National monthly gross domestic product by industry, summary of Methods and data sources - 2023
| Code | Industry name | Type of indicators | Methods and data sources |
|---|---|---|---|
| 111X | Crop production (except cannabis) | Gross output | Crop output in constant prices, National Gross Domestic Product by Income and by Expenditure Accounts, Record no. 1901, Canadian Grain Commission. Farm cash receipts for field-grown vegetables and for greenhouse, nursery and floriculture production, Record no. 3437. Farm product price indexes, Record no. 5040. |
| 111CL | Cannabis production (licensed) | Gross output | Farm cash receipts, Record no. 3437. Farm product price indexes, Record no. 5040. Licensed producer cannabis market data, Health Canada. |
| 111CU | Cannabis production (unlicensed) | Gross output | Cannabis crop output in constant prices, Cannabis Economic Account, National Gross Domestic Product by Income and by Expenditure Accounts, Record no. 1901. |
| 112 | Animal production | Gross output | Farm cash receipts for most livestocks, dairy products and eggs, Record no. 3437. Farm product price indexes, Record no . 5040. Domestic exports quantities for animal aquaculture multiplied by base year prices, Record no . 2201. |
| 113 | Forestry and logging | Gross output | Cubic metres of cut timber multiplied by base year prices, Provincial Departments (Quebec, Ontario and British Columbia). |
| 114 | Fishing, hunting and trapping | Gross output | Annual estimates of fish landing quantities multiplied by base year prices from Fisheries and Oceans Canada are interpolated by domestic exports of fish, Record no . 2201. Raw materials price indexes, Record no . 2306. |
| 115 | Support activities for agriculture and forestry | Revenues and employment | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency. Average weekly earnings, Labour Force Survey, Record no . 3401, and Survey of Employment, Payrolls and Hours, Record no . 2612. Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 21111 | Oil and gas extraction (except oil sands) | Gross output | Physical quantities multiplied by base year prices, Crude oil and natural gas, Record no . 2198. |
| 21114 | Oil sands extraction | Gross output | Physical quantities multiplied by base year prices, Crude oil and natural gas, Record no . 2198. |
| 2121 | Coal mining | Gross output | Physical quantities multiplied by base year prices, Coal monthly, Record no . 2147. |
| 21221 | Iron ore mining | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. |
| 21222 | Gold and silver ore mining | Gross output | Physical quantities multiplied by base year prices. Monthly Mineral Production Survey, Record no . 5247. |
| 21223 | Copper, nickel, lead and zinc ore mining | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. |
| 21229 | Other metal ore mining | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. |
| 21231 | Stone mining and quarrying | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 21232 | Sand, gravel, clay, and ceramic and refractory minerals mining and quarrying | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 212396 | Potash mining | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. |
| 21239X | Other non-metallic mineral mining and quarrying (except potash) | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. |
| 213 | Support activities for mining and oil and gas extraction | Gross output | Metres drilled by province and rig operating days multiplied by base year prices. Mineral exploration expenditures, Income and Expenditure Accounts, Record no. 1901. |
| 2211 | Electric power generation, transmission and distribution | Gross output | Number of megawatt hours by province multiplied by base year prices, Monthly electricity, Record no . 2151. |
| 2212 | Natural gas distribution | Gross output | Physical volume of natural gas sales, by type of customer, multiplied by base year prices, Gas Utilities/Transportation and Distribution Systems (Monthly), Record no . 2149. |
| 2213 | Water, sewage and other systems | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 23A | Residential building construction | Gross output |
New construction investment in current prices by type of dwelling, Investment in building construction, Record no. 5014. |
| 23B | Non-residential building construction | Gross output |
New construction investment in current prices by type of non-residential building, Investment in building construction, Record no. 5014. |
| 23D | Repair construction | Gross output |
Renovation investment in current prices by type of dwelling and non-residential building, Investment in building construction, Record no. 5014. |
| 23X | Engineering and other construction activities | Employment and gross output | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. Expenditures on engineering structures, Income and Expenditure Accounts, Record no . 1901. |
| 3111 | Animal food manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3112 | Grain and oilseed milling | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3113 | Sugar and confectionery product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no. 2101. Industrial product price indexes, Record no. 2318 |
| 3114 | Fruit and Vegetable Preserving and Specialty Food Manufacturing | Gross output |
Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no. 2101. Industrial product price indexes, Record no. 2318. |
| 3115 | Dairy product manufacturing | Gross output | Physical quantities multiplied by base year prices, Monthly Dairy Factory Production and Stocks Survey (DAIR), Record no . 3430. Industrial product price indexes (IPPI), Record no. 2318. |
| 3116 | Meat Product Manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3117 | Seafood product preparation and packaging | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3118 | Bakeries and tortilla manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3119 | Other food manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 31211 | Soft drink and ice manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 31212 | Breweries | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3121A | Wineries, distilleries | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3122 | Tobacco manufacturing | Gross output | Physical quantities multiplied by base year prices, Production and disposition of tobacco products, Record no . 2142. Licensed manufacturers cannabis market data, Health Canada. |
| 31A | Textile and textile product mills | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 31B | Clothing and leather and allied product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3211 | Sawmills and wood preservation | Gross output | Physical quantities multiplied by base year prices, Sawmills, Record no . 2134. |
| 3212 | Veneer, plywood and engineered wood product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3219 | Other wood product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3221 | Pulp, paper and paperboard mills | Gross output | Physical quantities multiplied by base year prices, Pulp and Paper Products Council. |
| 3222 | Converted paper product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 323 | Printing and related support activities | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 32411 | Petroleum refineries | Gross output | Physical quantities multiplied by base year prices, Monthly refined petroleum products, Record no . 2150. |
| 3241A | Petroleum and coal products manufacturing (except petroleum refineries) | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3251 | Basic chemical manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3252 | Resin, synthetic rubber, and artificial and synthetic fibres and filaments manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3253 | Pesticide, fertilizer and other agricultural chemical manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3254 | Pharmaceutical and medicine manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3255 | Paint, coating and adhesive manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3256 | Soap, cleaning compound and toilet preparation manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3259 | Other chemical product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3261 | Plastic product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3262 | Rubber product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3273 | Cement and concrete product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 327A | Non-metallic mineral product manufacturing (except cement and concrete products) | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3311 | Iron and steel mills and ferro-alloy manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3312 | Steel product manufacturing from purchased steel | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3313 | Alumina and aluminum production and processing | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. Sales and inventory change in constant prices, Monthly Survey of Manufacturing (MSM), Record no . 2101. Industrial product price indexes (IPPI), Record no . 2318. |
| 3314 | Non-ferrous metal (except aluminum) production and processing | Gross output | Physical quantities multiplied by base year prices, Monthly Mineral Production Survey, Record no . 5247. Sales and inventory change in constant prices, Monthly Survey of Manufacturing (MSM), Record no . 2101. Industrial product price indexes (IPPI), Record no . 2318. |
| 3315 | Foundries | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3321 | Forging and stamping | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3323 | Architectural and structural metals manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3324 | Boiler, tank and shipping container manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3325 | Hardware manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3326 | Spring and wire product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3327 | Machine shops, turned product, and screw, nut and bolt manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3328 | Coating, engraving, heat treating and allied activities | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 332A | Cutlery, hand tools and other fabricated metal product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3331 | Agricultural, construction and mining machinery manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3332 | Industrial machinery manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3333 | Commercial and service industry machinery manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3334 | Ventilation, heating, air-conditioning and commercial refrigeration equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3335 | Metalworking machinery manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3336 | Engine, turbine and power transmission equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3339 | Other general-purpose machinery manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3341 | Computer and peripheral equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3342 | Communications equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3344 | Semiconductor and other electronic component manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 334A | Other electronic product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3351 | Electric lighting equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3352 | Household appliance manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3353 | Electrical equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3359 | Other electrical equipment and component manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3361 | Motor vehicle manufacturing | Gross output |
Physical quantities multiplied by base year prices, Motor Vehicle Manufacturers Association. As the summer holidays in this industry are taken in July-August according to production requirements, this approach prevents small changes in the pattern of these holidays to translate into large changes in the seasonally adjusted data. However, irregular events in July and August outside of summer holidays, for example a structural change such as the discontinuation of an existing vehicle model or the commencement of a new vehicle model, are treated separately such that the impact of irregular events is reflected in the month of occurrence. This treatment for irregular events in July and August can thus result in seasonally adjusted growth rates that are not equal in July and August. |
| 3362 | Motor vehicle body and trailer manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3363 | Motor vehicle parts manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3364 | Aerospace product and parts manufacturing | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 3365 | Railroad rolling stock manufacturing | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 3366 | Ship and boat building | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3369 | Other transportation equipment manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3371 | Household and instittutional furniture and kitchen cabinet manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3372 | Office furniture (including fixtures) manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3379 | Other furniture-related product manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3391 | Medical equipment and supplies manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 3399 | Other miscellaneous manufacturing | Gross output | Sales and inventory change in constant prices, Monthly Survey of Manufacturing, Record no . 2101. Industrial product price indexes, Record no . 2318. |
| 411 | Farm product wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. Commercial disappearance of Canadian grain (quantities), Canadian Grain Commission. Number of employees, Canadian Wheat Board. |
| 412 | Petroleum product wholesaler-distributors | Gross output | Physical quantities multiplied by base year prices, Monthly refined petroleum products, Record no . 2150. |
| 413 | Food, beverage and tobacco wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. |
| 414 | Personal and household goods wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. |
| 415 | Motor vehicle and parts wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. |
| 416 | Building material and supplies wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. |
| 417 | Machinery, equipment and supplies wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. |
| 418 | Miscellaneous wholesaler-distributors | Gross output | Deflated sales and margins, Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106, Annual Wholesale Trade Survey, Record no . 2445. |
| 419 | Wholesale electronic markets, and agents and brokers | Gross output | Deflated wholesale sales of groups 411 to 418, excluding 4151 (Motor vehicle wholesaler-distributors). Wholesale Trade Survey (Monthly), Record no . 2401, Wholesale Services Price Index, Record no . 5106. |
| 441 | Motor vehicle and parts dealers | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 442 | Furniture and home furnishings stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447. |
| 443 | Electronics and appliance stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 444 | Building material and garden equipment and supplies dealers | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 445 | Food and beverage stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 446 | Health and personal care stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 447 | Gasoline stations | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 448 | Clothing and clothing accessories stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 451 | Sporting goods, hobby, book and music stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 452 | General merchandise stores | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 453A | Miscellaneous store retailers (except cannabis) | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 453BL | Cannabis stores (licensed) | Gross output | Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447 |
| 453BU | Cannabis stores (unlicensed) | Gross output | Unlicensed cannabis sales and margins in constant prices, Cannabis Economic Account, National Gross Domestic Product by Income and by Expenditure Accounts, Record no. 1901. |
| 454 | Non-store retailers | Revenues and output | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency. Consumer price indexes adjusted for sales tax changes, Record no. 2301. Deflated sales, Retail trade survey (monthly), Record no. 2406. Margins, Retail trade survey (annual), Record no. 2447. |
| 481 | Air transportation | Gross output | Volume of passenger-kilometres and goods tonne-kilometres multiplied by base year prices, Air carrier operations in Canada quarterly survey, Record no . 2712. |
| 482 | Rail transportation | Gross output | Freight loaded on lines in Canada in tonnes multiplied by base year prices, Railway carloadings survey - monthly, Record no . 2732, and passenger revenues deflated by Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 483 | Water transportation | Revenues and output | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency. Industrial product price indexes, Record no . 2318, and average weekly earnings, Survey of Employment, Payrolls and Hours, Record no . 2612. Number of persons and vehicles carried by deep sea and coastal ferries by route multiplied by base year ticket prices, Marine Atlantic Inc. and BC Ferries. |
| 484 | Truck transportation | Other | Output in constant prices of the largest industries using trucking services. |
| 4851 | Urban transit systems | Gross output | Revenues of the largest urban transit systems, Record no . 2745, deflated by a Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 4853 | Taxi and limousine service | Revenues | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency, deflated by a Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 48A | Other transit and ground passenger transportation and scenic and sightseeing transportation | Output and employment | Revenues of interurban and rural bus transportation companies, Transportation Division, deflated by a Consumer price index adjusted for sales tax changes, Record no . 2301. Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 4862 | Pipeline transportation of natural gas | Gross output | Volume of cubic metre kilometres of natural gas transported multiplied by base year prices. Monthly Natural Gas Transmission Survey (MNGT), Record no . 2149. |
| 486A | Crude oil and other pipeline transportation | Gross output | Volume of cubic metre kilometres of crude oil and liquefied petroleum gases transported multiplied by base year prices, Monthly Energy Transportation and Storage Survey (METSS), Record no. 5300 |
| 488 | Support activities for transportation | Other and employment | Output in constant prices of selected industries and number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 491 | Postal service | Gross output | Canada Post revenues deflated by a Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 492 | Couriers and messengers | Revenues | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency, deflated by the Couriers and messengers services price index, Record no . 5064. |
| 493 | Warehousing and storage | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 511 | Publishing industries (except Internet) | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 512 | Motion picture and sound recording industries | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5151 | Radio and television broadcasting | Gross output | Radio and television advertising sales in constant prices, Television Bureau of Canada, Canadian Advertising Rates and Data and Canadian Association of Broadcasters. |
| 5152 | Pay and specialty television | Gross output | Number of subscribers by type of service multiplied by base year prices, Mediastats. |
| 517 | Telecommunications | Gross output | Number of subscribers by type of service multiplied by base year prices, Quarterly survey of telecommunications, Record no . 2721, including number of subscribers for cable, satellite and other program distribution services, local residential and business telephone services , mobile, high-speed internet service, and wired long-distance minutes. Canadian Radio-television and Telecommunications Commission, and Mediastats Inc.. |
| 518 | Data processing, hosting, and related services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 519 | Other information services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 52213 | Local credit unions | Gross output | Deflated revenues derived from assets and liabilities, Quarterly survey of financial statements, Record no . 2501, Bank of Canada, Record no . 7502, Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 52BX | Banking, monetary authorities and other depository credit intermediation | Gross output | Deflated revenues derived from chartered banks and trust companies assets and liabilities, stock market volume and mutual funds assets. Quarterly survey of financial statements, Record no . 2501, The Investment Fund Institute of Canada, Bank of Canada, Record no . 7502, Canadian stock exchanges and Consumer price index adjusted for sales tax changes, Record no . 2301. Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5222 | Non-depository credit intermediation | Gross output | Deflated revenues derived from assets and liabilities, Quarterly survey of financial statements, Record no . 2501, Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 5223 | Activities related to credit intermediation | Gross output | Deflated revenues derived from assets and liabilities, Quarterly survey of financial statements, Record no . 2501, Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 5241 | Insurance carriers | Gross output | Sales of insurance policies and revenues derived from investment expressed in constant prices, Quarterly survey of financial statements, Record no . 2501, LIMRA International, Bank of Canada, Record no . 7502, Consumer price indexes adjusted for sales tax changes, Record no . 2301. |
| 5242 | Agencies, brokerages and other insurance related activities | Gross output | Sales of insurance policies expressed in constant prices, Quarterly survey of financial statements, Record no . 2501, LIMRA International, Bank of Canada, Record no . 7502, Consumer price indexes adjusted for sales tax changes, Record no . 2301. |
| 52A | Financial investment services, funds and other financial vehicles | Gross output | Revenues derived from assets and liabilities, expressed in constant prices, and the volume of transactions on the Canadian stock exchanges, Bank of Canada, Record no . 7502, Balance of Payments Division, The Investment Fund Institute of Canada, Income Statistics Division, Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 5311 | Lessors of real estate | Gross output | Paid rental fees for housing, Income and Expenditure Accounts, Record no . 1901, rented surface of non-residential buildings, Colliers International. |
| 5311Y | Owner-occupied dwellings | Gross output | Owned and occupied housing stock, Income and Expenditure Accounts, Record no . 1901. |
| 531X | Offices of real estate agents and brokers | Gross output | Number of properties sold multiplied by base year prices, Canadian Real Estate Association. |
| 5321 | Automotive equipment rental and leasing | Employment and other | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. Passenger vehicle renting, Income and Expenditure Accounts, Record no . 1901. |
| 532A | Rental and leasing services (except automotive equipment) | Gross output | Operating income at constant prices, Quarterly survey of financial statements, Record no . 2501, Consumer price indexes adjusted for sales tax changes, Record no . 2301. |
| 533 | Lessors of non-financial intangible assets (except copyrighted works) | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5411 | Legal services | Gross output | Various indicators related to legal services, Canadian Centre for Justice Statistics Division, Office of the Superintendent of Bankruptcy Canada, Demography Division, Industry Canada, Canadian Real Estate Association, Canada Mortgage and Housing Corporation. |
| 5412 | Accounting, tax preparation, bookkeeping and payroll services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5413 | Architectural, engineering and related services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5414 | Specialized design services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5415 | Computer systems design and related services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5416 | Management, scientific and technical consulting services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5417 | Scientific research and development services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5418 | Advertising, public relations, and related services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5419 | Other professional, scientific and technical services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 55 | Management of companies and enterprises | Gross output | Operating income at constant prices, Quarterly survey of financial statements, Record no. 2501, Consumer price index adjusted for sales tax changes, Record no. 2301, Rented surface of non-residential buildings, Colliers International. Note: A downward statistical correction has been applied in the GDP estimates for this industry since the beginning of 2016 to gradually correct for the misclassification of several entities as holding companies. This downward statistical adjustment to the level of GDP has been offset by gradual upward statistical adjustments to industries in which those entities belong. In this context, the downward trend in GDP is not analytically meaningful but rather represents a statistical correction. |
| 5611 | Office administrative services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5613 | Employment services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5614 | Business support services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5615 | Travel arrangement and reservation services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5616 | Investigation and security services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 5617 | Services to buildings and dwellings | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 561A | Facilities and other support services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 562 | Waste management and remediation services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 6111 | Elementary and secondary schools | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 6112 | Community colleges and C.E.G.E.P.s | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 6113 | Universities | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 611A | Other educational services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 621 | Ambulatory health care services | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 622 | Hospitals | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 623 | Nursing and residential care facilities | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 624 | Social assistance | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 71A | Performing arts, spectator sports and related industries, and heritage institutions | Gross output and employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. Sporting event attendances (various sources). Canadian Pari-Mutuel Agency, Agriculture and Agri-Food Canada. Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency. Consumer price indexes adjusted for sales tax changes, Record no . 2301. |
| 7132 | Gambling industries | Gross output | Deflated revenues of provincial lottery corporations, Income and Expenditure Accounts, Record no . 1901. Consumer price index adjusted for sales tax changes, Record no . 2301. |
| 713A | Amusement and recreation industries | Employment | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 721 | Accommodation services | Revenues | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency, deflated by Consumer price indexes adjusted for sales tax changes, Record no . 2301. |
| 722 | Food services and drinking places | Gross output | Sales from the Monthly Survey of Food Services and Drinking Places, Record no . 2419, deflated by Consumer price indexes adjusted for sales tax changes, Record no . 2301. |
| 811 | Repair and maintenance | Revenues and employment | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency, deflated by Consumer price indexes adjusted for sales tax changes, Record no . 2301. Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. |
| 812 | Personal and laundry services | Revenues, employment and output | Revenues declared on the Goods and Services Tax remittance form, Canada Revenue Agency, deflated by Consumer price indexes adjusted for sales tax changes, Record no . 2301. Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. Number of deaths, Population estimates, Record no . 3601. |
| 813 | Religious, grant-making, civic, and professional and similar organizations | Employment and person-hours | Number of employees, Survey of Employment, Payrolls and Hours, Record no . 2612. Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 814 | Private households | Gross Output | Child care services in the home and other services related to the dwelling and property, Income and Expenditure Accounts, Record no . 1901. |
| 9111 | Defence services | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 911A | Federal government public administration (except defence) | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 912 | Provincial and territorial public administration | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 913 | Local, municipal and regional public administration | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |
| 914 | Aboriginal public administration | Person-hours | Hours-worked data, Labour Productivity Measures, Record no . 5042. |



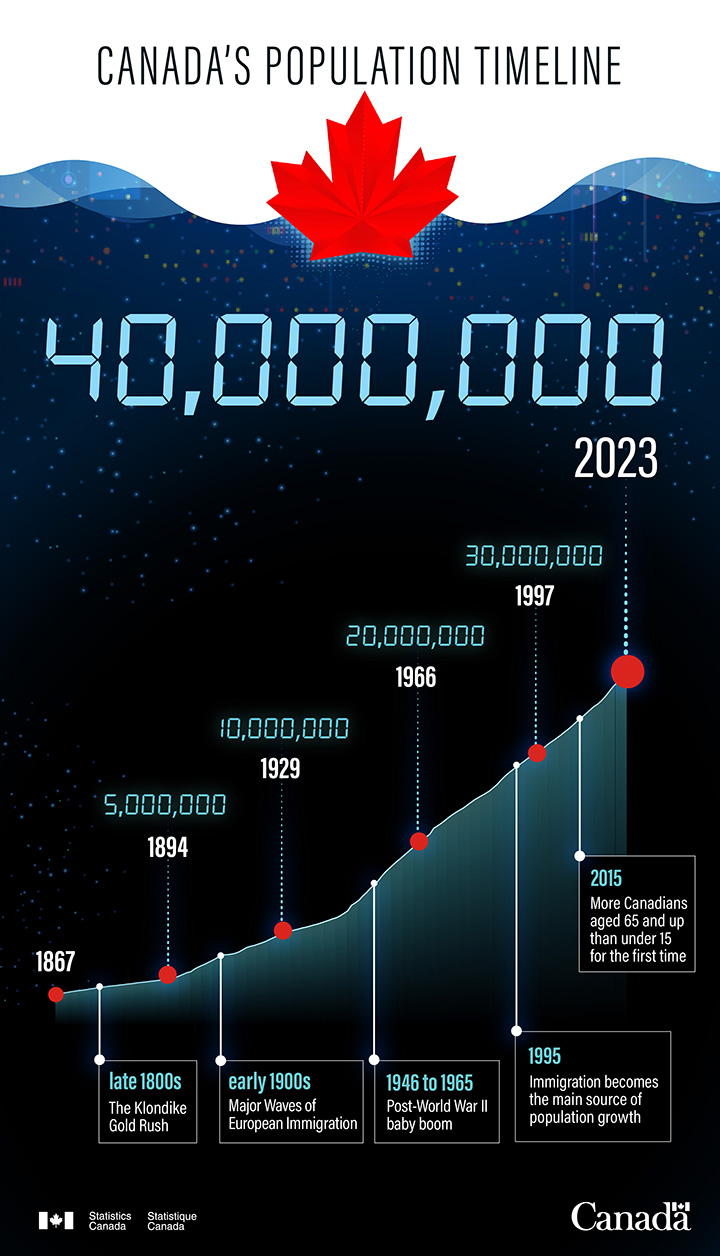
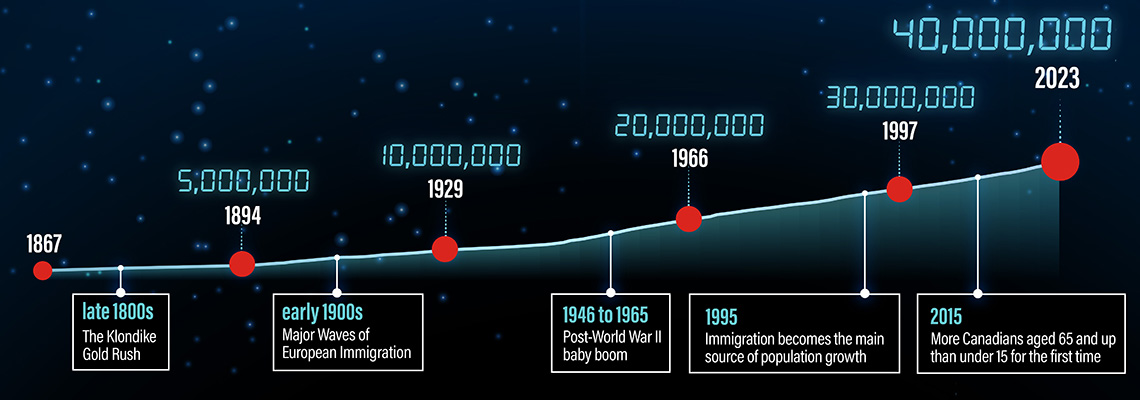
 Video - Canada by the million
Video - Canada by the million