La date limite de soumission des résumés est passée. Merci à toutes les personnes qui ont transmis leur travail.
Dates à retenir
Début de la soumission des résumés : 8 juillet 2024
Fin de la soumission des résumés : 22 août 2024
Communication des résultats : 9 septembre 2024
Tenue de la conférence : 14 novembre 2024
Toutes les personnes qui présentent des affiches doivent être inscrites à la conférence. Elles doivent y assister en personne et rester près de leur affiche imprimée pendant les séances d'affichage.
Le programme de la conférence présente des approches novatrices et collaboratives de l'utilisation des données et de la recherche pour aborder les principaux défis en matière de santé. Il est divisé en quatre thèmes : mobilisation des données durant les situations d'urgence, santé de la population, soins préventifs, et environnement et santé. Du temps est également consacré au réseautage, notamment au moyen de présentations par affiches et de kiosques d'information, qui favorisent l'interaction directe entre les utilisateurs et les fournisseurs de données.
Présidente de la conférence : Josée Bégin, statisticienne en chef adjointe, Statistique Canada
Le jeudi 14 novembre 2024 :
Heure
Événement
De 8 h à 8 h 50
Inscription et installation des affiches
De 9 h à 9 h 15
Accueil et mot de bienvenue
André Loranger, statisticien en chef du Canada
Josée Bégin, statisticienne en chef adjointe, Statistique Canada
De 9 h 15 h à 10 h 30
Mobilisation des données durant les situations d'urgence
De 9 h 15 à 9 h 45
Thème central : Créer les conditions pour des communautés résilientes
Conférencière : Theresa Tam (administratrice en chef de la santé publique)
Description : Dre Theresa Tam abordera la façon dont la santé publique peut tirer parti des données pour améliorer l'équité, la résilience du système et l'intervention d'urgence. Elle présentera des stratégies de collaboration avec les communautés et les partenaires de divers secteurs afin de favoriser la santé et la résilience des communautés. Elle mettra l'accent sur le rôle de l'utilisation des données sur la santé publique pour améliorer l'équité en matière de santé, en plaçant l'équité au cœur de la science, des données probantes et de la technologie relatives à la gestion des urgences.
Introduit par : André Loranger, statisticien en chef du Canada
De 9 h 45 à 10 h
Séance 1 : L'Enquête canadienne sur les eaux usées : un nouvel outil de santé publique pour surveiller les maladies infectieuses
Conférencière : Natalie Knox (directrice, division des Pathogènes bactériens, résistance aux antimicrobiens et eaux usées, Agence de la santé publique du Canada)
Description : Natalie Knox discutera du partenariat entre l'Agence de la santé publique du Canada et Statistique Canada pour surveiller les maladies infectieuses au moyen de l'Enquête canadienne sur les eaux usées et de la façon dont elle est en train d'être élargie pour aborder les menaces en matière de santé publique existantes et à venir, comme la résistance aux antimicrobiens (RAM).
De 10 h à 10 h 15
Séance 2 : Médecins légistes et coroners : une source sous-exploitée de données dans le contexte de la crise des opioïdes et au-delà
Conférencier : Matthew Bowes (médecin légiste en chef, gouvernement de la Nouvelle-Écosse)
Description : Matthew Bowes décrira l'investigation médico-légale au Canada : la façon dont elle est habituellement menée, le type de décès faisant l'objet d'une enquête, la façon dont les pratiques varient et le type de données disponibles pour les chercheurs.
De 10 h 15 à 10 h 30
Période de questions
Animateur : Josée Bégin (statisticienne en chef adjointe, Statistique Canada)
De 10 h 30 à 11 h
Pause-santé, réseautage et visionnement des affiches et des kiosques
De 11 h à 12 h
Séance plénière : l'approche relative à la santé de la population
De 11 h à 11 h 15
Partie 1 : Tirer parti des données sur la santé de Statistique Canada, une ressource clé
Conférencier : Jeff Latimer (directeur général, Direction de la statistique de la santé de Statistique Canada)
Description : Au Canada, Statistique Canada est la source fiable de renseignements actuels et exacts au sujet de la santé des Canadiens, des déterminants de la santé et de l'utilisation de ressources en matière de soins de santé. Dans cette présentation, M. Latimer donnera un aperçu de l'étendue des données hébergées à Statistique Canada, de la façon d'accéder à ces données et des services disponibles pour personnaliser et coupler des données pour vos recherches.
De 11 h 15 à 11 h 30
Partie 2 : Données désagrégées : progrès et réflexions
Conférencière : Gayatri Jayaraman (directrice générale, Direction de la statistique juridique, de la diversité et de la population de Statistique Canada)
Description : Gayatri Jayamaran discutera des progrès de Statistique Canada dans le cadre du Plan d'action sur les données désagrégées (PADD), qui vise à augmenter et à améliorer les statistiques sur diverses populations et à soutenir des méthodes de collecte de données plus représentatives dans l'ensemble de Statistique Canada.
Discussions en séance plénière : Comment les systèmes de santé peuvent-ils utiliser les données désagrégées pour aborder les disparités en matière de santé?
De 11 h 30 à 11 h 35
Commentaires: Kwame McKenzie (PDG, Wellesley Institute; professeur, Université de Toronto) partagera ses connaissances sur les progrès et les défis liés aux données sur la santé fondées sur la race.
De 11 h 35 à 11 h 40
Commentaires: Danièle Behn Smith (administratrice en chef adjointe de la santé des Autochtones, Bureau de l'administrateur en chef de la santé publique de la Colombie-Britannique) partagera ses connaissances sur les progrès et les défis liés aux données sur la santé des Autochtones.
De 11 h 40 à 12 h
Discussion ouverte
Animatrice : Josée Bégin (statisticienne en chef adjointe, Statistique Canada)
De 12 h à 13 h
Dîner, réseautage et visionnement des affiches et des kiosques
De 13 h à 14 h 30
Application des connaissances pour alléger le fardeau de la maladie
De 13 h à 13 h 20
Séance 1 : Modélisation des effets de la politique nationale de nutrition sur l'alimentation et la santé
Conférencière : Mary L'Abbé (professeure, Université de Toronto, et directrice, Centre collaborateur de l'OMS sur la politique nutritionnelle pour la prévention des maladies chroniques)
Description : Santé Canada exige que les aliments et boissons préemballés dont la teneur en sodium, en sucres ou en gras saturés dépasse les seuils établis présentent un symbole nutritionnel « Élevé en » sur le devant de l'emballage, d'ici janvier 2026. Mary L'Abbé expliquera comment elle a utilisé les données de l'Enquête sur la santé dans les collectivités canadiennes – Nutrition et de l'Enquête sur les dépenses des ménages, appariées aux données sur la composition nutritionnelle, pour modéliser les effets potentiels de ce nouvel étiquetage sur l'alimentation et la santé.
De 13 h 20 à 13 h 40
Séance 2 : Utilisation de la cartographie à petite échelle des cancers évitables pour éclairer et renforcer la prévention du cancer
Conférencière : Nathalie Saint-Jacques (épidémiologiste principale, Programme de soins contre le cancer de Santé Nouvelle-Écosse; professeure auxiliaire, Université Dalhousie; associée de recherche, Healthy Populations Institute de l'Université Dalhousie)
Description : Nathalie Saint-Jacques discutera de ses recherches sur l'analyse à petite échelle de l'incidence du cancer par rapport aux conditions environnementales, matérielles et sociales dans lesquelles vivent les personnes, démontrant la façon dont une approche axée sur la géographie peut éclairer et renforcer des activités équitables de prévention du cancer.
De 13 h 40 à 14 h
Séance 3 : Projection de l'incidence de la démence : le modèle de santé de la population pour la démence (POHEM-démence)
Conférencière : Stacey Fisher (boursière postdoctorale, Institut de recherche de l'Hôpital d'Ottawa)
Description : Stacey Fisher discutera d'un modèle de microsimulation pour la démence qui a été élaboré pour étudier l'effet des facteurs de risque modifiables sur l'incidence de la démence et pour évaluer les stratégies d'interventions potentielles et les options stratégiques.
De 14 h à 14 h 30
Discussion de groupe : Réduire le fardeau de la maladie au Canada : obstacles et possibilités
Animateur : Michael Tjepkema, Directeur adjoint, Division de l'analyse de la santé, Statistique Canada
De 14 h 30 à 15 h
Pause-santé, réseautage et visionnement des affiches et des kiosques
De 15 h à 16 h 15
Environnement et santé (« Une santé unique »)
De 15 h à 15 h 30
Thème central : Prendre les devants sur la courbe des changements climatiques : la science pour soutenir l'adaptation du secteur de la santé
Conférencier : Peter Berry (analyste principal des politiques et conseiller scientifique, Bureau des changements climatiques et de la santé, Santé Canada)
Description : Peter Berry discutera de la science actuelle relative aux risques pour la santé, aux vulnérabilités et aux besoins en matière d'adaptation liés aux changements climatiques, dans l'espoir de favoriser à l'avenir les collaborations et les solutions novatrices.
Introduit par : Josée Bégin (statisticienne en chef adjointe, Statistique Canada)
De 15 h 30 à 15 h 45
Séance 1 : Examen de l'incidence de la chaleur extrême sur la santé : surmortalité et morbidité liées à la température à venir au Canada
Description : ÉricLavigne présentera son travail au moyen de l'analyse de séries chronologiques pour estimer les liens entre les températures quotidiennes et la mortalité ou les hospitalisations dans l'ensemble du Canada jusqu'en 2099, donnant un aperçu des résultats en matière de santé prévus selon divers scénarios de changements climatiques et de croissance de la population.
De 15 h 45 à 16 h
Séance 2 : Utilisation de données de biosurveillance humaine dans l'évaluation des risques pour la santé humaine des substances du Plan de gestion des produits chimiques
Conférencier : Innocent Jayawardene (évaluateur scientifique et chimiste, Santé Canada)
Description : Innocent Jayawardene parlera des points saillants d'une étude de Santé Canada mesurant 12 éléments, dont 5 métaux terreux rares, dans des échantillons de sang entiers au moyen de la biobanque de l'Enquête canadienne sur les mesures de la santé (ECMS), pour évaluer les risques pour la santé des substances du Plan de gestion des produits chimiques.
De 16 h à 16 h 15
Période de questions
Animatrice : Josée Bégin (statisticienne en chef adjointe, Statistique Canada)
De 16 h 15 à 16 h 30
Mot de la fin : Regard sur l’avenir
Josée Bégin, statisticienne en chef adjointe, Statistique Canada
Statistique Canada et l'Agence de la santé publique du Canada seront les fiers hôtes de la Conférence des utilisateurs de données sur la santé de 2024 qui se tiendra au Musée canadien de la guerre, à Ottawa, le 14 novembre.
Cet événement d'une journée en personne réunira 150 utilisateurs et utilisatrices, et fournisseurs et fournisseuses de données sur la santé, et son objectif sera d'explorer les façons novatrices et collaboratives dont les données sur la santé sont utilisées pour s'attaquer aux nouveaux problèmes de santé au Canada.
Les participants et participantes auront l'occasion :
d'entendre quelques-uns des principaux intervenants et intervenantes qui utilisent ou fournissent des données au Canada, y compris le statisticien en chef du Canada et l'administratrice en chef de la santé publique du Canada;
d'en apprendre davantage sur les données et les services de santé de Statistique Canada et sur la façon de les exploiter;
de participer à des discussions qui contribuent à façonner l'avenir des données sur la santé;
de rencontrer directement des personnes œuvrant dans tous les aspects du pipeline de données, de la conception à l'application, en passant par la collecte;
de présenter leurs recherches et d'échanger leurs idées.
Cette conférence s'adresse aux chercheurs et chercheuses et aux analystes de la santé, y compris la population étudiante. Elle s'adresse également aux utilisateurs finaux et aux utilisatrices finales, comme les décideurs et décideuses en matière de politiques et de programmes de santé, des organisations gouvernementales et non gouvernementales.
Si vous avez des questions ou souhaitez figurer sur notre liste de diffusion pour la conférence, veuillez envoyer un courriel à statcan.hduc-cuds.statcan@statcan.gc.ca.
Le Carrefour de la qualité de vie de Statistique Canada fournit d'importants renseignements sur la qualité de vie au Canada, en rassemblant des ensembles de données économiques, sociales et environnementales clés.
Centre de données municipales et locales
Le Centre de données municipales et locales permet aux Canadiens d'accéder facilement aux données sur leur localité et de mieux les comprendre, et aide les décideurs et les chercheurs à prendre de meilleures décisions à partir de ces données.
Dans son budget de 2023, le gouvernement du Canada a annoncé la création d'un programme national de soins dentaires qui sera mis en œuvre par Santé Canada, et il s'est engagé à financer l'administration de ce programme à concurrence de plus de 13 milliards de dollars. Parallèlement, Statistique Canada s'est vu octroyer 23,1 millions de dollars sur deux ans pour « recueillir des données sur la santé buccodentaire et l'accès aux soins dentaires au Canada », qui serviront de base à la mise en œuvre du nouveau Régime canadien de soins dentaires. Avec les fonds qui lui sont versés, Statistique Canada est en train de mettre au point un programme statistique robuste qui comprend la collecte de données sur l'état de santé buccodentaire autodéclaré des Canadiens et Canadiennes et sur leurs besoins en matière de soins buccodentaires, et la collecte de données sur l'état du système canadien de soins buccodentaires. De plus, l'organisme est en train d'effectuer les investissements nécessaires à la création d'une infrastructure qui permettra de mener à bien les activités de collecte au-delà de 2025.
Le nouveau Programme de la statistique sur la santé buccodentaire (PSSD) de Statistique Canada vise à combler les besoins en données sur la santé buccodentaire au moyen d'une stratégie globale et intégrée axée sur deux activités principales : la création de nouvelles enquêtes sur la santé buccodentaire ainsi que l'acquisition et l'intégration de données administratives connexes.
Dans le cadre de la création de ce nouveau programme statistique, Statistique Canada a lancé une série de séances de consultation auprès des principales parties prenantes. L'objectif était de mieux comprendre leurs préférences en ce qui concerne l'accès aux résultats du PSSD, le format des produits de diffusion, et les utilisations possibles des données du PSSD. Cette activité visait également à sonder les différentes parties de manière informelle pour évaluer leur connaissance des sources de données sur la santé buccodentaire et les soins de santé buccodentaire.
Méthodes de mobilisation consultative
Les consultations sur le PSSD ont été menées sous la forme de séances d'information virtuelles, lesquelles comprenaient des discussions de groupe avec un large éventail de parties prenantes du milieu de la santé buccodentaire. Ainsi, des gens issus d'organismes de réglementation, d'associations professionnelles, de réseaux de recherche et d'autres groupes ont pu formuler leurs commentaires. Les séances de mobilisation consultative se sont déroulées en deux phases, l'une au cours des deux premières semaines de décembre 2023 et l'autre au cours des deux dernières semaines de janvier 2024. Ces séances ont été diffusées sur la page Consultation des Canadiens de Statistique Canada. Par ailleurs, les différentes parties ont été personnellement invitées par courriel à participer aux séances, et à partager l'invitation avec d'autres membres de leur réseau. En plus de prendre part aux séances en mode virtuel, les participants et participantes ont eu la possibilité de nous communiquer leurs commentaires au moyen de formulaires électroniques et par écrit.
Dans l'ensemble, Statistique Canada a animé 10 groupes de discussion dans les deux langues officielles et a recueilli des commentaires auprès de 115 personnes représentant un total de 61 organisations des secteurs public et privé. Ces organisations — fournisseuses ou utilisatrices potentielles de données — comprenaient des établissements d'enseignement, des administrations municipales et provinciales ainsi que des associations professionnelles provinciales et nationales de toutes les professions de la santé buccodentaire. Des professionnels et professionnelles de la santé buccodentaire (dentistes, chirurgiens/chirurgiennes-dentistes, hygiénistes et thérapeutes dentaires, assistants/assistantes dentaires, technologues et techniciens/techniciennes dentaires) ont pris part aux discussions. Des organismes fédéraux et provinciaux de réglementation des soins buccodentaires y ont également participé.
Ce que nous ont dit les parties prenantes
Les capacités et l'expérience en matière d'analyse des données de santé buccodentaire variaient grandement d'une organisation à l'autre. Il est ressorti de nos consultations que les établissements d'enseignement, les associations professionnelles et les organismes gouvernementaux ont généralement des équipes spécialisées dans l'analyse des données, tandis que les petites entités, comme les organismes de réglementation, ont généralement une faible capacité d'analyse indépendante des données.
Au sujet des difficultés rencontrées dans l'écosystème actuel des données sur la santé buccodentaire, plusieurs ont soulevé les points suivants : ressources limitées pour effectuer des analyses; obstacles à l'accès aux données; ensembles de données incomplets en raison de l'absence d'intégration des données sur les demandes de règlement avec les dossiers de santé électroniques, les données sur les admissions à l'hôpital pour des problèmes de santé buccodentaire et les données des programmes de soins dentaires provinciaux; silos organisationnels; et fatigue liée à la participation aux enquêtes qui se traduit par de faibles taux de réponse. Malgré ces difficultés, la grande majorité des participants et participantes ont cité les retombées potentielles de l'utilisation des données du PSSD pour soutenir les efforts de sensibilisation et pour éclairer la prise de décisions stratégiques. Ils ont aussi souligné l'importance de permettre l'accès à des données agrégées faciles à analyser, ainsi que de garantir la possibilité de demander des ensembles de données précis au besoin. La plupart des organisations ont notamment déclaré ne pas mener leurs propres enquêtes sur la santé buccodentaire ou ne pas tenir de dépôts de données indépendants, choisissant plutôt d'utiliser de multiples sources de données externes. En résumé, les acteurs de la santé buccodentaire recherchent activement des données complètes et exploitables pour traiter efficacement d'enjeux clés et améliorer les résultats en matière de santé buccodentaire.
Statistique Canada tient à remercier toutes les personnes et organisations participantes de leur contribution à cette initiative de mobilisation consultative. Leurs points de vue et leurs expériences seront essentiels à l'élaboration de produits et de stratégies de diffusion de données pertinentes et actuelles pour aider les utilisatrices et utilisateurs de données.
La vidéo est une synthèse et une mise à jour des analyses diffusées par Statistique Canada dans la série des Portraits des minorités de langue officielle au Canada (Numéro au catalogue). Les portraits s'appuient sur une vaste gamme de statistiques tirées des recensements de la population et de l'Enquête sur la vitalité des minorités de langue officielle.
Par : Uchenna Mgbaja, Md Mahbub Mishu, Maryam Zamani, Sumitra Balamurugan et Aya Heba; NorQuest College
Selon le Recensement de 2021, il y avait 5 millions de ménages locataires au Canada, ce qui signifie qu'environ le tiers des ménages canadiens sont locataires. Une grande partie de cette activité de location se fait toutefois dans le secteur privé, ce qui donne lieu à des données limitées et incohérentes. Pour combler ces lacunes dans les connaissances, nous avons acquis, traité, analysé et représenté visuellement les annonces immobilières de la partie prenante, le Community Data Program (en anglais seulement), pour l'Ontario. Cet ensemble de données offre de nouvelles perspectives sur les tendances spatiales des marchés du logement métropolitain et des petites communautés, qui dépassent les autres sources disponibles en détail et en précision. Des villes comme Toronto, Brampton et Mississauga, par exemple, affichent des prix de location élevés par pied carré, ce qui témoigne de la dynamique économique de la région. Nous avons également analysé des régions de l'Ontario où la population est inférieure à 10 000 habitants.
La présente étude vise à répondre à trois objectifs principaux :
Interpréter les tendances des ensembles de données et leurs répercussions sur le marché du logement.
Appliquer des modèles d'apprentissage automatique aux ensembles de données afin que le modèle puisse prévoir les tendances futures.
Déployer le meilleur modèle.
Méthodologie
Nous avons obtenu de notre client un ensemble de données rigoureuses, lequel comprenait 18 colonnes donnant des précisions sur les régions, le nombre de chambres, les adresses et d'autres renseignements pertinents.
Pour extraire des renseignements précieux, nous avons utilisé des techniques de codage et des représentations visuelles, comme des tableaux et des graphiques. Cela nous a aidés à repérer avec succès des modèles essentiels dans la dynamique du logement, en particulier en cernant les régions présentant des différences notables dans les dépenses de logement et la densité des annonces.
L'analyse exploratoire des données
Pour l'analyse exploratoire des données (AED), nous avons sélectionné de petites collectivités en fonction du dénombrement de leur population. Cette approche nous a permis de mieux comprendre la dynamique du logement dans ces régions précises. La colonne « Prix » de notre ensemble de données contenait toutefois des incohérences, comme des signes de dollar et des virgules, ce qui la rendait difficile à analyser. Pour enrayer ce problème, nous avons supprimé les caractères spéciaux et converti la colonne au format numérique. Cela nous a permis d'effectuer des opérations numériques et de visualiser les données efficacement.
Ensuite, nous avons établi que certaines données des colonnes « Chambres » et « Salle de bain » contenaient des entrées complexes, comme « 2 + Den » (2 + pièce de détente), alors que la fonction regex ne tenait compte que des nombres, en ignorant la « Den » « pièce de détente » supplémentaire. Cela a conduit à des inexactitudes dans la représentation du nombre de chambres à coucher et de salles de bains. Pour résoudre ce problème, nous avons créé une colonne temporaire pour cerner les entrées « + Den » (+ pièce de détente ), converti « Chambres » et « Salles de bains » en valeurs numériques et ajusté les chiffres pour tenir compte de la partie « Den » (pièce de détente). Par la suite, nous avons supprimé la colonne temporaire, ce qui garantit un nombre précis de chambres pour chaque annonce immobilière.
La colonne « Taille » contenait des valeurs non numériques, comme « Non disponible », ce qui a entraîné des erreurs lors de la tentative de conversion de la colonne en type de données flottantes. Pour résoudre ce problème, nous avons remplacé les valeurs non numériques comme « Non disponible » par « NaN » (Not a Number, c'est-à-dire « pas un nombre ») en utilisant la fonction replace() de pandas.
Les entrées dans la colonne « Taille » qui étaient inférieures à 200 ou supérieures à 9 000 pieds carrés étaient considérées comme des données aberrantes et n'étaient pas logiques dans le contexte de la taille des propriétés. Si elles n'étaient pas traitées de manière appropriée, ces données aberrantes pouvaient fausser les résultats de l'analyse et de la visualisation.
Carte géographique des annonces immobilières en Ontario
Dans la présente section, nous avons utilisé le Looker Studio de Google pour générer des graphiques, des tableaux, des cartes, etc., ainsi que Plotly Express de Python pour les visualisations de l'ensemble des données.
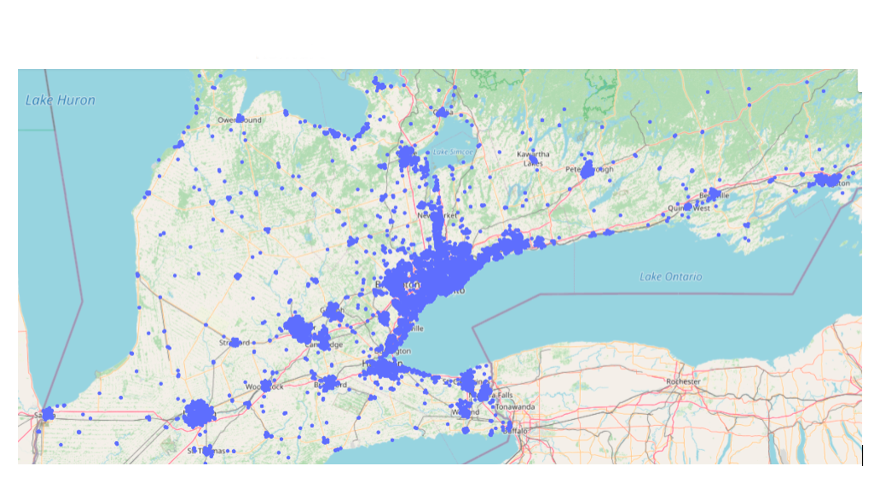
Description - Figure 1 : Génération de données géographiques à l'aide de Plotly.
Cette image montre une carte géographique du sud de l'Ontario et met en évidence la répartition des annonces immobilières relevées dans l'ensemble de données. Chaque annonce est représentée par un point distinct sur la carte.
Nous avons créé une carte de dispersion (présentée à la figure 1 ci-dessus) à l'aide de Plotly Express. Chaque point sur la carte représente une annonce immobilière. Nous avons choisi un style OpenStreetMap afin que la présentation soit plus claire et plus simple.
Histogramme représentant la répartition des prix de location
L'histogramme (présenté à la figure 2) permet aux utilisateurs de connaître la répartition des prix des loyers. Pour nous assurer que la visualisation est intuitive, nous avons conservé des étiquettes claires pour les axes et le titre et fourni une explication concise de ce que représente l'histogramme.
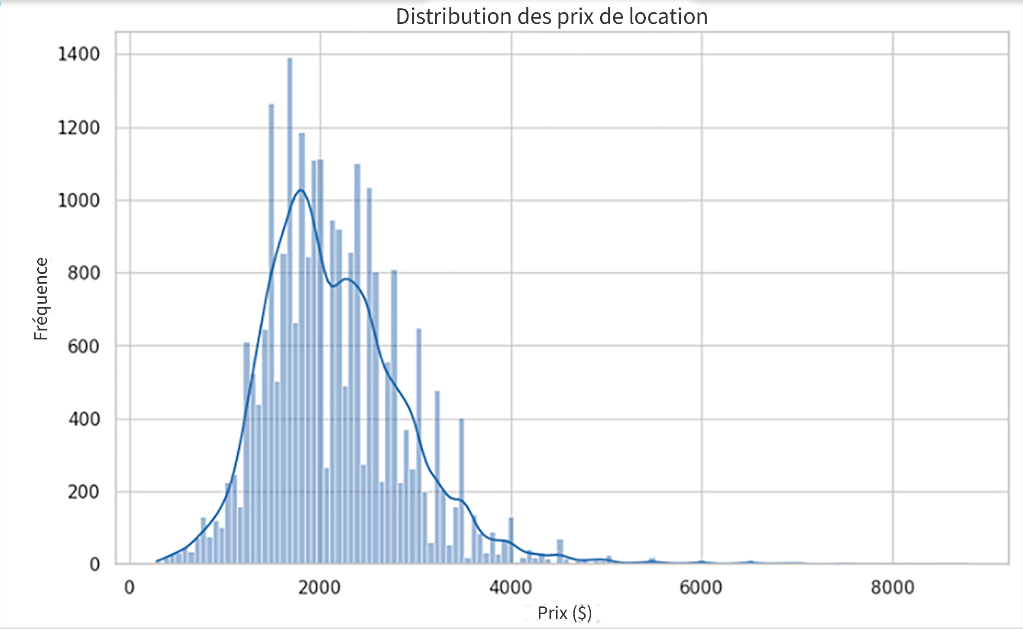
Description - Figure 2 : Histogramme illustrant la répartition des prix de location à partir d'un ensemble de données.
L'axe des x représente les prix de location en dollars, allant de 0 à 8 000 $, tandis que l'axe des y montre la fréquence des annonces à différents niveaux de prix. La répartition semble asymétrique à droite, ce qui indique que la plupart des annonces immobilières sont concentrées dans la fourchette de prix inférieure, celle-ci comportant moins d'annonces à des prix plus élevés.
Diagramme de dispersion représentant la taille et le prix associé au nombre de chambres
Le diagramme de dispersion (présenté à la figure 3) a permis aux utilisateurs de comprendre la relation entre la taille, le prix et le nombre de chambres à coucher dans un immeuble locatif. Les utilisateurs peuvent dégager des tendances, comme la variation des prix en fonction de la taille et du nombre de chambres.
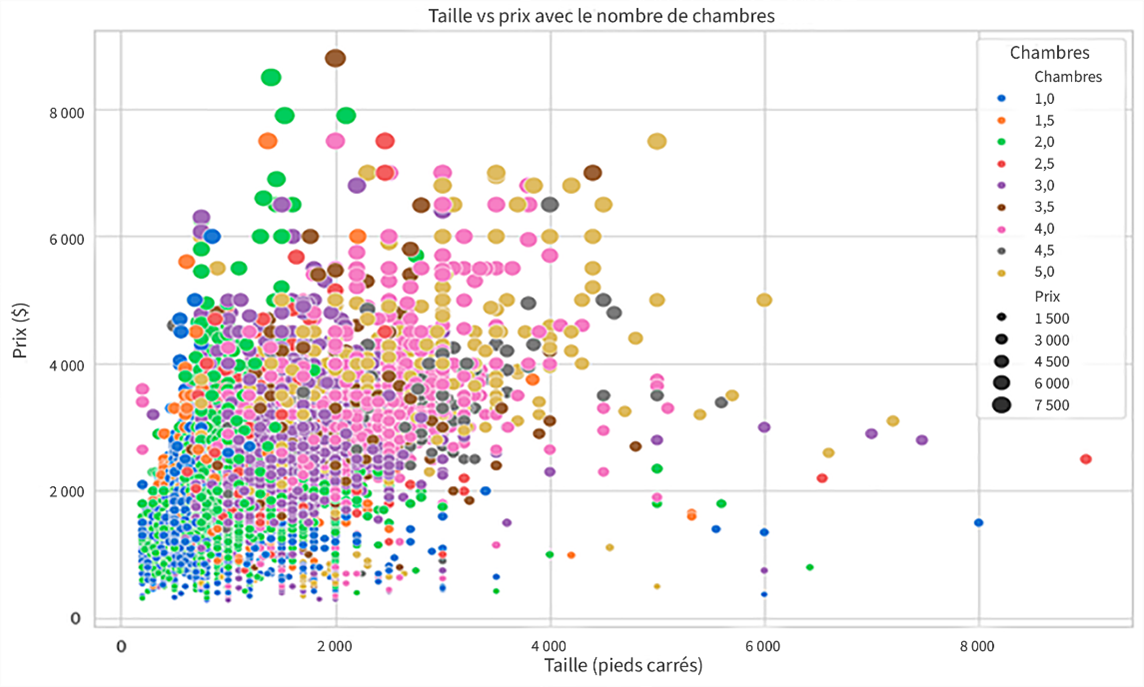
Description - Figure 3 : Diagramme de dispersion qui illustre la relation entre la taille d'une propriété et son prix de location.
Cette image représente un diagramme de dispersion qui illustre la relation entre la taille d'une propriété (en pieds carrés) et son prix de location (en dollars), alors qu'une autre dimension indique le nombre de chambres. L'axe des x représente la taille de la propriété, allant de 0 à 8 000 pieds carrés, et l'axe des y représente le prix, allant de 0 $ à plus de 8 000 $.
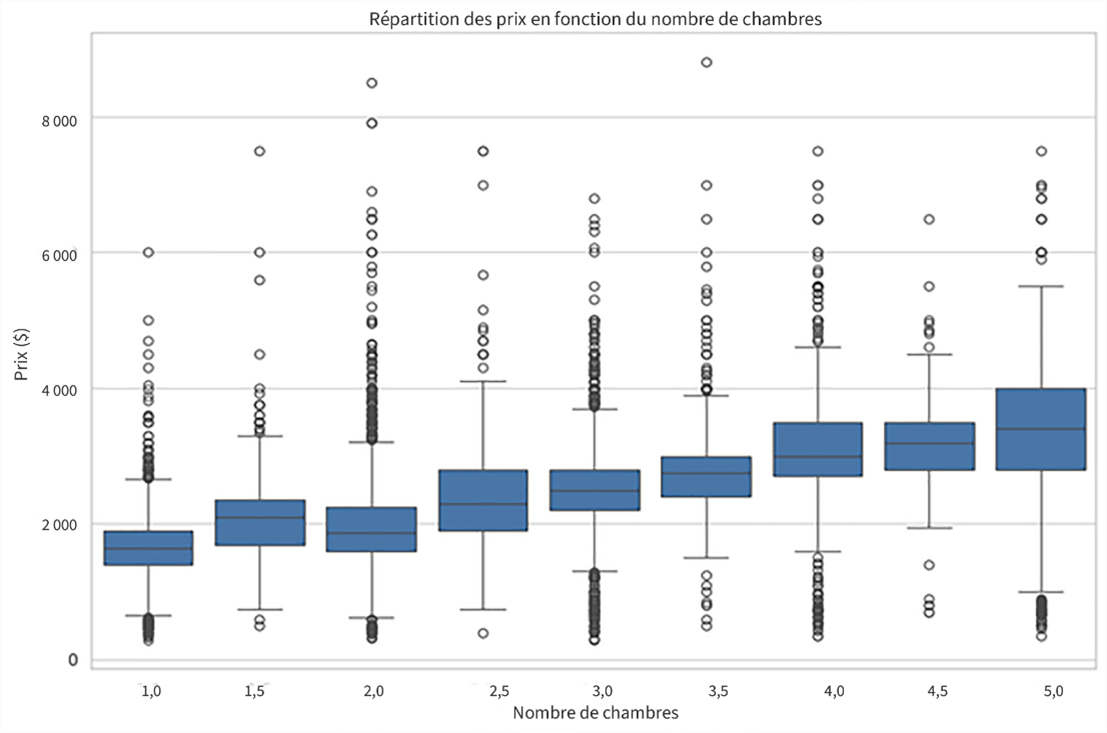
Diagramme à surface représentant la répartition des prix en fonction du nombre de chambres
Le diagramme à surface (présenté à la figure 4) permet aux utilisateurs de dégager les tendances de la répartition des prix en fonction du nombre de chambres. L'analyse des données aberrantes peut fournir des renseignements sur les propriétés exceptionnelles et les tendances du marché, ce qui aide les utilisateurs à prendre des décisions éclairées concernant les propriétés locatives ou d'investissement.
Description - Figure 4 : Répartition des prix en fonction du nombre de chambres.
Cette image présente la variation des prix de location selon différentes configurations de chambres. Chaque segment du diagramme à surface montre la médiane, les quartiles et les données aberrantes des prix de location, fournissant ainsi un résumé visuel de la façon dont le nombre de chambres influence les coûts de location. Les données aberrantes sont représentées par des points individuels au-dessus et au-dessous des cases, indiquant les variations par rapport aux prix de location typiques pour chaque catégorie.
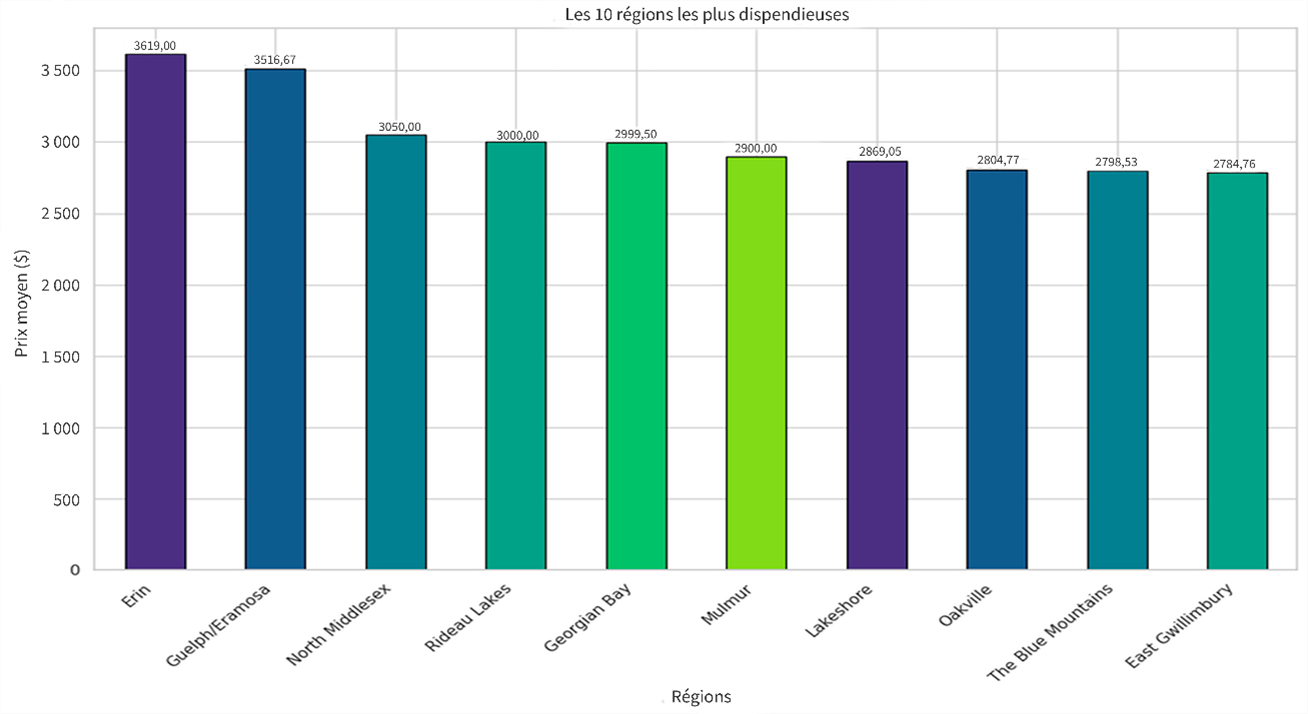
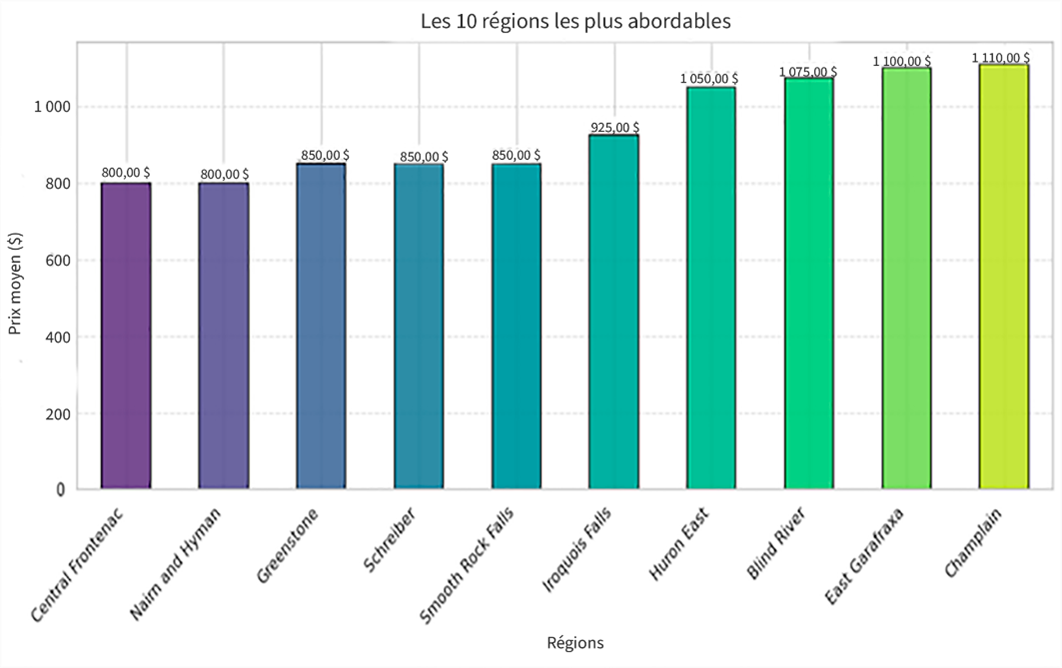
Diagramme à barres pour les 10 régions les plus dispendieuses et les plus abordables de l'Ontario
Les diagrammes à barres (présentés aux figures 5 et 6) donnent un aperçu de la répartition des prix par région, mettant en évidence les 10 régions les plus dispendieuses et les plus abordables. Les utilisateurs peuvent dégager des tendances, comme les disparités régionales dans les prix des loyers, et prendre des décisions éclairées en ciblant les régions où les prix moyens sont plus bas pour les occasions d'investissement.
Description - Figure 5 : Les 10 régions les plus dispendieuses.
Cette image montre les prix de location moyens dans diverses régions de l'Ontario. L'axe des y mesure le prix moyen en dollars, en montrant des valeurs qui vont de 0 $ à plus de 3 500 $.
Description - Figure 6 : Les 10 régions les plus abordables.
Cette image montre les prix de location moyens dans diverses régions de l'Ontario. L'axe des y mesure le prix moyen en dollars, en montrant des valeurs qui vont de 0 $ à 1 000 $.
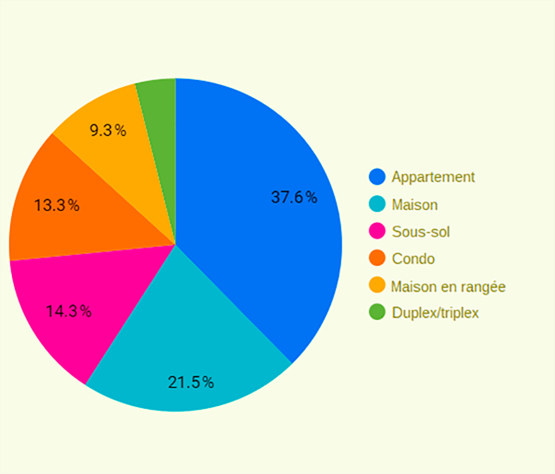
Le diagramme circulaire donne un aperçu de la répartition des types de propriétés
Le diagramme circulaire (présenté à la figure 7) donne un aperçu de la répartition des types de propriétés sur le marché locatif. Les utilisateurs peuvent cerner le type de propriété le plus répandu, comme les appartements, qui représente le pourcentage le plus élevé (37,6 %). Ces renseignements peuvent aider les utilisateurs à prendre des décisions éclairées, comme choisir les meilleurs types de propriétés pour les occasions d'investissement ou de location.
Description - Figure 7 : Graphique circulaire pour différents types de propriétés en Ontario.
Cette image montre un graphique circulaire illustrant la répartition des différents types de propriétés locatives disponibles dans un ensemble de données. Les segments du graphique sont codés par couleur et étiquetés, les pourcentages correspondants étant indiqués pour représenter la proportion de chaque type de propriété dans l'ensemble de données total.
L'application de l'apprentissage automatique aux données nettoyées
Pour prédire les prix de location, nous avons appliqué des modèles d'apprentissage automatique (AA) à notre ensemble de données. Nos données ne sont pas des séries chronologiques, car les annonces couvrent différentes dates, sans période de référence constante. Nous nous sommes plutôt concentrés sur des modèles de régression prédictifs afin de prédire les prix des loyers, qui est notre variable cible. Ces modèles nous ont aidés à analyser et à prédire les mouvements de prix en fonction de diverses caractéristiques comme l'emplacement, le type de propriété et les commodités.
Nous avons entraîné divers modèles d'apprentissage automatique, comme il est indiqué ci-dessous.
Les modèles de régression
Tout d'abord, nous avons divisé l'ensemble de données en ensembles de données d'entraînement et de test : 80 % pour l'entraînement et 20 % pour les tests. Cette approche a permis de s'assurer que le modèle était entraîné sur une partie importante des données, tout en conservant une partie importante pour les tests.
Ensuite, nous avons entraîné le modèle à l'aide de modèles de régression (le modèle de Random Forest, le modèle de régression linéaire et la méthode de Gradient Boosting) pour prédire les prix de location, qui étaient notre variable ou notre étiquette cible.
L'étape suivante consistait à effectuer une validation croisée. Pour ce faire, nous avons utilisé la technique de validation croisée « k-fold » pour évaluer les performances et la généralisation du modèle.
Enfin, nous avons évalué les modèles en fonction des mesures de performance suivantes :
La racine de l'écart quadratique moyenne (REQM) : Cette mesure métrique permet de mesurer l'ampleur moyenne des erreurs entre les valeurs prédites et les valeurs réelles. Plus la valeur de REQM est faible, meilleur est le modèle.
Le score du R au carré (R2) : Cette mesure métrique indique dans quelle mesure les prédictions du modèle de régression s'adaptent aux données réelles. Plus cette valeur est élevée, meilleure est la prédiction du modèle.
Les modèles de classification
Pour améliorer notre analyse, nous avons transformé le problème de régression en un problème de classification en fixant des seuils de prix. Plus précisément, nous avons classé les prix de location en trois groupes distincts : bas, moyen et élevé. Les seuils ont été choisis en fonction de la répartition des prix dans l'ensemble de données, en établissant des tranches allant de 0 à 1 500, de 1 500 à 2 500 et de plus de 2 500. Cette catégorisation nous a permis d'appliquer des modèles de classification, comme Random Forest (RF) et le modèle de l'arbre de décision, pour prédire les catégories de prix de location. Cette approche est soumise au point de vue de l'utilisateur sur ce qui est considéré comme un prix élevé ou bas.
Nous avons également élaboré des modèles de classification pour prédire le type de propriété locative en fonction de caractéristiques données. L'objectif était de recommander un type de propriété approprié en fonction des spécifications de l'utilisateur.
Les résultats
Les modèles de régression
Après avoir entraîné et évalué plusieurs modèles d'apprentissage automatique, il a été déterminé que, sur la base d'une évaluation comparative, le modèle de régression linéaire présentait des performances supérieures à celles des autres modèles de régression.
Tableau 1 : Performances des modèles AA.
Nom du modèle
REQM
R2
Régresseur Random Forest
483,05
0,6120
Régression linéaire
467,54
0,6568
Gradient Boosting
488,56
0,6372
Description - Tableau 1 : Performances des modèles AA.
Ce tableau établi une comparaison des performances de trois modèles d'apprentissage automatique (AA) différents à l'aide de deux mesures métriques : la racine de l'écart quadratique moyenne (REQM) et R2 (le coefficient de détermination). Le tableau répertorie les modèles suivants : le régresseur Random Forest, la régression linéaire et Gradient boosting. Les valeurs de la racine de l'écart quadratique moyenne (REQM) et du R2 sont fournies pour chaque modèle afin d'évaluer leur précision et leur pouvoir prédictif, respectivement. Le modèle de régression linéaire présente la REQM la plus faible à 467,54 et la valeur du R2 la plus élevée à 0,6568, ce qui indique qu'il est plus performant que les autres.
Les modèles de classification
Le tableau ci-dessous fournit une comparaison détaillée de trois modèles d'apprentissage automatique, à savoir la régression logistique, l'arbre de décision et Random Forest, utilisés pour classer les prix des propriétés locatives en différentes catégories en fonction de leurs caractéristiques. Les mesures prises en compte pour la comparaison sont les scores d'exactitude, de précision et de rappel obtenus par chaque modèle. Ces mesures sont cruciales pour évaluer l'efficacité et la fiabilité des modèles de prédiction des prix des logements locatifs.
Tableau 2 : les performances de différents modèles d'apprentissage automatique dans la classification des prix des logements.
Nom du modèle
Exactitude
Précision
Rappel
Régression logistique
0,73
0,81
0,81
Arbre de décision
0,73
0,77
0,80
Random Forest
0,74
0,79
0,80
Description - Tableau 2 : les performances de différents modèles d'apprentissage automatique dans la classification des prix des logements.
Ce tableau met en évidence les performances de différents modèles d'apprentissage automatique dans la classification des prix des logements. Le modèle de Random Forest a dépassé les autres modèles en ce qui concerne la précision, atteignant un score de 0,74. Les modèles de régression logistique et d'arbre de décision ont atteint le même score de précision de 0,73. En ce qui concerne la précision et la mémorisation, le modèle de régression logistique a obtenu le score le plus élevé de 0,81 : il serait donc légèrement meilleur pour déterminer les cas vraiment positifs. Cette comparaison fournit des renseignements précieux sur l'efficacité de ces modèles pour prédire les prix des logements locatifs et aide à sélectionner le modèle le plus approprié pour cette tâche.
Les méthodes de sélection des caractéristiques : les valeurs de p
Le concept de valeurs de p est fondamental en analyse statistique pour déterminer la signification des résultats observés. Dans les tests d'hypothèses, en particulier dans le contexte de la sélection de caractéristiques pour les modèles d'AA, les valeurs de p aident à évaluer la solidité de la preuve par rapport à une hypothèse nulle. Une valeur de p faible indique généralement que les données observées sont peu probables en supposant que l'hypothèse nulle est vraie, ce qui conduit au rejet de l'hypothèse nulle en faveur d'une autre hypothèse.
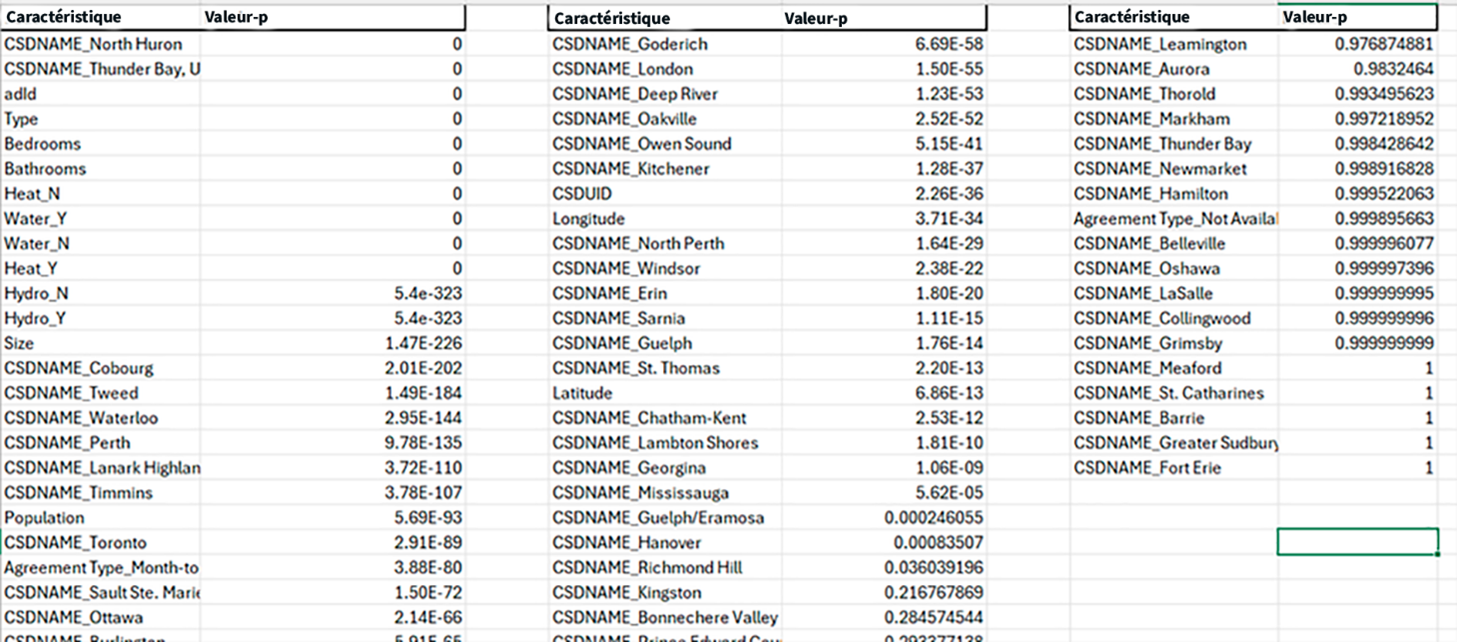
Description - Tableau 3 : Résultats de la valeur de p.
Ce tableau affiche les valeurs de p associées à différentes caractéristiques d'un ensemble de données, segmentées en trois colonnes distinctes pour plus de clarté. Chaque colonne répertorie des caractéristiques comme les noms géographiques, les attributs de propriété et d'autres facteurs. Les valeurs de p correspondantes indiquent la signification statistique de chaque caractéristique par rapport à la variable cible, à savoir le prix. Les caractéristiques dont les valeurs de p sont près de 0 indiquent une forte signification statistique, tandis que des valeurs plus près de 1 indiquent une faible signification. Ce format permet de cerner les facteurs ayant la plus forte influence sur les prix des loyers.
Dans les résultats présentés ci-dessus, le cadre de données présente les noms des caractéristiques à côté de leurs valeurs de p correspondantes dérivées du test F de l'ANOVA. Cette technique statistique vise à évaluer l'importance des caractéristiques individuelles concernant la variable cible « Prix ». Une valeur de p plus faible signifie une association plus forte entre la caractéristique et la variable cible, ce qui indique une probabilité plus élevée que la caractéristique soit pertinente pour prédire les prix des logements.
Fait à noter, des caractéristiques comme « Hydro_N », « Hydro_O », « Taille » et divers indicateurs géographiques présentent des valeurs de p extrêmement faibles, ce qui est à l'origine de leur incidence considérable sur la détermination des prix des logements.
La méthode de corrélation
L'analyse de corrélation est une technique statistique utilisée pour mesurer la force et la direction de la relation linéaire entre deux variables. Dans le contexte de la sélection de caractéristiques pour l'apprentissage automatique, l'analyse de corrélation permet de cerner les caractéristiques fortement corrélées à la variable cible et ayant une incidence considérable sur la prédiction de la cible. Un coefficient de corrélation est compris entre -1 et 1, où :
un coefficient de corrélation de 1 indique une relation linéaire positive parfaite, ce qui signifie que, lorsqu'une variable augmente, l'autre variable augmente également proportionnellement;
un coefficient de corrélation de -1 indique une relation linéaire négative parfaite, ce qui signifie que, lorsqu'une variable augmente, l'autre variable diminue proportionnellement;
un coefficient de corrélation proche de 0 sous-entend peu ou pas de relation linéaire entre les variables.
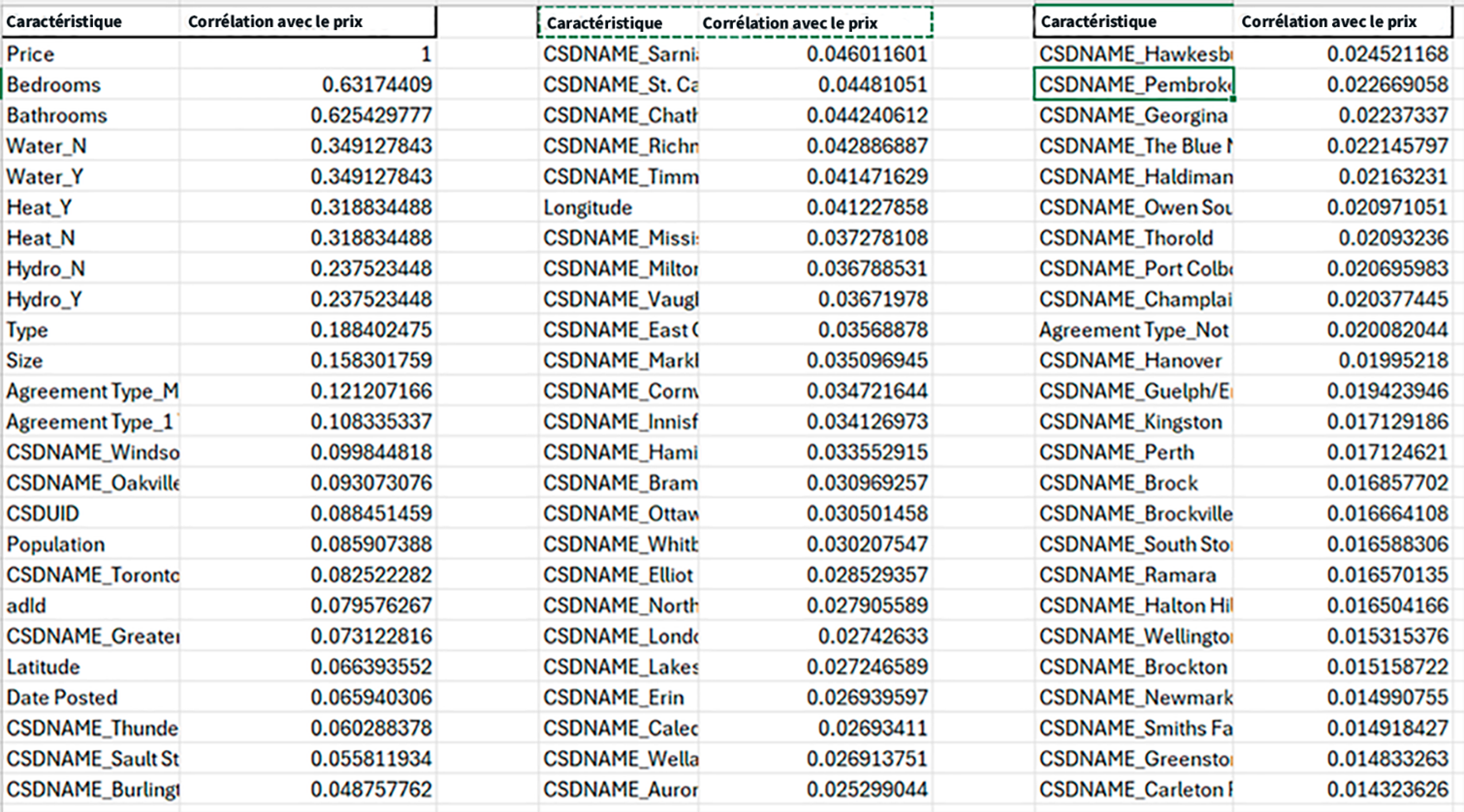
Description - Tableau 4 : La corrélation des prix.
Ce tableau présente les coefficients de corrélation entre diverses caractéristiques, y compris les emplacements géographiques (CSDNAME), les attributs des propriétés et d'autres variables pertinentes. Les valeurs de corrélation vont de -1 à 1, où les valeurs près de 1 ou -1 indiquent une forte corrélation positive ou négative avec les prix des loyers, respectivement, tandis que les valeurs près de 0 sous-entendent une corrélation faible ou nulle. Ce type d'analyse permet de comprendre quels facteurs sont les plus fortement associés aux variations des prix des loyers.
Dans les résultats ci-dessus, les coefficients de corrélation entre le « prix » (variable cible) et d'autres caractéristiques sont énumérés. Les « chambres » et les « salles de bains » ont des corrélations positives relativement élevées avec le « prix » (0,63 et 0,63, respectivement), ce qui indique que, lorsque le nombre de chambres ou de salles de bains dans une propriété augmente, le prix a tendance à augmenter également.
« Eau_O » et « Eau_N » ont le même coefficient de corrélation de 0,35, le « prix », ce qui donne à penser que la présence ou l'absence d'accès à l'eau pourrait influencer les prix des logements dans une certaine mesure.
Des caractéristiques comme « CSDNAME_South Frontenac », « CSDNAME_Norwich » et « CSDNAME_Chatsworth » ont de très faibles corrélations positives avec le « prix » (près de 0), ce qui indique de faibles relations linéaires entre ces indicateurs géographiques et les prix des propriétés. Nous avons pris des décisions éclairées pour ne conserver que les caractéristiques géographiques les plus pertinentes en fonction de l'expertise du domaine. Ce processus méticuleux de sélection des caractéristiques a contribué à un modèle d'apprentissage automatique plus rigoureux et plus efficace pour prédire les prix des propriétés.
Création de l'application Perspectives sur le logement locatif
La création de l'application Perspectives sur le logement locatif représente un effort global pour tirer parti des techniques de la science des données dans l'analyse des données sur les logements locatifs. Cette section présente le processus d'élaboration, les principales caractéristiques et l'incidence potentielle de la demande sur les parties prenantes et la collectivité.
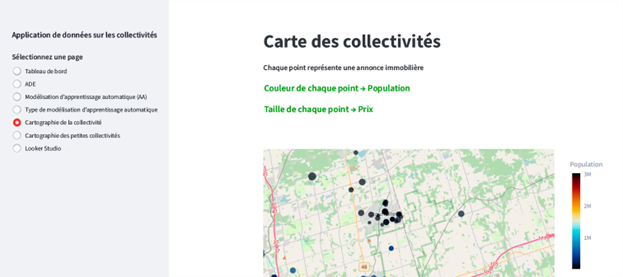
Description - Figure 8 : Application de données sur la collectivité.
Capture d'écran de l'interface de l'application de données sur a collectivité. Sur le côté gauche, il y a une barre latérale comportant l'option « Sélectionnez une page » où figurent plusieurs options, dont « Tableau de bord », « Analyse exploratoire des données », « Modélisation d'apprentissage automatique », « Modélisation d'apprentissage automatique (type) », « Cartographie de la collectivité», « Cartographie de petites collectivités » et « Looker Studio de Google ».
Développement de l'application
L'application est développée à l'aide du cadre Streamlit, en utilisant Python. Le processus de développement comporte plusieurs étapes clés :
Le prétraitement des données : nettoyage et formatage de l'ensemble de données sur les logements locatifs pour assurer la qualité et la cohérence des données.
L'ingénierie des fonctionnalités : création de nouvelles fonctionnalités et transformation des fonctionnalités existantes pour améliorer les performances et l'intelligibilité des modèles.
La modélisation d'apprentissage automatique (AA) : entraînement et évaluation de modèles prédictifs pour prévoir les prix des loyers et les types de propriétés.
La conception de l'interface utilisateur : conception d'une interface intuitive et conviviale pour assurer une navigation et une interaction fluides.
Les fonctionnalités
L'application Perspectives sur le logement locatif offre les principales fonctionnalités suivantes :
Le tableau de bord qui donne un aperçu des objectifs et des principales conclusions du projet.
L'analyse exploratoire des données (AED) qui permet aux utilisateurs d'étudier les données sur les logements locatifs grâce à des visualisations.
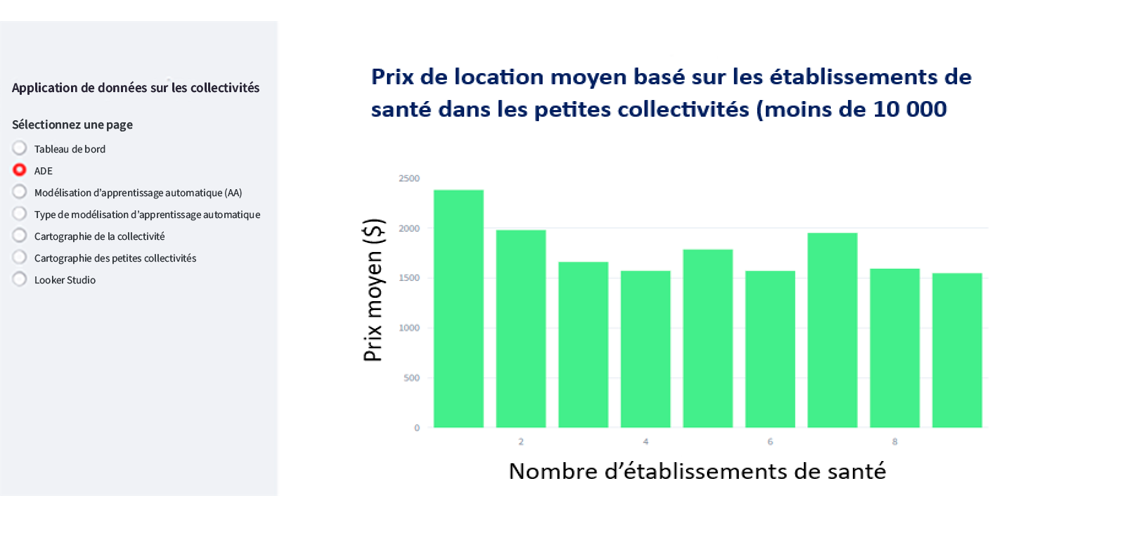
Description - Figure 9 : Sélection de l'AED à partir de l'application.
L'image montre un diagramme à barres intitulé « Prix de location moyen basé sur les établissements de soins de santé dans les petites collectivités (moins de 10 000 habitants) ». Le diagramme illustre les prix moyens des loyers dans diverses petites collectivités, soulignant l'incidence des établissements de soins de santé sur les coûts de location dans ces régions.
Modélisation AA : permet aux utilisateurs de prédire les prix de location et les types de propriétés en fonction des paramètres d'entrée.
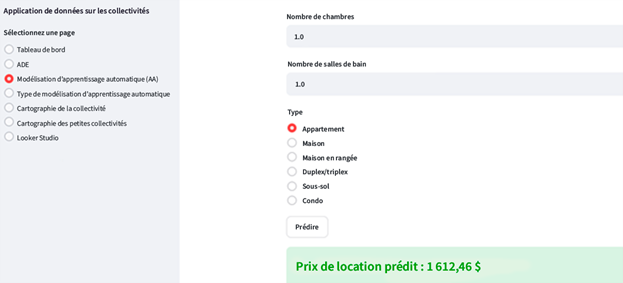
Description - Figure 10 : Application du modèle AA à l'aide de l'application développée.
L'interface affiche un module de prévision du prix de location. Les utilisateurs peuvent saisir des attributs comme le nombre de chambres (défini au point 1.0), de salles de bains (également défini au point 1.0), et sélectionner le type de propriété parmi des options comme « Appartement », « Maison », « Maison en rangée », « Duplex ou triplex », « Sous-sol » et « Copropriété ». Après avoir entré les renseignements, l'utilisateur peut cliquer sur le bouton « Prédire » pour générer une estimation du prix de location. La capture d'écran représente le résultat de ce processus; elle affiche un prix de location prévu de 1 612,46 $.
Profil des collectivités : affiche les annonces de logements locatifs sur des cartes, fournissant des renseignements spatiaux sur les tendances du marché.
Description - Figure 11 : Cartes tirées de l'application.
Cette image montre la page « Carte des petites collectivités de moins de 10 000 habitants ». La visualisation de la carte géographique représente les annonces de logements locatifs dans des collectivités dont la population est inférieure à 10 000. Chaque point sur la carte correspond à une annonce de propriété immobilière; la couleur indique la taille de la population, et la taille du point rend compte du prix du logement.
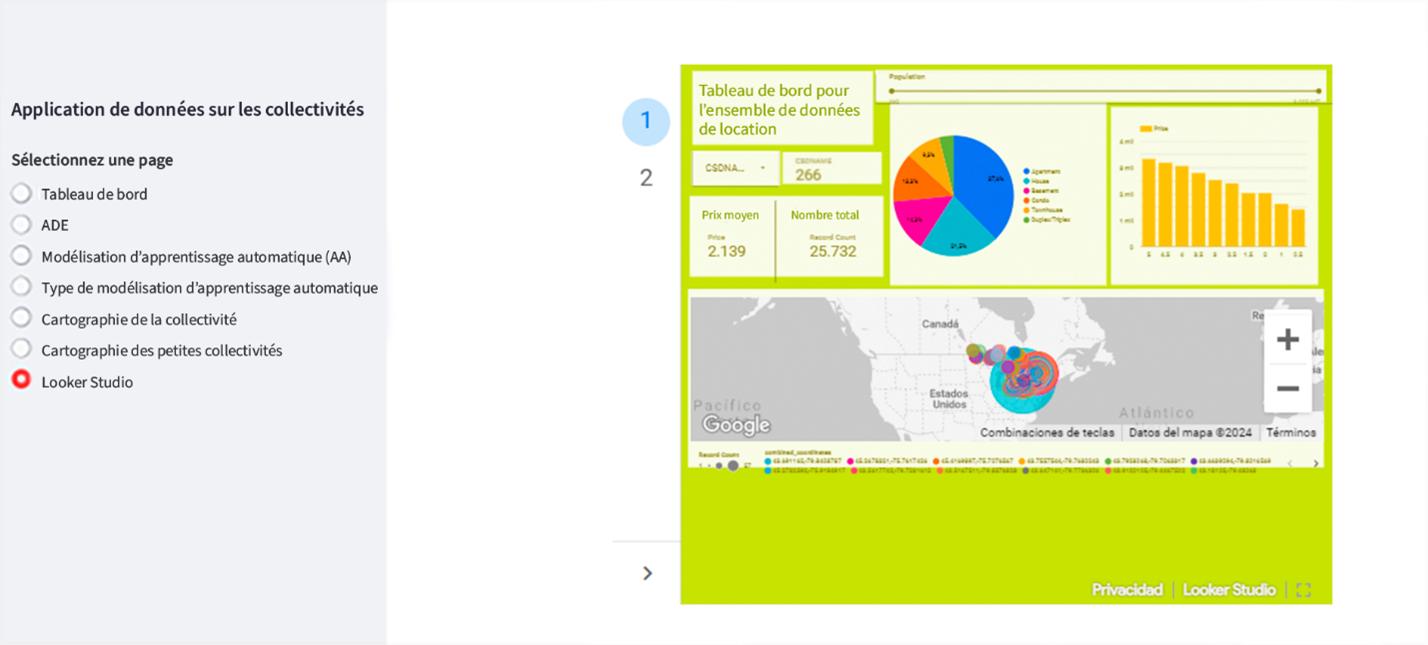
Intégration du Looker Studio de Google : intègre des renseignements et des rapports supplémentaires permettant une analyse et une visualisation améliorées.
Description - Figure 12 : Intégration du tableau de bord à l'application développée.
Cette image montre la visualisation intégrée du Looker Studio de Google. Cela permet aux utilisateurs de plonger profondément dans les données de l'application.
L'expérience utilisateur
L'application donne la priorité à l'expérience utilisateur en offrant une interface intuitive, des fonctionnalités interactives et des renseignements en temps réel. Les utilisateurs peuvent facilement naviguer entre les différentes parties, personnaliser les paramètres d'entrée et visualiser les résultats de manière dynamique et attrayante.
Les retombées et les avantages de l'application
L'application Perspectives sur le logement locatif pourrait avoir des retombées importantes sur les parties prenantes et la collectivité en :
fournissant des renseignements précieux sur les tendances et les modèles de logement locatif;
soutenant la prise de décision éclairée en matière d'investissements immobiliers et de gestion immobilière;
donnant aux utilisateurs des capacités d'analyse prédictive pour la planification stratégique et l'allocation des ressources;
améliorant la transparence et l'accessibilité des données sur le logement locatif pour les décideurs, les chercheurs et les organismes communautaires.
Les travaux à venir
L'étude offre une analyse détaillée du marché du logement locatif en Ontario, au Canada. En utilisant des techniques d'AED et d'AA, les auteurs fournissent des renseignements précieux sur les tendances spatiales, la dynamique du logement et les prévisions de prix des loyers, ce qui profite à la fois aux marchés métropolitains et aux petites collectivités.
Grâce à un nettoyage méticuleux des données, à l'ingénierie des caractéristiques et à l'application de divers modèles d'apprentissage automatique, l'étude met en lumière des aspects cruciaux comme la répartition des prix, les influences géographiques et les répercussions des attributs du logement sur les prix des loyers. Le développement d'une application Perspectives sur le logement locatif permet d'améliorer davantage l'exploration des données, la modélisation prédictive et la visualisation spatiale. Cela permet de fournir aux parties prenantes des renseignements utiles et exploitables, qui soutiennent une prise de décision éclairée sur le marché du logement locatif.
Dans l'ensemble, l'étude souligne le potentiel transformateur des approches axées sur les données pour relever des défis sociétaux complexes, comme le logement abordable, et souligne l'importance de la collaboration entre les parties prenantes du milieu universitaire, de l'industrie et du gouvernement pour apporter des changements positifs dans le paysage du logement locatif.
Bibliographie
Min, H., Wood, R., Seong-Jong, J. (2023). Machine Learning Methods and Predictive Modeling to Identify Failures in the Military Aircraft. International Journal of Industrial Engineering, 30(5), 1273-1283. 10.23055/ijietap.2023.30.5.8659
Belcastro, L., Carbone, D., Cosentino, C., Marozzo, F., Trunfio, P. (2023). Enhancing Cryptocurrency Price Forecasting by Integrating Machine Learning with Social Media and Market Data. Algorithms 2023, 16, 542. 10.3390/a16120542
Chaudhuri, T., Ghosh, I., Singh, P. (2017). Application of Machine Learning Tools in Predictive Modeling of Pairs Trade in Indian Stock Market. The IUP Journal of Applied Finance, Vol. 23, No. 1.



 Canada rural
Canada rural Cannabis
Cannabis Coronavirus
Coronavirus Don et bénévolat
Don et bénévolat Emploi du temps
Emploi du temps Participation communautaire
Participation communautaire Réseaux sociaux et personnels
Réseaux sociaux et personnels Sexe, genre et orientation sexuelle
Sexe, genre et orientation sexuelle