production isolé. Le déploiement s'effectue souvent sur une infrastructure évolutive (c.-à-d. dans laquelle il est facile d'augmenter ou de réduire les ressources informatiques) pour gérer les caractéristiques des mégadonnées; le modèle est encapsulé et intégré dans une interface claire et conviviale (c.-à-d. capable d'interagir par une interface de programmation d'applications, ou API). Ce processus comporte des composantes propres à l'AA, telles que la nécessité d'enregistrer et d'observer le comportement du modèle et des données, et potentiellement d'autoriser la fonctionnalité d'interprétabilité ou d'explicabilité de l'AA.
Comment l'approche des MLOps s'intègre-t-elle aux besoins en matière de statistiques de prix?
L'AA supervisé est un outil clé dans les pipelines de traitement des statistiques des prix à la consommation. Plus précisément, comme l'IPC est calculé à partir d'indices de prix pour des agrégats élémentaires (des associations de classes de produits et de classes géographiques) (Le document de référence de l'Indice des prix à la consommation canadien, Chapitre 4 – Classifications), la classification doit être effectuée pour les produits uniques dans leurs codes de produits respectifs appropriés (c.-à-d. les catégories). D'un point de vue technique, il s'agit d'un problème de traitement du langage naturel, semblable à d'autres exemples de StatCan (Classification des commentaires sur le Recensement de 2021), où le texte décrivant un produit est utilisé par le modèle pour classer le produit dans un groupe utilisé pour les indices de prix. La classification n'étant pas parfaite, une validation manuelle des enregistrements est nécessaire pour corriger les erreurs avant de compiler les indices de prix. Cette validation permet en outre de créer de nouveaux exemples qui peuvent être utilisés comme données de réentraînement. StatCan possède une vaste expérience de ce processus, décrit plus en détail comme l'étape 5.2 du Modèle générique du processus de production statistique (GSBPM) (Classification des commentaires sur le Recensement de 2021). La figure 3 illustre que cette étape clé est au cœur d'un pipeline de traitement d'une source de données de rechange type, telle que des données de lecteurs optiques, avant que le fichier ne puisse être utilisé en production.
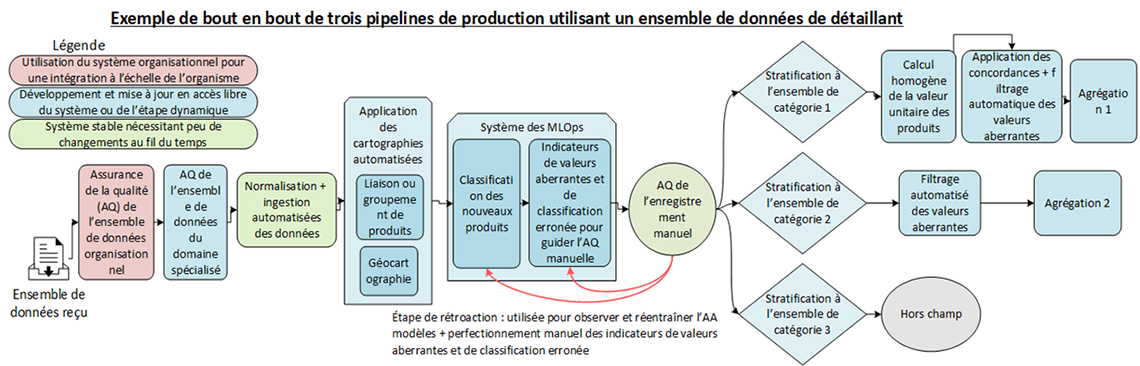
Description - Figure 3 : Application des MLOps dans le pipeline de traitement des statistiques des prix à la consommation. Un processus manuel d'assurance de la qualité des enregistrements est utile non seulement pour valider l'étape de classification, mais aussi pour créer des données de réentraînement. Pour appuyer cette assurance de la qualité manuelle, on conçoit un processus précis de signalement de classification erronée et de valeur aberrante.
Le pipeline de traitement des statistiques des prix à la consommation commence par l'assurance de la qualité de l'ensemble de données. Il se poursuit par la normalisation des données et leur ingestion dans un emplacement de stockage central aux fins d'analyse. À partir de là, des produits quasi identiques, mais homogènes peuvent être reliés entre eux, et la géographie est cartographiée pour les besoins des statistiques de prix. C'est à ce moment que l'on a besoin du système des MLOps pour classer chaque produit unique — dans la catégorie de produits à laquelle il devrait appartenir. Les enregistrements sont ensuite examinés manuellement, en accordant une attention particulière à ceux signalés comme ayant une classification erronée ou une valeur aberrante. Enfin, une agrégation élémentaire des prix peut être effectuée sur ces données, en fonction des strates nécessaires à cette méthodologie précise d'agrégation des prix.
L'adoption de principes de MLOps pour ce cas d'utilisation augmenterait considérablement la maturité du processus. Le tableau 1 ci-dessous résume la valeur promise (à gauche) et la manière dont elle répond aux besoins concrets en matière de statistiques de prix (à droite).
| Promesse des MLOps | Satisfaction des besoins en matière de statistiques de prix |
|---|---|
| Économies de coûts générales | Réduction des coûts liés aux calculs et au travail des scientifiques des données grâce à l'automatisation des processus |
| Stabilisation du pipeline pour l'ensemble du cycle de vie de l'AA grâce à des pratiques DevOps | Réduction des risques d'erreurs et de frictions entre l'élaboration des modèles et la production |
| Réduction des frictions à chaque étape du processus des MLOps grâce à l'automatisation | Automatisation d'étapes complexes du travail de science des données (p. ex. prétraitement et entraînement, reproductibilité et transparence du travail) |
| Réutilisation du pipeline de création de modèles pour produire des centaines de modèles | Possibilité d'utiliser les modèles d'entraînement fondés sur de nouvelles données pour créer en permanence des modèles d'AA, en orientant le pipeline d'entraînement vers de nouvelles données |
| Capacité de déploiement accéléré et simplifié des modèles d'AA | Réponse au besoin de produire plusieurs modèles par source de données de rechange à une fréquence plus élevée |
| Utilisation de l'emplacement central de suivi et de versionnage des modèles | Entrepôt central de modèles et contrôle accru de l'historique et de la gouvernance requis pour tenir à jour des centaines de modèles |
| Échelonnage simple et automatisé du calcul pendant le processus des MLOps approprié au temps et à l'échelle nécessaires | Capacité d'échelonnage en fonction de la quantité croissante de données à l'aide de systèmes de calcul de haute performance et de systèmes distribués; utilisation rentable |
| Observation prolongée : de l'observation de l'infrastructure à l'observation des modèles | Garantie de la fiabilité du rendement des modèles en dépit d'une multitude de facteurs tels que les mises à jour des modèles, la dérive des données et les erreurs |
| Politique et déroulement des opérations communs | Processus automatisé normalisé permettant à l'organisme de répondre à ses besoins en matière d'utilisation de l'intelligence artificielle (IA) |
| Gestion de dépendances complexes (en accès libre) | Réduction du risque d'échec (silencieux) grâce à des pratiques exemplaires de génie logiciel, comme la virtualisation, les essais, l'intégration continue (IC) et le déploiement continu (DC) (désignés ensemble « CI/CD ») |
| Audit et gouvernance | Reproductibilité grâce au contrôle des versions de tous les artefacts d'AA; adoption simple de cadres de responsabilité et de contrôle tels que le cadre d'utilisation responsable de l'IA |
Cheminement vers l'adoption au moyen du modèle de maturité itératif
Intégration au processus existant
Conformément à la description ci-dessus, la classification des produits (et la détection des valeurs aberrantes et des classifications erronées) fait partie des composantes d'un processus beaucoup plus vaste englobant des données d'autres sources. L'intégration doit donc être réalisée de manière modulaire et dissociée, en suivant les pratiques exemplaires de conception architecturale. Le service de classification ou le système des MLOps est exposé au reste du système de traitement au moyen d'API REST dédiées, ce qui permet une intégration en douceur. Les mises à jour et les modifications apportées à ce système des MLOps ne doivent pas avoir d'incidence sur le système global, tant qu'aucune modalité des contrats d'API n'est enfreinte.
Étapes de maturité
En fonction des besoins opérationnels et d'une étude de faisabilité, une approche itérative a été conçue pour l'adoption des MLOps selon quatre niveaux de maturité des MLOps. Ces étapes, semblables aux pratiques exemplaires de l'industrie telles que celles décrites par Google (MLOps: Continuous delivery and automation pipelines in machine learning (en anglais seulement)) ou Microsoft (Modèle de maturité des opérations de Machine Learning), adoptent un niveau croissant d'automatisation et de corrections pour une variété de risques. La génération de valeur est possible dès le niveau 1 en abordant les aspects les plus critiques de la production d'AA.
| Maturité | Couverture |
|---|---|
| Niveau 0 | Avant l'adoption des MLOps; utilisation du bloc-notes Jupyter pour la modélisation et de scripts Luigi pour l'inférence et l'orchestration |
| Niveau 1 | Entraînement automatique au moyen de pipelines d'entraînement continu, gestion des artefacts d'AA et contrôle des versions; contrôles et observation de la qualité des données de base |
| Niveau 2 | Inférence automatique et évolutive du modèle d'AA sur de nouvelles données; déploiement continu vers des points d'extrémité évolutifs |
| Niveau 3 | Observation assortie de détection des dérives fondée sur le rendement, déploiement de modèles fantômes, réentraînement automatisé, utilisation responsable de l'IA avec des cartes de modèles et établissement de rapports normalisés |
Vue d'ensemble de l'architecture et des capacités du système
Avant de s'intéresser à chaque composante et capacité du système, on fournit une représentation visuelle de l'ensemble de l'architecture et du déroulement des opérations d'exécution. Les pipelines (sous forme de code) sont publiés dans l'environnement de production, puis exécutés selon les pratiques exemplaires des MLOps afin d'en garantir la reproductibilité. Des métadonnées sont conservées sur chaque aspect et la provenance est bien établie.
Flux de production
Tout d'abord, on décrit le déroulement des opérations qui survient pour chaque nouvel ensemble de données de détaillant. La figure 4 illustre les étapes qui peuvent être résumées comme un processus de traitement par lots en plusieurs étapes.
- État initial : Un nouvel ensemble de données de détaillant arrive dans l'entrepôt de données au moyen du processus bronze-argent-or.
- Un pipeline Synapse est déclenché pour extraire les nouvelles données uniques sur les produits dans le lac de données et appeler notre principal point d'extrémité REST.
- Le principal point d'extrémité REST exécute un pipeline d'orchestration qui interagit avec différents pipelines (composantes).
- Il appelle d'abord le pipeline de validation des données qui teste les attentes en matière de données définies au moyen de Great Expectations (GE) (Great Expectations Github (en anglais seulement)). Les rejets à la vérification donnent lieu à des rapports automatiques sur les données.
- Le pipeline de classification suit, utilisant le type de données et le détaillant en question comme paramètres pour repérer les modèles à production échelonnée dans le registre ainsi que les déploiements correspondants sous les points d'extrémité gérés, comme il convient dans ce cas.
- Les déploiements distribuent les données à travers plusieurs nœuds aux fins de traitement en parallèle.
- Les classifications qui en résultent sont validées et vérifiées pour détecter les valeurs aberrantes et les classifications erronées au moyen de méthodes versionnées. On attribue une catégorie aux valeurs aberrantes ou aux classifications erronées.
- L'orchestrateur place les données classées dans le lac, ce qui déclenche l'exécution d'un pipeline Synapse pour le chargement de ces données de sortie dans l'entrepôt de données.
- Les résultats de la classification et les données aux valeurs aberrantes sont réingérés dans l'entrepôt de données.
- Les résultats de la classification et les données aux valeurs aberrantes sont désormais accessibles dans l'entrepôt pour la consommation en aval (et surtout pour la validation).
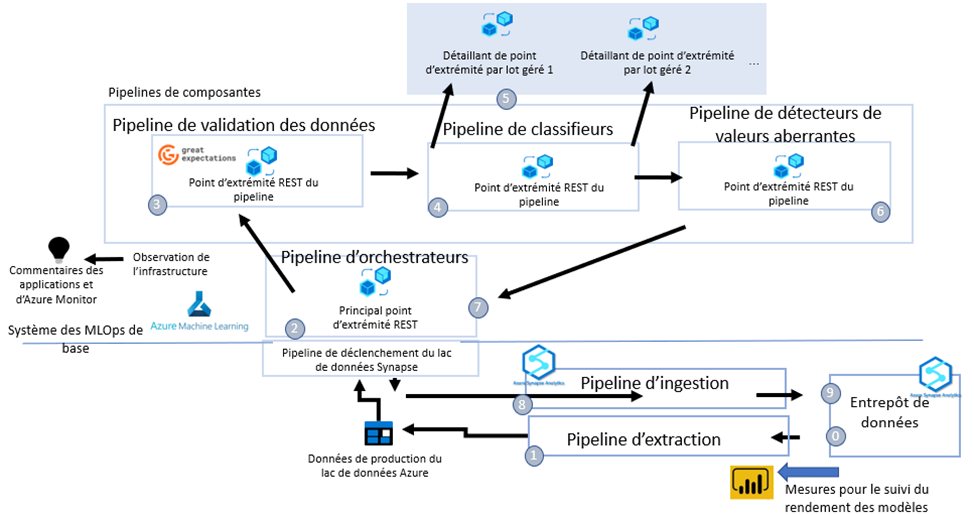
Description - Figure 4 : Schéma du déroulement des opérations de traitement de la production
Voir le résumé du déroulement des opérations de production ci-dessus pour obtenir un aperçu détaillé étape par étape de ce processus en neuf étapes.
Déroulement des opérations de création de modèles
Le processus de création du modèle est effectué en marge du déroulement des opérations de production. La figure 5 illustre ces étapes.
- Le code de modélisation est poussé vers la branche de développement sur GitLab, ce qui déclenche le pipeline de DC pour intégrer le code du pipeline dans Azure Machine Learning (Azure ML).
- Dans le cadre du processus d'IC, le code est testé selon des procédures établies.
- Une fois approuvé par l'intermédiaire d'une demande de fusion, le pipeline de DC publie le pipeline d'entraînement dans l'espace de travail en tant que nouvelle version, où il devient disponible aux fins d'exécution. Remarque : Il contient la configuration d'entraînement pour différents détaillants, au besoin.
- Le pipeline d'entraînement peut être exécuté en le dirigeant vers un emplacement du lac de données où sont stockées les données d'entraînement (ou de réentraînement) prédéterminées. Cette étape peut être programmée aux fins d'exécution au moment de la création de données de réentraînement actualisées. Si l'entraînement est réussi, le modèle est inscrit au registre des modèles Azure ML, sous un nom et une version uniques.
- La définition du modèle en production est stockée dans un fichier de configuration sur GitLab; la modification de ce fichier entraîne une modification de la configuration du déploiement. Les modèles qui se trouvent sur MLflow (MLflow Tracking : Une façon efficace de suivre les essais de modélisation) sont désignés en conséquence dans le registre des modèles, puis déployés en tant que déploiement sous un point d'extrémité géré correspondant.
- Selon les besoins des données, un modèle peut être utilisé pour chaque détaillant ou pour plusieurs détaillants. Des modèles fantômes sont également utilisés, s'il y a lieu, pour permettre un processus fiable de mise à jour des modèles à l'issue d'une phase d'observation.
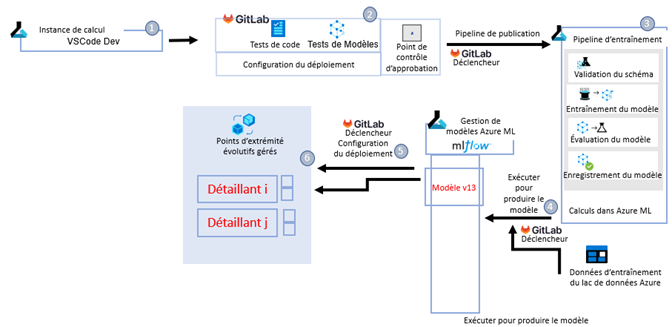
Description - Figure 5 : De bout en bout : de l'entraînement au déploiement
Voir le résumé du déroulement des opérations de création de modèles ci-dessus pour obtenir un aperçu détaillé étape par étape de ce processus en six étapes.
Aperçu détaillé des capacités des MLOps
Bien que l'architecture du système permet d'automatiser de manière fiable tous les aspects nécessaires de la production et d'appuyer le réentraînement automatisé, ces étapes sont requises pour gérer la dérive des données.
Concept de dérive des données
Dans les environnements dynamiques et non stationnaires, la répartition des données peut changer au fil du temps, entraînant le phénomène de dérive conceptuelle (João et coll., 2014 (en anglais seulement)). Dans le contexte des données sur les prix à la consommation, cela pourrait se traduire par l'introduction de nouvelles catégories de produits sur le marché au fil du temps et par l'évolution des préférences des consommateurs. Le rendement du modèle se dégradera si la modification de la répartition des données modifie la limite de décision entre les classes, ce que l'on appelle la dérive conceptuelle réelle (figure 6).
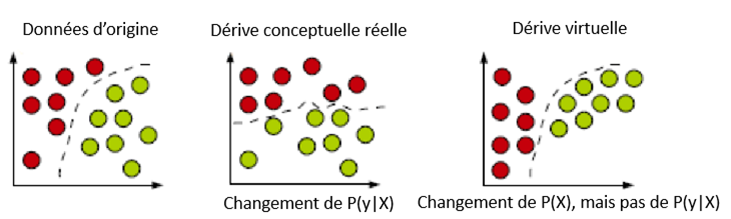
Description - Figure 6 : Types de dérives : les cercles représentent les instances, les différentes couleurs représentent les différentes classes (João et coll., 2014).
Un exemple simplifié est fourni pour expliquer la dérive. Les données d'origine (à gauche) suivent une répartition précise, et un modèle apprend à s'adapter à une limite de décision pour classer les données en deux catégories. Si la répartition change (au centre), c.-à-d. P(y|X), un réentraînement est nécessaire pour réadapter les données et assimiler une nouvelle limite de décision afin de classer les données en deux catégories. Toutefois, il peut également y avoir une dérive virtuelle, dans le cadre de laquelle P(X) change, mais pas p(y|X), de sorte que la limite de décision existante fonctionne toujours bien.
Ces changements de répartition peuvent se produire brusquement ou au fil du temps, comme le montre la figure 7.

Description - Figure 7 : Modèles de changements au fil du temps (la valeur aberrante n'est pas une dérive conceptuelle) (João et coll., 2014).
Cinq scénarios de changement de répartition sont présentés. Le premier scénario correspond à un changement soudain ou brusque, dans lequel la répartition change à un moment donné et ne change plus par la suite. Le deuxième scénario pourrait être incrémentiel, c'est-à-dire que le changement se fait de manière continue au fil du temps et finit par se stabiliser à un nouveau niveau. Le troisième scénario pourrait également être progressif, mais au lieu d'être continu, il pourrait évoluer rapidement, puis revenir en arrière, et se comporter ainsi pendant un certain temps avant de se stabiliser au nouveau niveau. Dans le quatrième scénario, le changement pourrait être récurrent, c.-à-d. qu'il se produit vers un nouveau niveau, mais qu'il ne demeure à ce niveau que pendant un certain temps, avant de revenir au niveau d'origine. Dans le cinquième scénario, il pourrait simplement s'agir d'une valeur aberrante, mais pas d'une dérive.
Il est important que le système de production MLOps mis en œuvre dispose d'outils permettant de détecter et de corriger les dérives conceptuelles au fur et à mesure qu'elles se produisent.
Détection des dérives
Les données sur les prix à la consommation ne sont pas connues pour changer brusquement. On a donc choisi une détection des dérives fondée sur le rendement (Spackman et coll., 2023). Comme son nom l'indique, la détection des dérives fondée sur le rendement évalue le rendement du modèle prédictif pour établir la présence d'une dérive. Cette approche est appropriée en présence d'une proportion élevée de validation pour corriger les éventuelles classifications erronées après le modèle, comme c'est le cas pour notre mise en œuvre. Dans nos systèmes de production, le rendement du modèle prédictif est inconnu au moment de la classification. Pour calculer le rendement, un sous-ensemble des instances prédites doit être signalé aux fins d'assurance de la qualité. Une fois que l'on dispose d'un ensemble de données dont la qualité est garantie, on peut comparer les prédictions du modèle aux vraies classes afin de calculer les paramètres d'évaluation permettant de mesurer le rendement. Pour que cette évaluation soit fiable, le sous-ensemble d'instances prédites choisi aux fins d'assurance de la qualité ne doit pas être biaisé. L'une des méthodes de sélection d'un échantillon non biaisé consiste à sélectionner au hasard une proportion précise d'instances à partir de chaque exécution du modèle prédictif. La figure 8 ci-dessous montre notre tableau de bord de suivi du rendement des modèles, qui présente différentes valeurs F1, de précision et de rappel pour des exécutions distinctes du modèle prédictif, qui peuvent être utilisées pour établir s'il y a eu dérive.
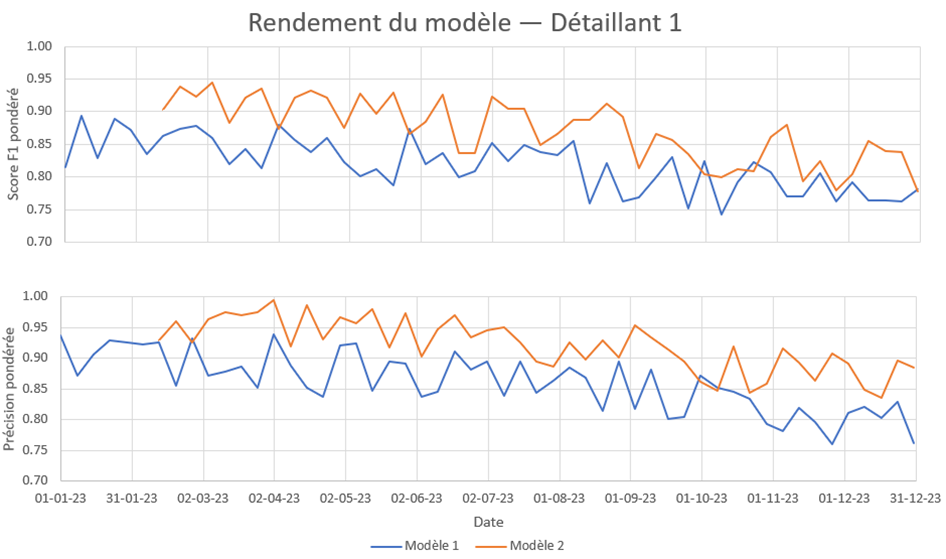
Description - Figure 8 : Tableau de bord de rendement des modèles présentant le rendement du modèle au fil du temps
Le rendement des modèles est suivi au fil du temps. Lorsque deux modèles sont déployés en production à l'aide d'un modèle principal et de modèles fantômes, il est possible de comparer le rendement.
Réentraînement des modèles
Le suivi du rendement au fil du temps a permis de constater une dérive des données dans les modèles de production; un processus est donc nécessaire pour en atténuer les répercussions dans le système des MLOps. L'une des options pour contrer la dérive conceptuelle consiste à réadapter périodiquement les modèles de production à l'aide de nouvelles données. Ce processus est lourd et fastidieux aux premiers stades de la maturité des MLOps. C'est pourquoi l'opérationnalisation du processus de réentraînement des modèles constitue un élément clé de la maturité des MLOps.
La figure 9 illustre le flux de nouveaux produits dans le système des MLOps. Les nouveaux produits ingérés dans le système de production sont automatiquement classés. Comme cela a été indiqué précédemment, une fraction des produits est sélectionnée pour que leurs classes soient vérifiées et corrigées manuellement par un annotateur formé. À partir d'un processus d'examen manuel, il est possible d'estimer les critères de rendement du classifieur. En outre, les produits vérifiés manuellement servent de nouvelles données d'entraînement qui peuvent être utilisées pour réentraîner le classifieur, qui est ensuite déployé en production.
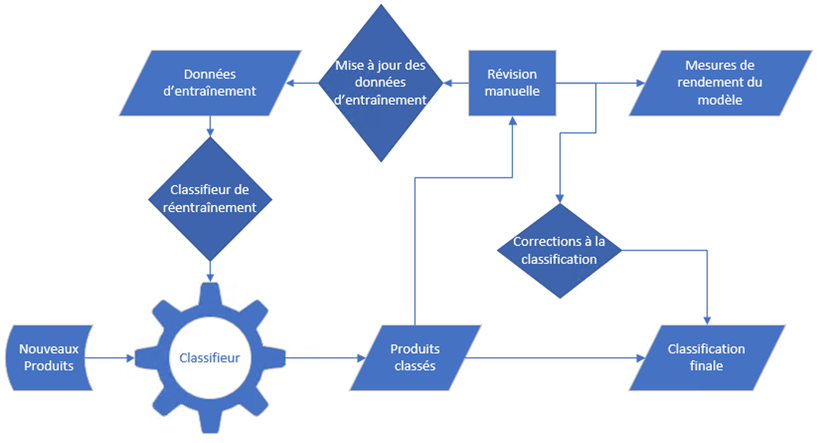
Description - Figure 9 : Processus de classification, d'exam en et de réentraînement
Une part des nouveaux produits est sélectionnée au hasard pour le réentraînement au fur et à mesure de leur classement. Le rendement du modèle est suivi sur cet ensemble aléatoire, et des données de réentraînement sont également créées à partir de cet ensemble de données. Des corrections sont aussi utilisées pour l'ensemble final. Elles peuvent être jumelées à d'autres méthodes de signalement pour s'assurer que des produits bien classés sont utilisés pour les statistiques de prix.
Ce processus de révision et de réadaptation reste cohérent entre les différents niveaux de maturité des MLOps. La différence réside dans l'automatisation du pipeline de réentraînement. Au dernier niveau de maturité, la mise à jour des données d'entraînement, la réadaptation du modèle et le déploiement du modèle sont entièrement automatisés; ils sont déclenchés soit par l'achèvement de l'étape de révision manuelle, soit selon un échéancier fixe.
Validation des données et contrôle des attentes
Les modifications de la qualité des données constituent un problème important pour le rendement des modèles et la qualité des extrants en production. En fait, les données sont devenues la partie la plus importante d'un projet de science des données (ère axée sur les données), car les architectures et les modèles sont facilement accessibles. Il est donc nécessaire d'établir un cadre et des méthodes appropriés en matière de qualité des données. Dans le contexte de l'AA, il est important d'harmoniser les vérifications de la qualité avec les attentes du scientifique de données qui crée les modèles. Un pipeline distinct de validation des données a été mis en place spécialement pour cette tâche. Il effectue des vérifications à l'aide du cadre en accès libre Great Expectations (GE) (Great Expectations Github (en anglais seulement)).
Le degré de souplesse et d'évolutivité de GE est élevé en ce qui concerne le type de contrôles pouvant être effectués et la création des attentes visant à permettre un contrôle de version aisé. GE produit également des rapports automatiques et faciles à lire sur la qualité des données à l'intention des spécialistes de domaine et des scientifiques des données. Ces rapports sont accessibles directement dans l'interface utilisateur d'Azure ML. Par ailleurs, GE fournit une bibliothèque d'extension des contrôles des attentes de validation des données prêts à l'emploi pour un déploiement et une réutilisation rapides dans différents ensembles de données, et offre de multiples options de connexion à diverses sources de données (fichiers CSV sur des lacs de données ou des serveurs de fichiers, bases de données, etc.). De plus, GE offre la possibilité de développer des suites d'attentes et des contrôles personnalisés, ce qui permet d'adapter les contrôles des attentes des concepteurs à des cas d'utilisation marginaux qui ne seraient généralement pas couverts par les méthodes de validation des données standard.
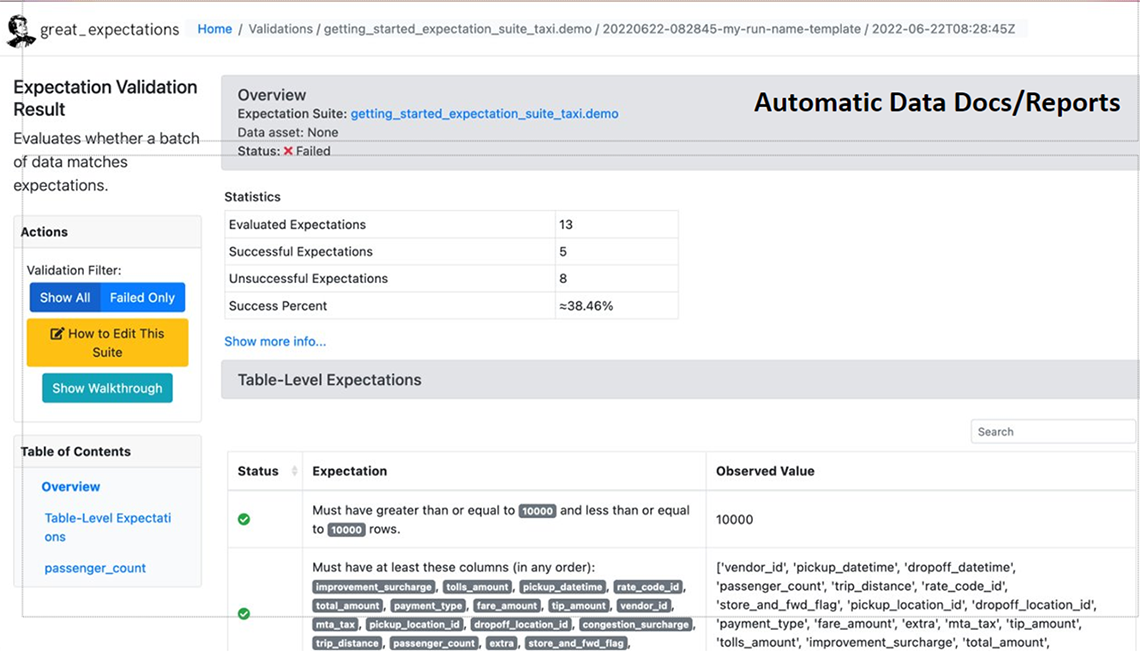
Description - Figure 10 : Rapport de validation des données de Great Expectations (en anglais seulement)
Cette image montre une application de l'extrant du progiciel Python Great Expectations, après qu'il a validé un ensemble de données précis. La page contient un résumé de la validation en haut à droite, un tableau plus détaillé des contrôles effectués, et la correspondance entre les attentes et ce qui a été réellement observé dans cet ensemble de données. Enfin, elle présente un ensemble de mesures pouvant être prises pour développer divers aspects de la page afin de fournir au scientifique des données des informations plus détaillées sur les contrôles effectués.
Contrôle des versions
L'utilisation appropriée du contrôle des versions (Contrôle de version avec Git pour les professionnels de l'analyse) est une condition essentielle pour un système de MLOps. Il s'agit d'une exigence importante dans le cadre de l'adoption à plus grande échelle de pratiques exemplaires en accès libre pour le développement de la production par les organismes nationaux de la statistique (Price et Marques, 2023). Pour le cas d'utilisation de l'AA, elle comprend non seulement le contrôle de version du code, mais aussi les versions des parties supplémentaires dans le cycle de vie de l'AA, y compris le contrôle de version des données, le contrôle de version de l'expérience et le contrôle de version du modèle. Pour obtenir une provenance et un historique fiables, il faut suivre les versions des différentes parties du processus. Par exemple, pour un modèle en production, on souhaite connaître les données sur lesquelles le modèle a été entraîné, le code d'entraînement utilisé, etc.
- Contrôle de version du code : Le système des MLOps utilise le contrôle qualité du code et les pratiques exemplaires d'IC/de DC. Il utilise plus particulièrement GitOps, qui définit le répertoire Git comme la source fiable et l'état du système adopté. Les pipelines et les déploiements sont définis de la même manière que le code.
- Contrôle de version des données : Le contrôle de version des données permet de retracer le modèle d'AA produit jusqu'à la version des données sur lesquelles il a été entraîné. Dans un processus de production appliqué aux données comprenant une arrivée fréquente de nouvelles données, il est également essentiel de garder une trace de la version des données. Les ensembles de données d'Azure ML sont utilisés pour répondre aux deux besoins.
- Contrôle de version du modèle : Le contrôle de version du modèle peut être simplifié par un entrepôt central de modèles, qui stocke les artefacts du modèle et assure la gestion de ses métadonnées. MLflow est l'outil en accès libre le plus connu pour la gestion de modèles. On utilise l'entrepôt de modèles d'Azure ML, car il permet d'interagir avec MLflow.
- Contrôle de version des dépendances des progiciels : Le contrôle de version des dépendances des progiciels se fait au moyen d'environnements virtuels et d'images de menu fixe dans lesquels les dépendances sont encapsulées. Les environnements Azure Container Registry et Azure ML sont utilisés pour gérer les dépendances des pipelines de données et des modèles d'AA.
- Contrôle de version des pipelines : L'exécution quotidienne de nombreux pipelines exige le contrôle de version des nouveaux pipelines publiés. On a recours au versionnage des pipelines d'Azure ML pour publier des pipelines et les gérer sous des points d'extrémité de pipeline.
- Versionnage du déploiement : Le versionnage du déploiement est géré au moyen de dépendances sur la version du modèle.
La figure 11 (ci-dessous) résume la manière dont ces différentes composantes sont associées pour former un graphique de l'historique des modèles déployés.
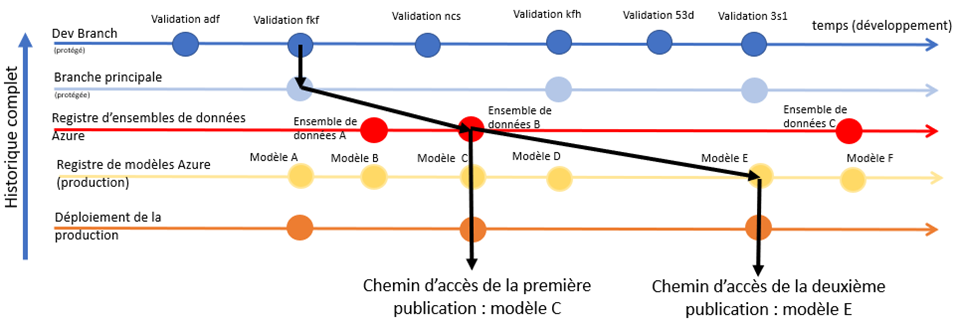
Description - Figure 11 : Graphique de l'historique des modèles déployés 11
Le diagramme résume la manière dont l'historique des modèles peut être géré. Tout d'abord, à partir de la branche principale, on prévoit une nouvelle publication et l'on crée une branche de publication. À partir de là, un nouvel ensemble de données est enregistré pour les modèles qui seront entraînés. Grâce à cet ensemble de données, plusieurs modèles peuvent être entraînés pendant le développement. Le modèle final peut être déployé en production et utilisé sur de nouvelles données. Si des expériences sont menées pour améliorer le modèle sur les mêmes données, ce nouveau modèle peut également être déployé, même si les données sur lesquelles il a été entraîné ou le code de la branche principale n'ont jamais été modifiés.
Conclusion
Cet article résume la manière dont le cadre des MLOps peut apporter une valeur considérable à un programme statistique essentiel de StatCan, en renforçant la maturité et la robustesse d'un processus de production en accord avec le Cadre pour l'utilisation responsable de l'apprentissage automatique à Statistique Canada (Utilisation responsable de l'apprentissage automatique à Statistique Canada). L'organisme continuera d'évaluer comment le cadre des MLOps peut être appliqué à d'autres cas d'utilisation et à investir dans l'expansion de capacités développées. Par exemple, les capacités suivantes sont à l'étude : tableaux de bord d'IA explicables dans le cadre de l'étape de choix des modèles dans le flux de travail de création des modèles; détection plus fiable de la dérive des données; déploiement plus explicite de modèles fantômes pour appuyer l'évaluation des modèles (ou simplement exécution permanente de modèles de sauvegarde en production, au besoin); suivi amélioré des coûts pour optimiser encore davantage l'utilisation opérationnelle.
Bibliographie
João, Gama, Žliobaitė Indrė, Albert Bifet, Mykola Pechenizkiy et Abdelhamid Bouchachia. (2014). A survey on concept drift adaptation (en anglais seulement). ACM computing surveys (CSUR), 46(4), 1-37.
Price, Matthew, et Diogo Marques. (2023). Developing reproducible analytical pipelines for the transformation of consumer price statistics: rail fares, UK (en anglais seulement). Meeting of the Group of Experts on Consumer Price Indices, Geneva: UN.
Sculley, David, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo et Dan Dennison. (2015). Hidden technical debt in machine learning systems. Advances in neural information processing systems (28).
Spackman, William, Greg DeVilliers, Christian Ritter et Serge Goussev. (2023). Identifying and mitigating misclassification: A case study of the Machine Learning lifecycle in price indices with web-scraped clothing data (en anglais seulement). Meeting of the Group of Experts on Consumer Price Indices, Geneva: UN.
Spackman, William, Serge Goussev, Mackenzie Wall, Greg DeVilliers, and David Chiumera. 2024. "Machine Learning is (not!) all you need: Impact of classification-induced error on price indices using scanner data." (en anglais seulement) 18th Meeting of the Ottawa Group. Ottawa: UNECE.
UN Task Team on Scanner Data. (2023). Classifying alternative data for consumer price statistics: Methods and best practices (en anglais seulement). Meeting of the Group of Experts on Consumer Price Indices, Geneva.