Q1. Qu’est-ce que la Biobanque de Statistique Canada?
La Biobanque de Statistique Canada a pour but d’accélérer les futurs projets de recherche et de créer des possibilités de suivi de la santé sur un échantillon de Canadiens représentatif à l’échelle nationale. La biobanque reçoit des échantillons d’enquêtes telles que l’Enquête canadienne sur les mesures de la santé ou l’Enquête canadienne sur la santé et les anticorps contre la COVID-19, qui permettent de recueillir des échantillons de gouttes de sang séché, de sang, d’urine et de salive de plus de 22 000 Canadiens consentants. Ces échantillons sont entreposés en lieu sûr aux fins d’études futures sur la santé. Pour obtenir l’autorisation d’utiliser ces échantillons dans le cadre de projets de recherche, il est nécessaire de suivre un processus d’examen scientifique, éthique et relatif à la sécurité approfondi.
Voici les avantages qu’offrent les échantillons de la biobanque :
Ils offrent aux chercheurs un meilleur accès aux échantillons de Canadiens consentants;
Ils offrent un processus accéléré de recherche puisque les échantillons sont déjà accessibles aux fins d’analyse;
Ils aident les Canadiens à tirer parti des progrès réalisés dans les domaines de la science et de la médecine.
Q2. Où puis-je obtenir de plus amples renseignements sur la Biobanque de Statistique Canada?
Vous trouverez de plus amples renseignements, tels que les descriptions des études autorisées de la Biobanque de Statistique Canada, sur la page Web de la biobanque : Biobanque du Statistique Canada
Q3. Où les échantillons sont-ils entreposés?
Tous les échantillons de sang, de gouttes de sang séché, d’urine et de salive sont entreposés sans aucun renseignement personnel au Laboratoire national de microbiologie de l’Agence de la santé publique du Canada à Winnipeg, au Manitoba. Ces installations hautement sécurisées respectent les normes internationales de sécurité s’appliquant aux laboratoires. Les échantillons y sont entreposés conformément aux exigences strictes de Statistique Canada en matière de confidentialité.
Q4. Pendant combien de temps conserverez-vous mes échantillons?
Les échantillons sont entreposés dans la Biobanque de Statistique Canada jusqu’à ce qu’ils ne soient plus scientifiquement viables. Ils sont retirés de la biobanque lors de leur utilisation pour un projet de recherche approuvé ou sur demande d’un répondant à l’enquête pour qu’ils soient retirés et détruits.
Q5. Qu’arrive-t-il à mon échantillon lorsqu’il n’a plus de valeur scientifique?
Tous les échantillons qui n’ont plus aucune valeur scientifique sont détruits au moyen de protocoles normalisés de destruction de déchets biologiques. Des directives canadiennes sont en place pour gérer certains types de déchet, par exemple, les directives pour la gestion des déchets biomédicaux au Canada du Conseil canadien des ministres de l’environnement, qui sont suivies par la plupart des provinces et des municipalités.
Q6. Mes échantillons se dégraderont-ils avec le temps? Oui, les échantillons se dégradent avec le temps. Certaines mesures d’échantillon se dégradent plus vite que d’autres. Les échantillons seront conservés uniquement s’ils ont un mérite scientifique. Les chercheurs qui présentent une demande pour utiliser ces échantillons tiendront compte de l’âge de l’échantillon et des mesures pour les analyser dans leurs laboratoires avant de choisir les bons échantillons pour leur analyse.Q7. Dans quelles circonstances les chercheurs auront-ils accès à mes échantillons?
Les échantillons sont à la disposition des chercheurs canadiens qui satisfont aux exigences d’admissibilité, telles qu’elles sont décrites dans la politique d’accès à la Biobanque de Statistique Canada, qui se trouve sur la page Web de la Biobanque de Statistique Canada. Aux fins de respect de la vie privée et de la confidentialité, les chercheurs accèdent aux données produites par l’intermédiaire des centres de données de recherche de Statistique Canada répartis au Canada.
Statistique Canada donnera aux chercheurs un accès restreint aux échantillons (exempts de tout renseignement personnel) pour réaliser des tests et des études uniquement dans les circonstances suivantes :
Les chercheurs doivent utiliser les échantillons pour effectuer des analyses scientifiques d’intérêt national.
Les chercheurs doivent respecter des directives strictes en matière de confidentialité.
Le projet de recherche doit recevoir une aide financière par l’entremise d’un processus d’examen scientifique établi tel que celui de trois organismes (en anglais seulement) (Conseil de recherches en sciences naturelles et en génie du Canada, Instituts de recherche en santé du Canada ou Conseil de recherches en sciences humaines du Canada) ou d’organismes fédéraux.
Le projet doit être approuvé par un comité d’éthique de la recherche.
Le sommaire du projet doit être affiché sur le site Web de Statistique Canada Projets Biobanque.
Q8. Les participants peuvent-ils retirer leur consentement concernant l’entreposage de leurs échantillons biologiques dans la Biobanque de Statistique Canada?
Le consentement peut être retiré à n’importe quel moment. Les participants peuvent demander que leurs échantillons soient retirés de l’entreposage et détruits en composant le 1-888-253-1087, ou en envoyant un courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca.
Q9. Si j’ai participé lorsque j’étais enfant, mes échantillons seront-ils toujours entreposés lorsque j’atteindrai l’âge adulte?
Oui, car le consentement a été donné lorsque les échantillons ont été recueillis. Cependant, les participants peuvent demander — en tout temps — que leurs échantillons biologiques soient retirés et détruits de l’entreposage en faisant parvenir une demande écrite à Statistique Canada ou en envoyant un courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca. Lorsque l’enfant aura 16 ans, Statistique Canada enverra un nouvel avis de consentement aux coordonnées fournies.
Q10. Quels types d’analyses sont effectuées sur les échantillons entreposés dans la Biobanque de Statistique Canada?
Les échantillons entreposés dans la Biobanque de Statistique Canada sont utilisés dans les études sur la santé. Les études sur la santé comprennent ce qui suit :
recherches se penchant sur les expositions antérieures à de nouveaux contaminants environnementaux;
nouvelles façons de surveiller la nutrition humaine;
prévalence antérieure de maladies infectieuses et découverte et validation de nouveaux biomarqueurs pour diagnostiquer les maladies;
recherche génétique pour évaluer l’état de santé et la susceptibilité des Canadiens aux maladies, aux infections ou aux expositions à des contaminants environnementaux.
Vous trouverez des renseignements sur les projets antérieurs et actuels de la biobanque sur le page Web de la Biobanque de Statistique Canada Projets Biobanque.
Q11. Mes échantillons seront-ils utilisés pour effectuer des tests génétiques?
Oui, il est possible que votre échantillon soit utilisé pour effectuer des tests génétiques. Les tests génétiques pourraient comprendre des études d’association de génomes, ou génotypage.
Deux projets de la biobanque ont utilisé de l’information génétique des échantillons de la biobanque pour coupler des données génétiques à des résultats sur l’état de santé. Le premier projet, réalisé par l’Agence de la santé publique du Canada, s’est penché sur la mesure dans laquelle les différences dans le code génétique entre les Canadiens pouvaient influencer la manière dont ces Canadiens absorbaient les nutriments. Le second projet, en cours à l’Université McGill, étudie comment les différences dans le code génétique influencent les résultats en matière de santé après une exposition à des contaminants environnementaux et des métaux.
Statistique Canada ne divulguera jamais votre génome au public. Statistique Canada, comme tout autre ministère fédéral agissant conformément à la Loi sur la protection des renseignements personnels du Canada, ne permettrait jamais que votre ADN soit utilisé de cette façon.
Il est possible de retirer un consentement pour certains tests génétiques, tout en conservant vos échantillons dans la Biobanque de Statistique Canada pour d’autres projets. Un participant peut retirer son consentement à tout moment en utilisant les coordonnées suivantes :Participants de la biobanque
Q12. Y a-t-il des fins auxquelles mon ADN ne sera PAS utilisé?
Oui. L’utilisation des échantillons d’ADN est strictement limitée aux projets et aux demandes qui obtiennent l’approbation du Comité d’éthique de la recherche, ainsi que l’examen de faisabilité de Statistique Canada et l’approbation du Comité consultatif de la biobanque. Votre ADN ne sera pas utilisé ou partagé aux fins suivantes :
clonage
action en justice ou toute autre poursuite;
à des fins d’appartenance ancestrale ou de généalogie;
compagnies d’assurance ou employeurs.
Q13. Les participants reçoivent-ils les résultats des études menées? Statistique Canada n’a aucune responsabilité de produire une déclaration obligatoire des résultats, comme de déclarer des maladies génétiques. Cependant, les participants peuvent obtenir une copie de leurs résultats sur demande. Les demandes peuvent être faites en composant le 1-888-253-1087 ou en envoyant un courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca.Q14. Comment protégez-vous les renseignements personnels et la confidentialité des participants?
Tous les renseignements dans la Biobanque de Statistique Canada sont protégés par la Loi sur la statistique. Les échantillons de gouttes de sang séché, de sang, d’urine, de salive et d’ADN sont traités comme toutes les autres données recueillies par Statistique Canada. Lorsque les échantillons sont recueillis, les tubes d’entreposage passent à travers un processus complet et rigide d’étiquetage. Seuls les employés autorisés de Statistique Canada peuvent avoir accès à ces échantillons et aux renseignements des participants. En vertu de la Loi sur la statistique, les échantillons et les données de la Biobanque de Statistique Canada demeureront toujours protégés et confidentiels. Par exemple, jamais Statistique Canada :
ne procédera à l’entreposage ou à l’analyse d’échantillons de participants si ceux-ci n’y ont pas consenti dans le formulaire de consentement;
ne transmettra de renseignements sur les échantillons des répondants à un organisme d’exécution de la loi;
ne transmettra de renseignements ou de résultats de tests des répondants à des compagnies d’assurance ou des employeurs;
ne permettra que des renseignements ou des données relatives à des participants soient utilisés dans le cadre d’une action en justice ou de toute autre poursuite judiciaire.
Note de la rédaction : Le contenu de cet article représente la position de l’auteur, mais pas nécessairement celle de Statistique Canada.
Introduction
À l'ère numérique, les organisations recueillent et stockent de grandes quantités de données sur leurs clients, leurs employés et leurs partenaires. Ces données contiennent souvent des renseignements identificatoires personnels (RIP). Avec la multiplication des violations de données et des cyberattaques, la protection des RIP est devenue une préoccupation majeure pour les entreprises et les organismes gouvernementaux. Par exemple, Statistique Canada mène chaque année des centaines d'enquêtes sur un large éventail de sujets et est tenu de protéger les renseignements fournis par les répondants.
Le Canada dispose de deux lois fédérales sur la protection des renseignements personnels qui sont appliquées par le Commissariat à la protection de la vie privée du Canada :
Loi sur la protection des renseignements personnels : elle régit la manière dont le gouvernement fédéral traite les renseignements personnels. Cette loi protège les renseignements personnels, définit comme des renseignements enregistrés qui concernent une « personne identifiable ».
Loi sur la protection des renseignements personnels et les documents électroniques: elle est la loi fédérale sur la protection des renseignements personnels qui s'applique aux organisations recueillant, utilisant ou divulguant des données personnelles dans le cadre d'activités commerciales. Cette loi exige des organisations qu'elles obtiennent le consentement des personnes concernées par la collecte, l'utilisation ou la divulgation de données personnelles et qu'elles protègent les données personnelles contre l'accès, l'utilisation ou la divulgation non autorisés.
Outre les lois susmentionnées, l'ensemble des organisations doivent également respecter le Règlement général sur la protection des données (RGPD). Ce règlement est le plus strict au monde en matière de protection de la vie privée et de sécurité. Bien qu'il ait été rédigé et adopté par l'Union européenne (UE), il impose des obligations aux organisations, peu importe leur emplacement, lorsqu'elles ciblent ou recueillent des données relatives à des personnes dans l'UE. Le RGPR prévoit de lourdes amendes pour les organisations qui ne respectent pas ses normes en matière de protection des renseignements personnels et de sécurité, les sanctions pouvant atteindre des dizaines de millions d'euros.
Dans le présent article, nous présentons en détail Microsoft Presidio et la façon dont cet outil aide les organisations au Canada à se conformer aux lois en matière de protection de la vie privée. Nous abordons d'abord les principales fonctionnalités et capacités de Microsoft Presidio, puis la façon dont il peut aider les organisations à respecter leurs obligations en vertu de ces lois.
Définitions
Avant d’aborder le reste de l’article, il est important de comprendre la différence entre les termes « anonymisation », « dépersonnalisation » et « pseudoanonymisation » qui ont été utilisés.
Anonymisation : L’anonymisation s’entend du processus consistant à retirer ou à masquer de façon irréversible les renseignements identificatoires contenus dans les données de manière à ce que les données initiales ne puissent être réidentifiées. L’objectif est de rendre impossible ou extrêmement difficile le lien entre les données et la personne qu’elles représentent. Les données anonymisées ne devraient pas contenir d’identificateurs directs ou indirects qui pourraient être utilisés pour identifier des personnes.
Dépersonnalisation : La dépersonnalisation consiste à retirer ou à modifier les RIP d’un ensemble de données afin d’empêcher l’identification des personnes. Contrairement à l’anonymisation, la dépersonnalisation n’exige pas nécessairement que les données deviennent complètement non identifiables. Elle vise plutôt à supprimer ou à modifier des identificateurs précis, comme les noms, les adresses, les numéros de sécurité sociale ou toute autre information qui pourraient être utilisés seuls ou en combinaison avec d’autres données pour identifier des personnes.
Pseudoanonymisation : La pseudoanonymisation est une technique qui consiste à remplacer les identificateurs directs par des pseudonymes ou des identificateurs uniques, dissociant ainsi les données des personnes qu’elles représentent. Contrairement à l’anonymisation, où les données originales sont modifiées pour empêcher la réidentification, la pseudoanonymisation conserve la capacité de réidentifier des personnes à l’aide de renseignements supplémentaires stockés séparément, comme une clé ou un tableau de recherche. La pseudoanonymisation est couramment utilisée dans les situations où les données doivent être couplées entre différents systèmes ou bases de données tout en protégeant la vie privée des personnes.
Qu'est-ce que les RIPs?
Les renseignements identificatoires personnels (RIP) désignent les données qui peuvent être utilisées pour identifier une personne. Il s'agit notamment de noms, d'adresses, de numéros de téléphone, de numéros d'assurance sociale, de renseignements financiers, de dossiers médicaux, entre autres. Les RIP sont des renseignements de nature très délicate qui doivent être protégés contre tout accès non autorisé, car ils pourraient être utilisés dans le cas de vol d'identité ou d'autres activités frauduleuses.
Selon l'utilisation directe ou indirecte d'un renseignement pour réidentifier une personne, voici deux catégories dans lesquelles les renseignements susmentionnés peuvent être classés4 :
Identificateurs directs : ensemble de variables propres à une personne (nom, adresse, numéro de téléphone, compte bancaire) qui pourraient être utilisées pour identifier directement cette personne.
Quasi-identificateurs : renseignements tels que le genre, la nationalité ou la ville de résidence qui, pris isolément, ne permettent pas la réidentification d'une personne, sauf s'ils sont combinés à d'autres quasi-identificateurs et à des connaissances sur ses antécédents.
Pourquoi la protection des RIP est-elle importante?
La protection des RIP est importante parce que toute personne a droit au respect de sa vie privée et doit avoir un contrôle sur la façon dont ses renseignements personnels sont recueillis, utilisés et divulgués. Les violations de données et le vol d'identité peuvent avoir des répercussions importantes pour les particuliers, y compris des pertes financières, une atteinte à leur réputation et une détresse émotionnelle. Par conséquent, il est primordial pour les organisations de prendre des mesures rigoureuses pour protéger les RIP.
Contexte
a) Anonymisation des données structurées
Il existe des modèles mathématiques établis de protection de la vie privée permettant d'anonymiser les données structurées. Il s'agit notamment des modèles suivants :
K-anonymat : un ensemble de données masquées est considéré comme k-anonyme si, dans l'ensemble de données, chaque renseignement contenu pour une personne se confond totalement à au moins k-1 autres personnes. Deux méthodes peuvent être utilisées pour parvenir au k-anonymat : la première est la suppression, qui consiste à supprimer complètement la valeur d'un attribut d'un ensemble de données. La seconde est la généralisation, qui consiste à remplacer une valeur précise d'un attribut par une valeur plus générale.
I-diversité : il s'agit d'une extension du k-anonymat. Si nous assemblons des séries de rangées dans un ensemble de données qui ont des quasi-identificateurs identiques, il y a au moins « l » valeurs distinctes pour chaque attribut de nature délicate. Nous pouvons alors dire que cet ensemble de données présente une l-diversité.
Confidentialité différentielle : ce modèle vise à garantir que le résultat d'un processus ou d'un algorithme reste à peu près le même, que les données d'une personne soient incluses ou non. Cela signifie qu'il est impossible de déterminer avec certitude si une personne en particulier est présente dans l'ensemble de données simplement en examinant le résultat d'une analyse différentielle de la confidentialité.
Il existe plusieurs autres techniques d'anonymisation qui peuvent être appliquées aux données structurées et non structurées. En voici quelques-unes :
Mélange des données : consiste à réorganiser de manière aléatoire les rangées ou les colonnes d'un ensemble de données afin de perturber les éventuelles corrélations entre les variables.
Perturbation des données : consiste à ajouter du bruit ou des erreurs aléatoires aux données afin de réduire le risque de réidentification. Parmi les techniques pouvant être utilisées, mentionnons l'ajout de bruit gaussien ou l'arrondissement des valeurs au multiple le plus proche d'un certain nombre.
Agrégation des données : consiste à agréger les données à un niveau plus élevé, par exemple au niveau de la ville ou de l'État, afin de protéger les données individuelles.
Suppression des données : consiste à supprimer complètement les renseignements de nature délicate de l'ensemble de données, par exemple en supprimant des colonnes ou des rangées précises, ou en remplaçant les valeurs de nature délicate par une valeur de paramètre fictif (p. ex. « ****** »).
Généralisation des données : consiste à remplacer des valeurs précises par des valeurs plus générales, comme remplacer une adresse municipale précise par la ville ou l'État seulement.
Brouillage des données : consiste à remplacer des renseignements de nature délicate par des données fausses ou trompeuses, par exemple en générant des noms aléatoires ou de fausses adresses.
Il est essentiel de comprendre qu'aucune technique d'anonymisation n'est totalement infaillible. Par conséquent, il est généralement nécessaire d'utiliser une combinaison de techniques pour protéger efficacement les données de nature délicate. Il est également fondamental d'évaluer et de mettre à jour de façon continue les techniques d'anonymisation dès l'apparition de nouveaux risques et de nouvelles techniques de réidentification.
b) Anonymisation des données non structurées
Le processus d'anonymisation des données non structurées, comme le texte ou les images, est une tâche plus difficile. Il consiste à détecter l'endroit où se trouvent les renseignements de nature délicate dans les données non structurées, puis de leur appliquer des techniques d'anonymisation. En raison de la nature des données non structurées, l'utilisation directe de modèles simples fondés sur des règles pourrait ne pas donner de très bons résultats.
C'est pourquoi le traitement du langage naturel (TLN) a été appliqué à l'anonymisation du texte. Plus précisément, la reconnaissance d'entités nommées (REN), qui est un type de tâche d'étiquetage de séquences, est utilisée pour indiquer si un jeton (comme un mot) correspond à une entité nommée, comme PERSONNE (PER), EMPLACEMENT, DATE/HEURE ou une ORGANISATION (ORG), comme l'indique l'image ci-dessous. O indique qu'aucune entité n'a été reconnue.
Cette image décrit le résultat obtenu après le passage d’une séquence de chaînes de caractères dans un outil de reconnaissance d’entités nommées (REN). La chaîne de caractères « John a acheté 30 actions d’Amazon en 2022 » représente les données d’entrée. Après avoir passé la séquence dans un modèle de REN, chaque mot est classé selon son entité correspondante. John est désigné comme la personne (PER), Amazon comme l’organisation (ORG), 2022 comme la date (DATE/HEURE) et le reste des données comme les autres renseignements.
Plusieurs modèles neuronaux ont permis d'atteindre des résultats ultra-performants dans les tâches de REN sur des ensembles de données contenant des entités nommées générales. Des résultats aussi performants sont également obtenus lorsque ces modèles sont entraînés sur des données du domaine médical contenant divers types de renseignements personnels. Ces architectures de modèles comprennent des réseaux neuronaux récurrents (RNR) avec intégration de caractères (en anglais seulement) ou des transformateurs bidirectionnels (BERT) (en anglais seulement).
SpaCy (en anglais seulement) utilise également un modèle de langage qui repose sur RoBERTa, mis au point sur l'ensemble de données Ontonotes comprenant 18 catégories d'entités nommées, comme PERSONNE, EGP (entité géopolitique), CARDINAL, EMPLACEMENT, etc.
Microsoft Presidio utilise une combinaison de méthodes de TLN fondées sur des règles pour rendre anonyme le contenu de nature délicate dont nous parlerons plus loin.
Microsoft Presidio
Pourquoi avons-nous besoin de Microsoft Presidio?
Lorsque nous appliquons l'anonymisation des RIP à des applications réelles, il peut y avoir différentes exigences opérationnelles qui rendent difficile l'utilisation directe de modèles préentraînés. Par exemple, le gouvernement du Canada reçoit plusieurs demandes au cours d'un processus annoncé, des demandes qui sont ensuite examinées. Avant le processus d'examen, les RIP doivent être épurés afin d'éviter toute fuite de renseignements personnels et toute partialité. Outre les entités de RIP courants, le gouvernement utilise également un code d'identification de dossier personnel (CIDP) pour chaque employé, modulus-11 check digit (en anglais seulement) [Source : SCT - Dictionnaire d'éléments d'information des titulaires]
Un modèle de REN préentraîné ne peut pas détecter ces entités spéciales. Pour obtenir de bons résultats, il est nécessaire de mettre au point le modèle à l'aide de données auxquelles des étiquettes sont ajoutées. C'est pourquoi il est nécessaire de disposer d'un outil qui puisse utiliser un modèle de REN préentraîné et qui soit facilement personnalisable et extensible.
Presidio (du latin praesidium qui signifie « ce qui protège, défend ») permet de s'assurer que les données de nature délicate sont correctement gérées et administrées. Il fournit des modules d'identification et d'anonymisation rapides pour les entités privées dans le texte et les images telles que les numéros de cartes de crédit, les noms, les emplacements, les numéros de sécurité sociale, les portefeuilles de bitcoins, les numéros de téléphone américains, les données financières et bien plus encore.
L'un des principaux avantages du cadre Presidio est sa capacité à évoluer. Il peut traiter de grands ensembles de données, ce qui le rend apte à être utilisé par des organisations disposant de grandes quantités de données. Il est également conçu pour être flexible et adaptable, ce qui permet aux organisations de personnaliser son utilisation pour répondre à leurs besoins précis.
Description - Image 2 : Flux de travail pour la détection des RIP dans Microsoft Presidio
L’animation montre le flux de détection de Presidio qui est utilisé pour détecter les RIP. Une entrée passe par Regex qui effectue une reconnaissance des formes, suivie d’un algorithme de REN pour détecter les entités, d’une somme de contrôle pour valider les formes, de mots contextuels pour augmenter la confiance dans la détection et de plusieurs techniques d’anonymisation. L’image montre la séquence d’entrée : « Salut, je m’appelle David et mon numéro est 212 555 1234 ». Après avoir traversé le flux de détection Presidio, le prénom David et le numéro 212 555 1234 sont perçus comme des RIP.
Objectifs
Présenter les technologies de dépersonnalisation aux organisations d'une manière conviviale afin de promouvoir le respect de la vie privée et la transparence dans la prise de décisions.
Rendre la technologie flexible et personnalisable pour répondre à des besoins opérationnels précis.
Soutenir la dépersonnalisation entièrement automatisée et semi-automatisée des RIP sur plusieurs plateformes.
Principales caractéristiques
Permet de reconnaître les RIP à l'aide de diverses méthodes comme la reconnaissance d'entités nommées, les expressions normales, la logique fondée sur des règles et la somme de contrôle ainsi que le contexte pertinent, dans plusieurs langues.
Permet de se connecter à des modèles externes de détection des RIP.
Offre différentes options d'utilisation, notamment les charges de travail Python ou PySpark, Docker et Kubernetes.
Permet la personnalisation de l'identification et de l'anonymisation des RIP.
Comprend un module pour épurer les RIP sous forme de texte dans les images.
Modules principaux de Presidio
a) Presidio Analyzer :
(i) Vue d'ensemble
Presidio Analyzer est un service qui repose sur Python pour détecter les entités des RIP dans le texte. Au cours de l'analyse, il exécute un ensemble de différents reconnaisseurs des RIP, chacun étant chargé de détecter une ou plusieurs entités de RIP à l'aide de mécanismes différents. Presidio Analyzer est livré avec un ensemble de reconnaisseurs prédéfinis, mais il peut facilement étendre sa portée à d'autres types de reconnaisseurs personnalisés. Les reconnaisseurs prédéfinis et personnalisés tirent avantage de la reconnaissance d'entités nommées, des expressions normales, de la logique fondée sur des règles et de la somme de contrôle ainsi que du contexte pertinent dans plusieurs langues pour détecter les RIP dans un texte non structuré, comme présenté dans le flux de travail pour la détection ci-dessous.
Image 3 : Presidio Analyzer pour la détection des RIP [Source : Presidio Analyzer (en anglais seulement)]
Description - Image 3 : Presidio Analyzer pour la détection des RIP
L’image montre comment Presidio Analyzer est utilisé pour détecter les RIP. Le texte d’entrée passe par plusieurs reconnaisseurs de RIP, dont le reconnaisseur intégré, le reconnaisseur personnalisé et les modèles personnalisés. Le reconnaisseur intégré comprend les expressions normales (Regex), la somme de contrôle, la REN et les mots contextuels. Une fois que l’entrée de texte est passée par tous les reconnaisseurs, les RIP sont détectés.
Presidio Analyzer peut être installé (en anglais seulement) au moyen de pip, d'une image de menu fixe ou peut être construit à partir de la source.
(iii) Exécution d'un analyseur de base
Une fois l'installation terminée, un analyseur de base peut être exécuté avec quelques lignes de code, comme présenté ci-dessous :
from presidio_analyzer import AnalyzerEngine
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="Mr. John lives in Vancouver. His email id is john@sfu.ca", language='en')
print(results)
Par défaut, Presidio utilise le modèle en_core_web_lg de spaCy et peut détecter les entités suivantes : Entités prises en charge – Microsoft Presidio (en anglais seulement). Comme le montre le code ci-dessus, les entités PERSONNE, COURRIEL, EMPLACEMENT et URL ont été détectées. La portée de l'analyseur peut être étendue pour permettre la détection de nouvelles entités, comme nous le verrons plus loin.
(iv) Capacités de Presidio Analyzer
Permet la détection de nouvelles entités de RIP
Pour élargir les fonctions de détection de Presidio à de nouveaux types d'entités de RIP, des objets EntityRecognizer devraient être ajoutés à la liste actuelle des reconnaisseurs. Ces objets reposent sur Python et peuvent détecter une ou plusieurs entités dans un langage précis.
Le diagramme à catégories suivant montre les différents types de familles de reconnaisseurs compris dans Presidio :
Description - Image 4 : Diagramme à catégories pour les différents types de reconnaisseurs dans Presidio
L’image montre le diagramme à catégories pour les différents types de reconnaisseurs dans Presidio. EntityRecognizer est une catégorie abstraite pour tous les reconnaisseurs. RemoteRecognizer est une catégorie abstraite permettant de mobiliser des détecteurs de RIP externes. La catégorie abstraite LocalRecognizer est mise en œuvre par tous les reconnaisseurs fonctionnant au sein du processus de Presidio Analyzer. PatternRecognizer est une catégorie permettant de prendre en charge la logique de reconnaissance fondée sur les expressions normales (Regex) et les listes de rejet, y compris la validation (p. ex. avec la somme de contrôle) et la prise en charge contextuelle.
Dans le diagramme présenté ci-dessus :
EntityRecognizer est une catégorie abstraite pour tous les reconnaisseurs.
RemoteRecognizer est une catégorie abstraite permettant de mobiliser des détecteurs de RIP externes.
La catégorie abstraite LocalRecognizer est mise en œuvre par tous les reconnaisseurs fonctionnant au sein du processus de Presidio Analyzer.
La catégorie PatternRecognizer permet de prendre en charge la logique de reconnaissance fondée sur les expressions normales (Regex) et les listes de rejet, y compris la validation (p. ex. avec la somme de contrôle) et la prise en charge contextuelle.
Une façon simple d'étendre la portée de l'analyseur afin de détecter des entités de RIP supplémentaires peut se faire en deux étapes :
Créer une nouvelle catégorie selon EntityRecognizer.
Ajouter le nouveau reconnaisseur au registre correspondant pour qu'AnalyzerEngine puisse l'utiliser pendant l'analyse.
Exemple :
Pour les reconnaisseurs simples fondés sur des expressions normales ou des listes de rejet, nous pouvons tirer avantage de la catégorie PatternRecognizer fournie et mobiliser l'outil de reconnaissance comme le montre l'écran suivant :
from presidio_analyzer import PatternRecognizer
titles_recognizer = PatternRecognizer(supported_entity="TITLE", deny_list=["Mr.","Mrs.","Miss"])
titles_recognizer.analyze(text="Mr. John lives in Vancouver. His email id is john@sfu.ca", entities="TITLE")
[type: TITLE, start: 0, end: 3, score: 1.0]
Ensuite, nous pouvons l'ajouter à la liste des reconnaisseurs pour la détection d'autres entités de RIP :
from presidio_analyzer import AnalyzerEngine, RecognizerRegistry
registry = RecognizerRegistry()
registry.load_predefined_recognizers()
# Add the recognizer to the existing list of recognizers
registry.add_recognizer(titles_recognizer)
# Set up analyzer with our updated recognizer registry
analyzer = AnalyzerEngine(registry=registry)
# Run with input text
text="Mr. John lives in Vancouver. His email id is john@sfu.ca"
results = analyzer.analyze(text=text, language="en")
results
Pour des catégories EntityRecognizer plus complexes, comme la détection de CIDP pour le gouvernement du Canada, le reconnaisseur peut être créé dans le code en suivant les étapes suivantes :
Créer une nouvelle catégorie Python qui met en œuvre la catégorie LocalRecognizer (en anglais seulement) (LocalRecognizer met en œuvre la catégorie de base EntityRecognizer (en anglais seulement)). Cette catégorie comprend les fonctions suivantes :
charger : charger un modèle ou une ressource à utiliser lors de la reconnaissance
analyser : fonction principale à lancer pour extraire des entités du nouveau reconnaisseur.
L'ajouter au registre de reconnaisseur en utilisant registry.add_recognizer(my_recognizer). Pour obtenir plus d'exemples, consultez la section concernant la personnalisation de Presidio Analyzer (en anglais seulement) dans le bloc-notes Jupyter.
Il existe plusieurs autres façons de créer un reconnaisseur personnalisé dans Presidio, notamment :
Création d'un reconnaisseur à distance : Utilisation d'un reconnaisseur à distance, qui interagit avec un service externe pour la détection des RIP. Il peut s'agir d'un service tiers ou d'un service personnalisé fonctionnant parallèlement à Presidio.
Création de reconnaisseurs ponctuels : Création de reconnaisseurs ponctuels à l'aide de l'interface de programmation d'applications (API) de Presidio Analyzer. Ces reconnaisseurs, au format JSON, peuvent être ajoutés à la requête /analyse et ne sont utilisés que pour cette requête précise.
Lecture de reconnaisseurs de formes à partir de fichiers YAML : Lecture de reconnaisseurs de formes à partir de fichiers YAML, ce qui permet aux utilisateurs d'ajouter une logique de reconnaissance sans écrire de code. Vous trouverez un exemple de fichier YAML ici: Example Recognizers (en anglais seulement). Une fois le fichier YAML créé, il peut être chargé dans RecognizerRegistry.
2. Prise en charge multilingue
Presidio peut détecter les RIP dans plusieurs langues à l'aide de ses reconnaisseurs et modèles intégrés. Par défaut, il comprend des reconnaisseurs et des modèles en anglais. Toutefois, ces reconnaisseurs dépendent de la langue, soit par leur logique, soit par les mots contextuels utilisés pour rechercher des entités.
Pour améliorer les résultats pour des langues précises, il est possible de mettre à jour les mots contextuels des reconnaisseurs existants ou d'ajouter de nouveaux reconnaisseurs qui prennent en charge des langues supplémentaires. Chaque reconnaisseur ne peut prendre en charge qu'une seule langue. Il est donc nécessaire d'ajouter de nouveaux reconnaisseurs pour des langues supplémentaires.
3. Personnalisation des modèles de TLN
Comme indiqué précédemment, Presidio Analyzer utilise par défaut le modèle fr_core_web_lg de spaCy (en anglais seulement), mais il peut facilement être personnalisé en tirant avantage d'autres modèles de TLN, qu'ils soient publics ou exclusifs. Presidio utilise des moteurs de TLN pour deux tâches principales : la détection des RIP fondée sur la REN et l'extraction de fonctionnalités pour une logique selon des règles personnalisées (comme tirer parti des mots contextuels pour améliorer la détection). Ces modèles peuvent être entraînés ou téléchargés à partir de structures de TLN existantes comme spaCy (en anglais seulement), Stanza (en anglais seulement) et Transformers (en anglais seulement).
La configuration du nouveau modèle peut se faire de deux manières :
par code : en créant un NlpEngine à l'aide de la catégorie NlpEnginerProvider et en le transmettant à AnalyzerEngine en tant qu'entrée.
par configuration : en établissant les modèles à utiliser dans le fichier conf par défaut (en anglais seulement). Ce dernier est lu lors de l'initialisation par défaut d'AnalyzerEngine. Le chemin d'accès à un fichier de configuration personnalisé peut également être transmis à NlpEngineProvider.
Outre les capacités intégrées de spaCy, Stanza ou Transformers, il est possible de créer de nouveaux reconnaisseurs qui servent d'interfaces avec d'autres modèles (p. ex. flair).
b) Presidio Anonymizer :
Presidio Anonymizer est également un service en Python. Il anonymise les entités de RIP détectées avec les valeurs souhaitées en appliquant certains opérateurs comme « remplacer », « masquer » et « épurer ». Par défaut, il remplace les RIP détectés par leur type d'entité, comme <COURRIEL> ou <NUMÉRO_TÉLÉPHONE>, directement dans le texte. Mais il est possible de le personnaliser, en prévoyant une logique d'anonymisation différente pour les différents types d'entités.
L'ensemble Presidio Anonymizer contient à la fois des anonymiseurs et des désanonymiseurs.
Les anonymiseurs sont utilisés pour remplacer le texte d'une entité de RIP par une autre valeur en appliquant un opérateur donné. Les différents opérateurs intégrés sont les suivants :
remplacer : remplace les RIP par la valeur souhaitée
épurer : supprime complètement les RIP du texte
sectionner : sectionne le texte des RIP (peut être sha256, sha512 ou md5).
masquer : remplace les RIP par un caractère donné
crypter : chiffre les RIP à l'aide d'une clé cryptographique donnée
personnaliser :remplace les RIP par le résultat de la fonction exécutée sur les RIP
Image 5 : Flux de travail de l'anonymiseur des RIP [Source : Presidio Anonymizer (en anglais seulement)]
Description - Image 5 : Flux de travail de l’anonymiseur des RIP
L'image présente la fonction de Presidio Anonymizer. La partie gauche montre le texte et les RIP détectés qui sont transmis à l'anonymiseur intégré et à l'anonymiseur personnalisé. L'anonymiseur intégré se compose d'opérateurs comme « épurer », « sectionner » et « remplacer ». Après avoir fait passer le texte et les RIP détectés dans l'anonymiseur de RIP, le texte anonymisé est rendu.
Exemple :
frompresidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import RecognizerResult, OperatorConfig
# Initialize the engine:
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer) and
# Operators to get the anonymization output:
result = engine.anonymize(
text="Mr. John lives in Vancouver. His email id is john@sfu.ca",
analyzer_results= results
)
results
Presidio permet également à l'extension de Presidio Anonymizer de prendre en charge des opérateurs supplémentaires.
Les désanonymiseurs sont utilisés pour annuler l'opération d'anonymisation (p. ex. pour déchiffrer un texte chiffré).
Comme le texte d'entrée peut potentiellement contenir des entités de RIP qui se chevauchent, différents scénarios d'anonymisation sont possibles :
Pas de chevauchement (RIP uniques) : Lorsqu'il n'y a pas de chevauchement dans l'étendue des entités, Presidio Anonymizer utilise un opérateur d'anonymisation donné ou par défaut pour anonymiser et remplacer l'entité textuelle des RIP.
Chevauchement total de l'étendue des entités des RIP: Lorsque les sous-chaînes des entités se chevauchent, ce sont les RIP dont la note est la plus élevée qui sont retenues. Entre les RIP qui ont des notes semblables, la sélection est arbitraire.
Un RIP est contenu dans un autre : Presidio Anonymizer utilisera le RIP dont le texte est le plus grand, même si sa note est inférieure.
Intersection partielle : Presidio Anonymizer rendra anonyme chaque texte individuellement et remettra une concaténation du texte anonymisé. Pour commencer, installez Presidio comme l'indiquent les instructions présentées ici : Installing Presidio (en anglais seulement)
Conclusion
En conclusion, Microsoft Presidio est un outil précieux pour détecter les renseignements identificatoires personnels (RIP) dans les données textuelles. Sa conception flexible permet aux utilisateurs de créer des reconnaisseurs et des modèles personnalisés pour répondre à des cas d'utilisation précis, et sa prise en charge multilingue assure une détection efficace des RIP dans un large éventail de scénarios. En outre, la possibilité d'utiliser des services externes, des reconnaisseurs ponctuels et des reconnaisseurs de formes à partir de fichiers YAML permet aux utilisateurs d'intégrer facilement de nouvelles capacités de détection. Dans l'ensemble, les capacités de détection complètes des RIP de Presidio, ainsi que ses options de personnalisation, en font un atout pour les organisations qui cherchent à protéger des données de nature délicate.
Rencontre avec le scientifique des données
Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Pierre Lison, Ildikó Pilán, David Sánchez, Montserrat Batet et Lilja Øvrelid. 2021. « Anonymisation Models for Text Data : State of the Art, Challenges and Future Directions (en anglais seulement) », Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.
Jenneke Le Moullec, Cheffe, Programme d'élaboration de données sociales longitudinales Charles Uwitwongeye, Gestionnaire d'enquête, Centre de l'intégration et du développement des données sociales James Falconer, Chef, Avenir du recensement Sonia Bataebo, Analyste-conseil, Centre de l'intégration et du développement des données sociales
Résumé
Le présent rapport contient un résumé des conclusions du projet de recherche par la participation citoyenne délibérative menée par Statistique Canada entre octobre et décembre 2022. Il s'agissait d'une étude qualitative explorant l'acceptabilité sociale entourant l'utilisation de données administratives couplées, au niveau de la personneNote de bas de page 1, dans le cadre de programmes statistiques. Au total, 45 participants ont été recrutés et chacun a participé à 10 séances données en anglais ou en français. Au cours de ces séances, les participants ont appris à propos du sujet, ont débattu puis ont délibéré avant de voter sur une série d'énoncés définitifs. Ce rapport résume les constatations en ce qui concerne les thèmes globaux, les citations représentatives formulées par les participants durant la séance, et les résultats de courts sondages menés auprès des participants.
Même si l'objectif global était de comprendre les circonstances dans lesquelles le public canadien trouverait acceptable d'utiliser des données administratives sociales couplées (au niveau de la personne), et de comprendre les principes directeurs régissant l'utilisation de ces données à des fins statistiques, nous avons compris que cette question de recherche devait être posée et explorée dans le contexte plus large du mandat de Statistique Canada, de la protection des renseignements personnels et de la confidentialité, de l'incidence des données et de la sensibilisation du public.
L'étude vise à nous éclairer sur les raisons pour lesquelles les personnes ont des opinions particulières sur l'utilisation des données à des fins statistiques. Guidés par le processus de conception par la recherche délibérative, les points de vue éclairés des 45 participants ont donné lieu à une série de 14 énoncés globaux finaux. Sans être exécutoires, ces énoncés sont plutôt un artéfact du processus de recherche qui ne doit pas être pris hors contexte.
Méthodologie
Cette étude qualitative s'appuyait sur un cadre de recherche à participation citoyenne délibérative. La recherche délibérative est une technique qualitative de plus en plus utilisée dans les sciences sociales et se distingue d'autres formes de recherche qualitative de deux façons : 1) les participants reçoivent des renseignements pertinents sur lesquels ils fondent leurs opinions, ce qui leur permet de fournir des commentaires significatifs; 2) une série d'énoncés définitifs sont formulés par les participants et font l'objet d'un vote selon la prémisse que, comme dans la vie sociale et politique réelle, malgré leurs différences sur le plan des valeurs, des opinions et des champs d'intérêt, les membres de la société doivent s'efforcer d'adopter des règles et des pratiques communes que tous peuvent accepter.
Les étapes du projet de recherche étaient les suivantes :
Étape 1 : Recrutement des participants Étape 2 : Présentations et partage de l'information Étape 3 : Séance de remue-méninges Étape 4 : Délibérations sur des sujets cernés Étape 5 : Examen des énoncés Étape 6 : Vote final sur les énoncés Étape 7 : Clôture et évaluation
Lors du recrutement des participants, l'accent a été mis sur la diversité plutôt que sur une stricte représentativité. Étant donné que les résultats de la recherche délibérative ne sont pas destinés à être généralisés à l'ensemble de la population, le recrutement de participants a plutôt misé sur la diversité des opinions et des points de vue selon l'âge, le genre, la région, l'identité racisée et l'identité autochtone. Deux séances de délibération simultanées ont été menées en anglais et en français dans le cadre de 10 séances hebdomadaires, tenues au cours des mois d'octobre à décembre 2022. Les contraintes des séances délibératives ont rendu impossible la tenue de séances bilingues avec interprétation simultanée, de sorte que le format retenu était celui de séances séparées et simultanées dans chaque langue, le modérateur faisant ensuite la synthèse des énoncés délibératifs formulés par chaque groupe.
Formulation des énoncés délibératifs
Une technique couramment utilisée en recherche délibérative consiste à explorer le sujet, à écouter les principes sous-jacents qui ressortent des discussions et à demander aux participants de formuler des énoncés sous la direction du modérateur. Les énoncés directeurs ne se limitent pas à essayer de combler les lacunes dans ce que fait actuellement Statistique Canada. C'est-à-dire que, même si certains énoncés évoquent un idéal, d'autres pointent vers des activités déjà en cours à Statistique Canada.
Écouter : Les chercheurs ont écouté les échanges au cours de la séance de remue-méninges et des discussions délibératives.
Résumer : Les principes sous-jacents dégagés lors de la séance de remue-méninges et des discussions ont été résumés en un total de neuf énoncés bilingues.
Proposer des énoncés : Les neuf énoncés ont été communiqués aux participants avant la discussion.
Discuter : Les neuf énoncés ont été évalués, un à la fois, par les participants lors de séances de groupe. Les participants ont suggéré d'apporter des modifications au libellé des énoncés (en anglais et en français) et aux motifs des questions, ont soulevé des omissions et proposé d'autres énoncés.
Mettre la dernière main : Les commentaires sur les neuf énoncés ont été intégrés aux versions bilingues définitives. Le nombre d'énoncés est passé de 9 à 14.
Voter : Les participants ont voté sur la mesure dans laquelle ils étaient d'accord ou en désaccord avec les 14 énoncés. Les participants ont eu l'occasion de discuter et de faire la critique des énoncés définitifs, mais aucun autre changement n'a été apporté.
Énoncés définitifs et vote
Le tableau 1 montre un degré élevé de consensus, autour des énoncés délibératifs définitifs, au sein des groupes.
Tableau 1 : Mesure dans laquelle les participants étaient d'accord avec les énoncés définitifs
Énoncés
Anglais (N = 24)
Français (N = 21)
FA
A
N
D
FD
FA
A
N
D
FD
En tant qu'organisme national de statistique, Statistique Canada joue un rôle essentiel en fournissant des renseignements de qualité pour éclairer la prise de décisions au Canada.
71 %
25 %
4 %
0 %
0 %
62 %
33 %
5 %
0 %
0 %
Statistique Canada est une importante source de renseignements crédibles et de grande qualité.
79 %
21 %
0 %
0 %
0 %
71 %
29 %
0 %
0 %
0 %
Pour s'acquitter de son rôle, Statistique Canada doit conserver un grand volume de données administratives et d'enquête couplables et de nature délicate.
33 %
58 %
4 %
4 %
0 %
57 %
38 %
5 %
0 %
0 %
Les méthodes suivantes sont toutes appropriées pour aider Statistique Canada à s'acquitter de son rôle : 1) la collecte de renseignements au moyen d'enquêtes; 2) la collecte de données administratives auprès d'organismes du secteur public et privé; et 3) le couplage de données d'enquête et de données administratives.
38 %
54 %
4 %
4 %
0 %
38 %
57 %
5 %
0 %
0 %
Compte tenu de son rôle qui est de fournir des renseignements de qualité pour éclairer la prise de décisions, Statistique Canada doit respecter des normes très élevées en matière de qualité des données.
88 %
13 %
0 %
0 %
0 %
90 %
10 %
0 %
0 %
0 %
Pour améliorer le bien-être au Canada, les données de Statistique Canada devraient être utilisées efficacement par les décideurs.
75 %
25 %
0 %
0 %
0 %
67 %
24 %
10 %
0 %
0 %
Les données de Statistique Canada devraient avoir une incidence sur l'amélioration du bien-être au Canada, mais, malheureusement, cette incidence n'est pas toujours visible.
50 %
38 %
8 %
4 %
0 %
48 %
33 %
19 %
0 %
0 %
Le public doit savoir où, pourquoi, quand et comment les données sont utilisées pour avoir une incidence mesurable et positive.
42 %
46 %
13 %
0 %
0 %
67 %
29 %
5 %
0 %
0 %
Afin d'assurer le soutien continu du public et d'améliorer sa réputation, Statistique Canada devrait faire connaître son impartialité de façon proactive.
54 %
29 %
17 %
0 %
0 %
67 %
33 %
5 %
0 %
0 %
Il est important que Statistique Canada produise des données qui mettent en évidence les expériences de groupes de population particuliers, notamment ceux qui sont désavantagés.
63 %
21 %
17 %
0 %
0 %
38 %
48 %
10 %
5 %
0 %
Statistique Canada devrait activement communiquer au public de l'information sur les diffusions de données et les publications analytiques au moyen de diverses stratégies et plateformes.
58 %
38 %
0 %
4 %
0 %
57 %
38 %
5 %
0 %
0 %
Compte tenu de la quantité de données que conserve Statistique Canada, l'organisme doit respecter des normes très élevées en matière de protection de la vie privée.
88 %
13 %
0 %
0 %
0 %
100 %
0 %
0 %
0 %
0 %
Il est important que les données de Statistique Canada soient protégées contre toute utilisation qui n'est pas dans l'intérêt du public. Cela comprend les menaces d'utilisations abusives 1) au sein de Statistique Canada; 2) dans le reste du gouvernement; et 3) à l'extérieur du gouvernement, maintenant et à l'avenir.
71 %
29 %
0 %
0 %
0 %
81 %
19 %
0 %
0 %
0 %
Statistique Canada doit avoir en place des mesures et des imputabilités rigoureuses pour 1) la collecte et le couplage des données; 2) la protection des données; 3) la divulgation des données; 4) la conservation et la destruction des données; et 5) la gestion des atteintes à la vie privée. Les mesures pourraient devoir évoluer au fil du temps. Les mesures devraient également être communiquées activement et efficacement aux particuliers, aux agents du Parlement et au Parlement lui-même.
75 %
21 %
0 %
4 %
0 %
81 %
14 %
5 %
0 %
0 %
Légende : FA = Fortement d'accord; A = D'accord; N = Ni d'accord ni en désaccord; D = En désaccord; FT = Fortement en désaccord
Résultats
Quatre grands thèmes ont été dégagés : 1) l'utilisation de données administratives couplées; 2) la protection des renseignements personnels et la confidentialité; 3) l'incidence des données sociales; et 4) la sensibilisation du public.
Thème 1 : Utilisation de données Administratives couplées
L'utilisation de données administratives était acceptée, mais selon le volume et le type de données.
La grande majorité des participants étaient d'accord avec l'utilisation de données administratives couplées dans le cadre de programmes statistiques, et bon nombre d'entre eux s'attendaient à une telle utilisation. Quand on leur a expliqué quand, pourquoi et comment Statistique Canada utilise les données administratives couplées dans les programmes statistiques, de nombreux participants savaient déjà que les données étaient utilisées de la façon décrite, s'y attendaient, n'étaient pas surpris de l'apprendre ou n'ont pas exprimé de préoccupations. Quelques participants n'étaient pas enthousiastes à l'égard des données conservées par Statistique Canada, mais considéraient que ces fonds étaient nécessaires et que l'approche actuelle était meilleure que d'autres solutions. Les fonctions d'un organisme national de statistique au Canada étaient considérées comme impératives, même parmi les participants qui préféraient que leurs données ne soient pas incluses.
« … Je n'ai pas vraiment de problème en ce qui concerne l'utilisation des données administratives. Je pense qu'avec l'anonymat de tout cela et la façon dont les données sont recueillies et en sachant qu'elles sont conservées dans un endroit vraiment sûr sans risque de violation de données, ce n'est pas vraiment une grande préoccupation pour moi. »
Homme, 31 à 40 ans, Atlantique
« … Je comprends quelles sont les préoccupations : les données sont recueillies et elles sont reliées au gouvernement. Mais les membres du groupe semblent s'entendre pour dire qu'il est important de recueillir toutes ces données. Comment serait-il possible de recueillir ces données sans qu'elles soient liées au gouvernement? Quelle est l'autre option? »
Homme, 71 ans ou plus, Prairies
Les participants comprenaient généralement le rôle que joue Statistique Canada dans la communication de renseignements statistiques provenant d'enquêtes et de données administratives et l'appuyaient, y compris les participants ayant soulevé des préoccupations quant aux fonds de données administratives et d'enquête de Statistique Canada. Certains participants s'inquiétaient de la qualité des données administratives et de leur adéquation aux besoins des programmes statistiques. Les participants ont reconnu le degré variable de contrôle qu'exerce Statistique Canada sur différentes sources de données, le plus strict étant exercé sur les enquêtes, et le moins strict sur les données administratives recueillies par d'autres organismes. Certains participants se sont dits préoccupés par la qualité des données administratives, sur lesquelles ils s'attendaient à ce que Statistique Canada ait le moins de contrôle.
« … J'ignore pourquoi, mais je crains qu'il y ait plus d'erreurs dans les données provenant d'entreprises du secteur privé. Je crains qu'il y ait des erreurs dans la transmission des données à Statistique Canada. C'est l'impression que j'ai. »
Femme, 31 à 40 ans, Ontario
Quand ils ont envisagé les différents types de données administratives que conserve Statistique Canada, certains participants ont fait des distinctions quant à la provenance des données transmises à l'organisme. On a expliqué aux participants que Statistique Canada reçoit des données administratives de différents types d'organismes en vertu de la Loi sur la statistique, y compris d'organismes publics et privés. Les participants ont compris que le partage de ces données avait fait l'objet d'un examen approfondi et d'un processus de justification, et que cela a été rendu public sur le site Web de Statistique Canada. Bien que les participants aient accepté et appuyé cette idée, quelques-uns ont continué de faire des distinctions quant à la provenance des données.
La possibilité de biais dans les données administratives était un point important pour les participants, et ils ont fait remarquer que les biais inhérents pourraient découler des données recueillies par les systèmes administratifs. Ces biais comprenaient, par exemple, ceux qui découlent des perspectives occidentales traditionnelles, lesquels peuvent ne pas rendre fidèlement compte de la diversité au Canada.
La plupart des participants étaient d'accord avec la réception, l'utilisation et le stockage d'identificateurs personnels comme le prénom et le nom de famille. Les participants ont compris que des identificateurs personnels comme le prénom et le nom de famille étaient parfois requis pour le couplage d'enregistrements et qu'ils étaient donc parfois inclus dans les fichiers de données administratives d'autres organisations. On leur a expliqué que ces identificateurs sont utilisés et entreposés séparément des fichiers analytiques, et qu'ils ne sont divulgués d'aucune façon. Bien que quelques participants aient exprimé des réserves quant au volume et au type de données conservées par Statistique Canada, celles-ci ne portaient pas expressément sur la réception d'identificateurs personnels ni sur la nature des activités de couplage menées par Statistique Canada.
Les participants ont reconnu que le couplage d'enregistrements pouvait produire beaucoup de renseignements sur une personne. Cependant, ils n'ont pas exprimé la nécessité de définir une limite précise pour les activités de couplage. Ils considéraient le couplage d'enregistrements comme une technique statistique et, tout en reconnaissant le processus comme envahissant, ils n'ont pas expressément suggéré de limites à son utilisation, pourvu qu'il soit utilisé dans les programmes statistiques. Bien que la plupart des participants acceptaient que Statistique Canada utilise des données administratives couplées, quelques-uns ont indiqué être mal à l'aise. Si on leur en donnait l'option, certains préféreraient répondre directement aux enquêtes, tandis que d'autres préféreraient que leurs données administratives soient utilisées.
« … Dans l'une des présentations, il a été mentionné que les données administratives réduisaient le fardeau de réponse, et je crois que c'est une bonne chose. Je n'aime pas répondre à de longues enquêtes, alors si Statistique Canada peut recueillir les renseignements d'une autre façon, je n'ai aucune objection. »
Femme, 31 à 40 ans, Québec
« … Je préfère remplir le questionnaire en fait. »
Homme, 51 à 60 ans, Atlantique
Thème 2 : vie privée et confidentialité
Les participants s'attendent à ce que Statistique Canada respecte des normes rigoureuses en matière de responsabilisation, mais font confiance à l'organisme pour protéger la confidentialité de leurs renseignements personnels.
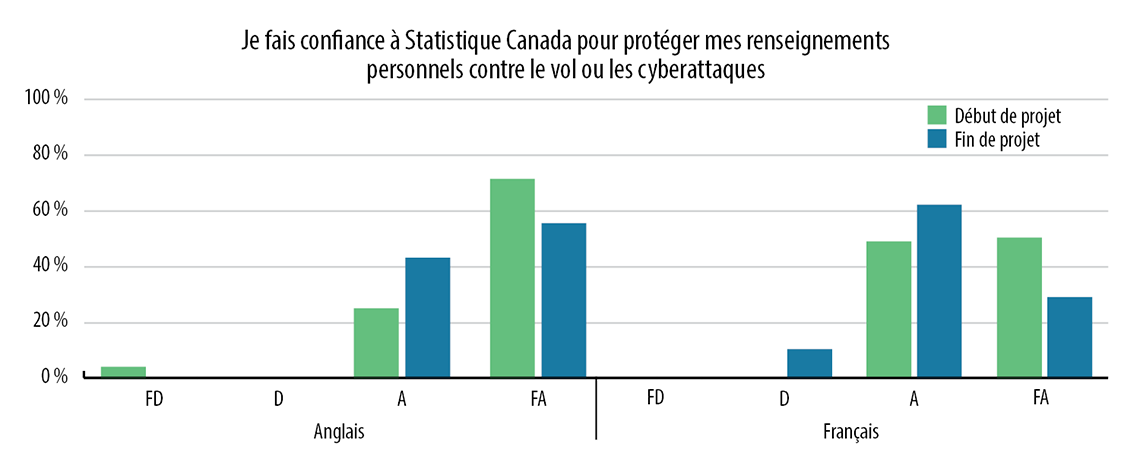
Au début de l'étude, dans le cadre du sondage de début de projet, on a demandé aux participants s'ils faisaient confiance à Statistique Canada pour protéger la confidentialité de leurs renseignements personnels, y compris contre le vol et les cyberattaques. Comme le montrent le tableau 2 et le tableau 3, au début de l'étude, la confiance des participants à cet égard était élevée.
Tout au long de l'étude, les participants ont appris à mieux connaître les types de données administratives conservées par Statistique Canada et le volume et la nature de ces données, y compris les données sur des sujets de nature délicate et les identificateurs personnels. Ils ont également été informés des risques associés aux cyberattaques et aux atteintes à la sécurité des données, ce qui a entraîné une légère baisse dans les réponses positives aux questions sur la confiance lors du sondage de fin de projet. Sachant cela, les participants faisaient encore confiance à Statistique Canada pour protéger leurs renseignements personnels. Voir le tableau 2 et le tableau 3 ci-dessous.
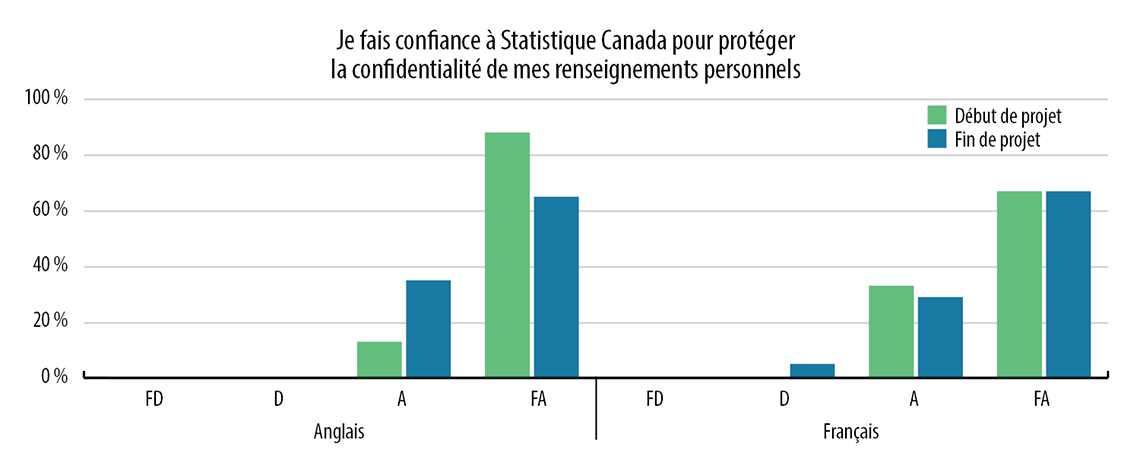
Tableau 2 : Réponses aux sondages de début et de fin de projet : « Je fais confiance à Statistique Canada pour protéger la confidentialité de mes renseignements personnels. »
« Je fais confiance à Statistique Canada pour protéger la confidentialité de mes renseignements personnels. »
Anglais
Français
FD
D
A
FA
FD
D
A
FA
Début de projet
0 %
0 %
13 %
88 %
0 %
0 %
33 %
67 %
Fin de projet
0 %
0 %
35 %
65 %
0 %
5 %
29 %
67 %
Légende : FD = Fortement en désaccord; D = Plutôt en désaccord; A = Plutôt d'accord; FA = Fortement d'accord
Tableau 3 : Réponses aux sondages de début et de fin de projet : « Je fais confiance à Statistique Canada pour protéger mes renseignements personnels contre le vol ou les cyberattaques. »
« Je fais confiance à Statistique Canada pour protéger mes renseignements personnels contre le vol ou les cyberattaques. »
Anglais
Français
FD
D
A
FA
FD
D
A
FA
Début de projet
4 %
0 %
25 %
71 %
0 %
0 %
50 %
50 %
Fin de projet
0 %
0 %
43 %
57 %
0 %
10 %
62 %
29 %
Légende : FD = Fortement en désaccord; D = Plutôt en désaccord; A = Plutôt d'accord; FA = Fortement d'accord
En ce qui concerne la gestion de la protection des renseignements personnels, les participants s'attendaient à ce que Statistique Canada soit tenu de respecter des normes égales ou supérieures à celles des autres organismes. Alors qu'ils étaient tous d'avis qu'il était de la plus haute importance pour Statistique Canada de protéger la vie privée, ils ne s'entendaient pas sur la question de savoir si l'organisme devrait être assujetti à la même norme, ou à une norme plus élevée que d'autres organisations.
« … Je m'attends à ce que Statistique Canada respecte la même norme que tout organisme public à qui on a accordé la garde de données personnelles. Je ne pense pas que Statistique Canada devrait être tenu de respecter une norme plus élevée en particulier en raison du volume, du type ou de l'ampleur des données que l'organisme conserve, mais il ne devrait certainement pas être tenu à une norme inférieure. »
Homme, 31 à 40 ans, Atlantique
Les participants voulaient savoir quelles mesures et cadres étaient en place pour protéger leurs données. On les a informés du large éventail de mesures utilisées par Statistique Canada pour protéger les données, y compris les obligations et pouvoirs législatifs et les responsabilités du personnel, et on leur a expliqué certains détails techniques, comme l'anonymisation des données. De manière générale, les participants souhaitaient comprendre ces mesures, n'ont pas exprimé de préoccupation particulière, et semblaient satisfaits.
Même s'ils étaient à l'aise avec les mesures de protection de la vie privée, certains participants étaient inquiets de l'utilisation potentiellement abusive de données personnelles, aujourd'hui et dans le futur. Ils ont exprimé différents niveaux de préoccupations au sujet de l'utilisation potentiellement abusive des données personnelles. Bien que la plupart des participants n'aient pas contesté le fait que l'utilisation abusive des données était théoriquement possible, ils étaient nombreux à ne pas s'attarder au risque d'utilisation abusive. Ceux qui ont exprimé des préoccupations ont donné différentes raisons. Certains ont mentionné le risque d'une utilisation partisane des données, tandis que d'autres étaient inquiets de personnes malveillantes ou du vol d'identité. Les participants ont reconnu la possibilité d'une violation de données, le tort que cela pourrait causer aux personnes, et l'importance d'une gestion adéquate des atteintes.
« … Je suis préoccupée par le lien avec le gouvernement, même si vous avez mentionné que Statistique Canada travaille indépendamment de lui. Oui, ça me dérange. N'importe quel gouvernement, que ce soit le gouvernement actuel, l'ancien ou le prochain. Comment vont-ils utiliser nos données? Comment vont-ils manipuler nos données et en tirer avantage? C'est la question qui me préoccupe. Ma plus grande préoccupation est le lien entre Statistique Canada et le gouvernement et le fait qu'ils envahissent notre vie privée. »
Femme, 41 à 50 ans, Ontario
« … Une violation de données est grave si l'on tient compte du fait que les données administratives comprennent tout, de notre numéro d'assurance sociale à celui de notre assurance-maladie, en passant par notre adresse, notre nom, les renseignements sur nos bébés, tout. Ils ont accès à tous nos renseignements, et nous leur en donnons encore plus lorsqu'ils le demandent. »
Femme, 61 à 70 ans, Prairies
Compte tenu de la nature envahissante du couplage des données, de la collecte obligatoire de certains renseignements d'enquête et de certains renseignements administratifs, et de l'impossibilité pour certaines personnes de refuser le couplage de leurs données ou de donner un consentement éclairé, Statistique Canada devrait s'efforcer de comprendre les points de vue de la population concernant son importante obligation de protéger la confidentialité des renseignements personnels des particuliers.
Thème 3 : Incidence des données sociales
Même s'ils s'attendent à ce que Statistique Canada utilise leurs données pour le bien commun, les participants aimeraient obtenir davantage de preuves que leurs données ont une incidence positive dans un contexte réel.
Au-delà de la façon dont les données sont recueillies et conservées, les participants voulaient en savoir davantage sur les raisons pour lesquelles les données sont utilisées et sur les répercussions sociales de cette utilisation. Le contrat social entourant l'utilisation des renseignements personnels par Statistique Canada repose sur l'utilisation responsable des données dans l'intérêt public. C'est-à-dire d'améliorer la vie des personnes qui vivent au Canada. Toutefois, en plus de faire confiance à Statistique Canada pour assurer la sécurité de ses données, les participants veulent avoir la certitude que la façon dont Statistique Canada utilise leurs données améliorera la vie des Canadiennes et Canadiens.
« … Je conviens que toute donnée recueillie devrait être utilisée aux fins auxquelles [Statistique Canada] souhaite s'en servir. Mais, plus que jamais auparavant, j'ai quand même des préoccupations quant à la façon dont elles sont entreposées et utilisées. »
Femme, 41 à 50 ans, Ontario
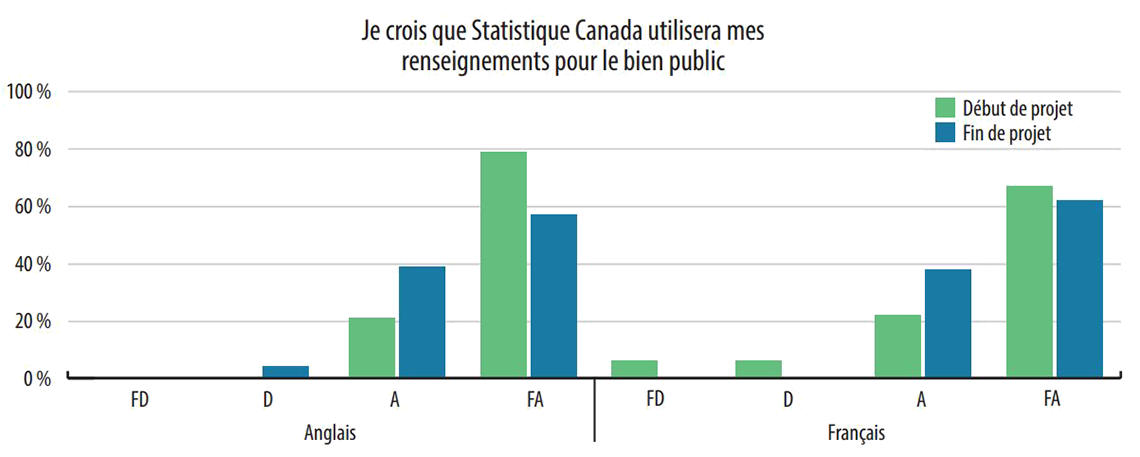
Au début de l'étude, dans le cadre du sondage de début de projet, on a demandé aux participants s'ils croyaient que Statistique Canada utilisait leurs données dans l'intérêt public. Comme on le voit dans le tableau 4, la plupart des participants étaient fortement d'accord que c'était le cas.
Pendant l'étude, les participants ont été invités à prendre considération les types de renseignements sociaux que Statistique Canada pourrait produire, y compris, par exemple, sur la qualité de l'eau dans les collectivités autochtones, la maltraitance des enfants, les conditions de logement, et le lien entre l'exposition environnementale et les résultats en matière de santé. Devant ces considérations, en raison des priorités multiples et concurrentes, les participants trouvaient de plus en plus difficile de définir « utilisation des données dans l'intérêt public ».
À la fin de l'étude, comme le montrent les réponses au sondage de fin de projet présentées dans le tableau 4, les participants étaient d'avis que Statistique Canada utilisait leurs renseignements dans l'intérêt public. Cependant, moins de participants étaient fortement d'accord. Ce changement s'explique par le fait que pendant l'étude, les participants ont envisagé de plus près le concept d'intérêt public.
Tableau 4 : Réponses aux sondages de début et de fin de projet : « Je crois que Statistique Canada utilisera mes renseignements pour le bien public. »
« Je crois que Statistique Canada utilisera mes renseignements pour le bien public. »
Anglais
Français
FD
D
A
FA
FD
D
A
FA
Début de l'étude
0 %
0 %
21 %
79 %
6 %
6 %
22 %
67 %
Fin de l'étude
0 %
4 %
39 %
57 %
0 %
0 %
38 %
62 %
Légende : FD = Fortement en désaccord; D = Plutôt en désaccord; A = Plutôt d'accord; FA = Fortement d'accord
Les participants voulaient savoir comment les priorités en matière de recherche étaient établies à Statistique Canada, y compris le rôle du reste du gouvernement dans l'établissement de ces priorités et comment le financement était attribué. Lorsque les participants ont discuté de la façon dont leurs données étaient utilisées, ils tenaient beaucoup à comprendre le contexte global de la façon dont les priorités de recherche étaient établies.
Certains participants ont souligné l'importance de l'incidence des données sociales sur les groupes minoritaires et les personnes en quête d'équité. Les sujets liés aux données sur les Autochtones ont fait l'objet de discussions tout au long des séances. Ces discussions ont été éclairées par des présentations données par le Centre de la statistique et des partenariats autochtones de Statistique Canada et d'un spécialiste en données sur les Autochtones de l'extérieur de Statistique Canada. Certains participants ont soulevé l'invisibilité apparente des répercussions qu'ont eues les études sur les questions concernant les Autochtones. Certains participants ont également mentionné l'incidence considérable des données sociales sur les groupes minoritaires et les groupes en quête d'équité, comme les groupes de minorités linguistiques, de personnes ayant un handicap et de personnes de diverses identités de genre.
Sur le plan de la protection des renseignements personnels, les participants se sont généralement moins attardés aux types de données qui sont recueillies, couplées et analysées, à condition que des mesures de protection soient en place. Au lieu, ils voulaient savoir si les « bonnes » données sont étudiées et si ces études mènent à des changements. Invités à donner leurs impressions quant aux types de données conservées par Statistique Canada et aux activités de couplage qui ont été menées, les participants ont systématiquement ramené la discussion à la question de recherche à laquelle leurs données serviraient à répondre, et aussi aux possibles répercussions que le projet de recherche pourrait avoir.
« … J'ai eu le temps cette semaine de jeter un coup d'œil sur le site Web de Statistique Canada et j'ai surtout consulté des données sur les Autochtones. Les premières statistiques sur les Autochtones concernaient les tendances dans les homicides au Canada. Venaient ensuite des statistiques le revenu et l'emploi à temps plein des femmes autochtones. Ensuite, il y avait des statistiques sur les conditions de logement des Premières Nations et des Inuit, et les refuges pour les victimes autochtones de violence. À mon avis, ces statistiques sont assez négatives. Alors je me pose la question suivante : pourquoi recueillons-nous ces données si rien ne change, si rien ne se passe? »
Femme, 61 à 70 ans, Prairies
Les participants avaient des opinions différentes sur la mesure dans laquelle Statistique Canada devrait influencer la politique gouvernementale. Ils étaient divisés quant au rôle que Statistique Canada devrait jouer dans l'établissement des priorités de recherche et quant à l'influence que les résultats de la recherche devraient avoir sur les décisions du gouvernement en matière de politiques et de programmes. Par exemple, un participant a suggéré que Statistique Canada devrait jouer un rôle dans la détermination des enjeux sociaux importants, alors qu'un autre était d'avis que l'organisme devrait fonctionner de façon autonome par rapport au reste du gouvernement.
Selon les participants, Statistique Canada joue un rôle important dans la production de renseignements de qualité, tout particulièrement dans un environnement où il y a de la mésinformation et de la désinformation. Certains ont établi une distinction entre les renseignements statistiques fournis par Statistique Canada et ceux fournis par d'autres organismes privés et sans but lucratif. Statistique Canada était perçu comme ayant une meilleure réputation pour ce qui est de fournir des renseignements de grande qualité. Certains ont également mentionné que Statistique Canada joue un rôle important dans la lutte contre la désinformation.
« … Je suis vraiment très préoccupé par la mésinformation aujourd'hui et par la façon dont les gens obtiennent leurs renseignements. Statistique Canada a-t-il examiné comment il peut conserver une bonne réputation? »
Femme, 61 à 70 ans, Prairies
Thème 4 : Sensibilisation du public
Les participants veulent en savoir plus sur Statistique Canada : Quelles données conservons-nous? Comment recueillons-nous, entreposons-nous et analysons-nous ces données? Quelles constatations intéressantes avons-nous tirées de nos recherches?
Les participants ont souligné l'importance de sensibiliser le public en communiquant de façon active et transparente. La plupart d'entre eux étaient d'avis que Statistique Canada devrait être transparent et communiquer activement de l'information sur ses fonds de données et sur la façon dont il utilise les renseignements personnels.
Au début du processus de recherche, quelques participants ont soulevé les sujets du consentement actif et des énoncés obligatoires dans le contexte de l'utilisation des données administratives par Statistique Canada. Au cours des séances, les participants ont appris que Statistique Canada ne cherche généralement pas à obtenir le consentement pour utiliser les données administratives, et qu'il n'inclut pas de déclaration de divulgation obligatoire sur les données recueillies par un autre organisme et fournies à Statistique Canada.
« … Il est important que les renseignements demandés soient utilisés uniquement aux fins pour lesquelles ils sont demandés et qu'ils ne soient pas communiqués d'une autre façon, afin que je sache exactement quelles données je fournis, où elles vont et comment elles seront utilisées. »
Homme, 71 ans ou plus, Prairies
Après avoir appris cela, les participants n'ont pas suggéré de mettre en œuvre le consentement actif ou l'énoncé obligatoire. Ils ont plutôt insisté sur l'importance de la transparence et de la communication active de l'information sur les fonds de données et l'utilisation des renseignements personnels. En plus de rendre cette information disponible sur le site Web, de nombreux participants étaient d'avis que Statistique Canada devait tenter de communiquer activement cette information aux personnes vivant au Canada.
La plupart des participants étaient d'avis que Statistique Canada devrait être transparent et communiquer activement de l'information sur la façon dont leurs renseignements sont protégés, y compris de l'information sur les violations de données. Bien que dans l'ensemble, les participants aient convenu que l'information sur les violations de données devrait être communiquée activement, certains ont mentionné que cette communication ne devrait pas se limiter aux personnes directement touchées par une violation, mais être communiquée de façon plus générale, par exemple, par l'entremise des médias. De plus, avant d'être informés au sujet de la présente recherche, certains participants croyaient qu'ils découvriraient s'ils avaient été victimes d'une violation des données que par l'entremise des médias, et ignoraient que Statistique Canada communiquerait directement avec eux.
La plupart des participants étaient d'avis que Statistique Canada devrait être transparent et communiquer activement de l'information sur les produits analytiques et les projets de recherche. Ils ont pris connaissance des produits analytiques de Statistique Canada durant l'étude. Un grand nombre d'entre eux ont manifesté de l'intérêt pour ces produits et ont visité le site Web de Statistique Canada pour en apprendre davantage sur divers sujets. De plus, ils étaient nombreux à affirmer que les renseignements produits par Statistique Canada sont intéressants, pertinents et utiles pour la population canadienne, et qu'ils devraient être activement communiqués afin qu'ils puissent être bien utilisés. Certains participants ont suggéré des canaux de communication qui pourraient être efficaces pour Statistique Canada, y compris les médias traditionnels, les médias sociaux et d'autres plateformes comme les balados.
Limites
Des renseignements et des points de vue limités provenant de l'extérieur de Statistique Canada ont été communiqués aux participants. Les résultats du sondage d'évaluation donnent à penser que les participants croyaient que les renseignements fournis étaient impartiaux et complets, mais on considère toutefois que l'inclusion de différents renseignements peut avoir eu une incidence sur les résultats de l'étude.
Bien que la recherche ait porté sur des sujets liés aux groupes minoritaires et aux groupes en quête d'équité, il ne s'agissait pas de la principale question de recherche. Par conséquent, d'autres études devraient être menées pour tenir compte des circonstances uniques de différentes sous-populations, y compris les groupes autochtones fondés sur les distinctions.
Discussion
L'utilisation de données administratives couplées doit être envisagée dans le contexte plus large du mandat, des obligations et des pouvoirs législatifs de Statistique Canada. Les participants n'ont pas fait de distinction entre les principes directeurs sur l'utilisation des données administratives couplées et les activités globales de Statistique Canada.
Même si l'objectif de la recherche était d'écouter les délibérations sur l'utilisation des données administratives couplées dans les programmes statistiques, les discussions se sont à maintes reprises éloignées du sujet principal pour se concentrer sur le rôle plus large et les activités de l'organisme national de statistique.
Statistique Canada organise son cadre juridique, ses politiques et directives, sa gouvernance des données et ses processus opérationnels en fonction de la gestion de différentes classifications des données, comme les données d'enquête, les données administratives et les données identifiées et les données anonymisées. Toutefois, les participants n'ont pas nécessairement délimité différents types de données de cette façon et se sont plutôt concentrés sur le rôle de Statistique Canada, son mandat, la protection des renseignements personnels et la confidentialité, l'incidence des données et la sensibilisation du public.
En raison de cette perspective, les discussions sur les limites de l'acceptabilité sociale ne portaient pas spécifiquement sur les circonstances dans lesquelles le couplage de données administratives était acceptable. Cependant, les limites de l'acceptabilité sociale et les circonstances dans lesquelles le couplage est acceptable peuvent être déduites des autres constatations et thèmes clés, comme la confidentialité et la protection des renseignements personnels, l'utilisation des données pour le bien commun et la transparence.
Même après avoir été informés du volume, des types, de la nature et des objectifs des activités de couplage menées à Statistique Canada, qui comprenaient des renseignements sur l'Environnement de couplage de données sociales et l'utilisation des données administratives dans des programmes comme le Recensement de la population et les Cohortes santé et environnement du recensement du Canada, les participants n'ont pas circonscrit les discussions ou les énoncés délibératifs aux circonstances dans lesquelles le couplage des données était approprié.
Les participants ont été recrutés en fonction de différents profils démographiques et de différents antécédents et selon différents niveaux de confiance envers le gouvernement et les institutions publiques. Bien que l'objectif fondamental de la recherche ait été de comprendre les circonstances dans lesquelles les Canadiennes et Canadiens issus de la diversité jugent acceptable d'utiliser des données administratives couplées ainsi que les principes directeurs sur l'utilisation des données à des fins statistiques, il était attendu que les opinions des participants ne convergent pas toutes complètement et que certains points de vue minoritaires soient maintenus. La plupart des participants ont maintenu les énoncés délibératifs, générant des connaissances sur les principes directeurs. Cependant, il est essentiel de se rappeler que les énoncés et leur appui reposent sur des points de vue divergents qui mettent en évidence la diversité des points de vue au Canada.
Non seulement ce projet de recherche nous éclaire-t-il sur les circonstances dans lesquelles le public canadien trouverait socialement acceptable d'utiliser des données administratives couplées, au niveau de la personne, mais elle fait aussi ressortir que l'utilisation de données administratives doit être envisagée dans le contexte plus large du rôle et des activités d'un organisme national de statistique.
Conclusion
Statistique Canada jouit d'un niveau de bonne volonté extraordinairement élevé de la part du public, comme en témoigne le taux de réponse du Canada à son recensement national, le plus élevé au monde, la haute estime accordée à Statistique Canada au pays et à l'étranger, et la robustesse de ses données faisant qu'elles peuvent éclairer la recherche universitaire, les politiques publiques ainsi que le débat national sur les questions sociales, économiques et environnementales. Les Canadiennes et Canadiens ont à cœur la réputation de Statistique Canada, et ils sont prêts à donner de leur temps, à lui faire confiance, et à partager leurs renseignements personnels pour assurer la qualité des données qui nous donnent un portrait juste de la population du pays, dans toute sa diversité. Statistique Canada peut tirer parti de sa relation de confiance avec la population pour améliorer ses programmes statistiques, sans éroder la confiance du public, dans la mesure où nous pouvons maintenir et améliorer nos activités de renforcement de la confiance et démontrer que les données des Canadiennes et Canadiens sont utilisées dans l'intérêt public.
Nous avons appris que nos participants à la recherche ne ressentent pas nécessairement le besoin d'imposer des limites à l'utilisation de données administratives couplées pour les programmes statistiques. Tant que des données de grande qualité sont analysées dans un environnement protégé et que la nécessité et la proportionnalité des données peuvent être justifiées au public, les participants acceptent généralement que le couplage de microdonnées soit et doive être utilisé pour produire de nouvelles informations précieuses. Les résultats du projet montrent que Statistique Canada peut envisager d'être plus audacieux dans sa vision d'une infrastructure statistique intégrée, si les mesures correspondantes en matière de transparence et de responsabilisation sont clairement communiquées et démontrées au public.
Les questions et les observations des participants devraient susciter une introspection attentive sur la façon dont Statistique Canada devrait façonner son « identité » en tant qu'organisme par rapport au public et au gouvernement. Par exemple, Statistique Canada peut-il conserver la rigueur et la crédibilité scientifiques tout en répondant aux besoins en évolution de la société en matière de données? Notre obligation prend-elle fin avec la diffusion de renseignements fidèles et véridiques, ou Statistique Canada doit-il mener une bataille publique contre la désinformation? Ces questions prennent tout leur sens lorsque nous reconnaissons les écarts qui existent entre ce que les attentes du public envers Statistique Canada et ce que nous pouvons espérer accomplir. À mesure que Statistique Canada se définit en tant qu'organisme, nous devons poursuivre le dialogue avec la population canadienne.
Plusieurs recommandations ont été dégagées des séances du projet de RPCD qui, si elles sont adoptées, contribueront de façon significative à la relation de confiance de Statistique Canada avec le public canadien. Certaines de ces recommandations ont été explicitement suggérées par les participants, tandis que d'autres ont été proposées par l'équipe de projet en réponse aux besoins et aux désirs exprimés par les participants. Premièrement, les participants ont suggéré l'adoption de mesures permanentes au sujet de la confiance du public à l'égard de Statistique Canada et d'autres questions relatives aux données. Statistique Canada devrait tenir compte de la recherche longitudinale sur l'opinion publique pour se tenir au courant des perspectives de la population générale. Presque tous les participants au projet de RPCD seraient prêts à se joindre à un « comité consultatif de citoyens » que Statistique Canada pourrait utiliser pour des séances de remue-méninges et pour mettre à l'essai des questions sur l'opinion publique. Deuxièmement, les participants apprécient la communication ouverte et transparente sur la façon dont Statistique Canada utilise les données. Statistique Canada devrait envisager d'utiliser de façon proactive les canaux de communication externes dans les médias traditionnels et numériques, et optimiser l'utilisation du Centre de confiance pour la transparence, la responsabilisation et la communication ouverte. Troisièmement, les participants veulent voir l'incidence de leurs données sur la qualité de vie. Statistique Canada devrait concevoir un nouveau type d'outil d'évaluation qui, à notre connaissance, n'a pas encore été envisagé, soit une évaluation de l'incidence des données afin d'évaluer si et comment nos produits de données sont utilisés pour apporter des changements dans un contexte réel. Comme Statistique Canada continue d'accroître l'utilisation des données administratives dans les programmes statistiques, il pourrait y avoir de moins en moins d'interactions directes avec le public sur lesquelles bâtir la confiance. La mise en œuvre de ces recommandations ouvrirait de nouvelles voies d'interaction directe avec le public pour bâtir la confiance dont dépend la qualité de nos données.
L'une des grandes forces de cette méthode de recherche et de ce projet en particulier a été notre accès privilégié au point de vue de Canadiennes et Canadiens ordinaires. C'est une leçon d'humilité de constater que la plupart des gens au Canada ne pensent pas un seul instant à Statistique Canada dans leur vie quotidienne. Mais lorsqu'on les réunit dans un forum de discussion, qu'on les informe de ce que nous faisons et qu'on leur demande de se prononcer sur un sujet particulier, cela génère une mine de données qualitatives que nous pouvons utiliser pour rectifier l'orientation de l'organisme, de ses programmes statistiques et de ses communications publiques. Cette méthode de recherche devrait être adoptée comme étude récurrente pour examiner plus à fond les enjeux plus importants avec lesquels Statistique Canada devra composer dans les années à venir.
La population canadienne demande d'avoir des données plus détaillées pour éliminer les disparités entre les genres, lutter contre le racisme et surmonter d'autres obstacles systémiques.
Afin de fournir ces données détaillées, Statistique Canada continue d'explorer de nouvelles façons de tirer le meilleur des données recueillies, par exemple, en combinant les données du recensement et les données administratives détenues par d'autres organisations. On appelle ce processus le couplage de données. Le couplage de données permet d'accéder à des renseignements plus exacts et de mener des analyses approfondies. Il permet aussi de réduire le nombre d'enquêtes auxquelles la population canadienne est invitée à participer.
Les objectifs de la recherche délibérative
Entre octobre à décembre 2022, Statistique Canada a entrepris une recherche qualitative pour mieux comprendre le point de vue du public canadien sur l'utilisation des couplages de données. En tout, 45 participants de différents profils démographiques et de différents antécédents et selon différents niveaux de confiance envers le gouvernement et les institutions publiques. Après avoir pris connaissance du sujet, ensemble ils ont élaboré un ensemble de 14 énoncés de consensus fondamentaux tenant compte des positions du groupe.
La recherche délibérative est une technique qualitative de plus en plus utilisée dans les sciences sociales et se distingue d'autres formes de recherche qualitative de deux façons : 1) les participants reçoivent des renseignements pertinents sur lesquels ils fondent leurs opinions, ce qui leur permet de fournir des commentaires significatifs; 2) une série d'énoncés définitifs sont formulés par les participants et font l'objet d'un vote selon la prémisse que, comme dans la vie sociale et politique réelle, malgré leurs différences sur le plan des valeurs, des opinions et des champs d'intérêt, les membres de la société doivent s'efforcer d'adopter des règles et des pratiques communes que tous peuvent accepter.
Principal résultat
Les participants acceptent généralement que le couplage de données soit et doive être utilisé à Statistique Canada pour produire de nouveaux renseignements précieux, tant que des données de grande qualité sont analysées dans un environnement protégé. Les participants à la recherche ne ressentent pas nécessairement le besoin d'imposer des limites à l'utilisation de données administratives couplées pour les programmes statistiques.
Non seulement ce projet de recherche nous éclaire-t-il sur les circonstances dans lesquelles le public canadien trouverait socialement acceptable d'utiliser des données administratives couplées, au niveau de la personne, mais elle fait aussi ressortir que l'utilisation de données administratives doit être envisagée dans le contexte plus large du rôle et des activités d'un organisme national de statistique.
Modèles de vision par ordinateur : projet de classification des semences
Par le laboratoire d'intelligence artificielle de l'Agence canadienne d'inspection des aliments
Introduction
L'équipe du laboratoire d'intelligence artificielle (IA) de l'Agence canadienne d'inspection des aliments (ACIA) est composée d'un groupe diversifié d'experts, y compris des scientifiques des données, des développeurs de logiciels et des chercheurs diplômés, qui travaillent ensemble pour offrir des solutions novatrices pour l'avancement de la société canadienne. En collaborant avec des membres des directions générales interministérielles du gouvernement, le laboratoire d'IA tire parti d'algorithmes d'apprentissage automatique à la fine pointe de la technologie pour offrir des solutions axées sur les données à des problèmes réels et favoriser un changement positif.
Au laboratoire d'IA de l'ACIA, nous exploitons le plein potentiel des modèles d'apprentissage profond. Notre équipe spécialisée de scientifiques des données tire parti de la puissance de cette technologie transformatrice et élabore des solutions personnalisées adaptées aux besoins particuliers de nos clients.
Dans le présent article, nous justifions le recours aux modèles de vision par ordinateur pour la classification automatique des espèces de semences. Nous démontrons de quelle façon nos modèles personnalisés ont permis d'obtenir des résultats prometteurs en utilisant des images de semences « réelles » et nous décrivons nos orientations futures pour le déploiement d'une application SeedID conviviale.
Au laboratoire d'intelligence artificielle de l'ACIA, nous nous efforçons non seulement de repousser les frontières de la science en tirant parti de modèles de pointe, mais aussi en rendant ces services accessibles à d'autres et en favorisant le partage des connaissances, afin de promouvoir l'évolution constante de la société canadienne.
Vision par ordinateur
Pour comprendre le fonctionnement des modèles de classification d'images, nous devons d'abord définir les objectifs visés par la vision par ordinateur.
Qu'est-ce que la vision par ordinateur?
Les modèles de vision par ordinateur tentent essentiellement de résoudre ce qu'on appelle mathématiquement des problèmes mal posés. Les modèles cherchent à répondre à la question suivante : qu'est-ce qui a engendré l'image?
En tant qu'humains, nous faisons cela naturellement. Lorsque les photons pénètrent dans nos yeux, notre cerveau est capable de traiter les différents modèles de lumière, ce qui nous permet d'inférer l'existence du monde physique qui se trouve devant nous. Dans le contexte de la vision par ordinateur, nous essayons de reproduire notre capacité humaine innée de perception visuelle au moyen d'algorithmes mathématiques. Des modèles de vision par ordinateur efficaces pourraient alors être utilisés pour répondre à des questions liées aux tâches suivantes :
Catégorisation d'objets : la capacité de classer des objets dans une image ou de reconnaître le visage d'une personne dans des images.
Catégorisation de scènes et de contextes : la capacité à comprendre ce qui se passe dans une image à partir de ses composantes (p. ex. intérieur et extérieur, circulation et absence de circulation).
Information spatiale qualitative : la capacité de décrire qualitativement des objets dans une image, comme un objet rigide en mouvement (p. ex. autobus), un objet non rigide en mouvement (p. ex. drapeau), un objet vertical, horizontal, incliné, etc.
Pourtant, bien que ces tâches semblent simples, les ordinateurs ont encore des difficultés à interpréter et à comprendre avec précision notre monde complexe.
Pourquoi la vision par ordinateur est-elle si difficile?
Pour comprendre pourquoi les ordinateurs semblent avoir de la difficulté à accomplir ces tâches, nous devons d'abord considérer ce qu'est une image.
Êtes-vous en mesure de décrire cette image à partir de ces valeurs?
Description - Figure 1
Cette image montre une image pixélisée en brun et blanc du visage d'une personne. Le visage de la personne est pixélisé, les pixels étant blancs et l'arrière-plan brun. À côté de l'image se trouve une image agrandie qui montre les valeurs des pixels correspondant à une petite section de l'image d'origine.
Une image est un ensemble de chiffres, avec généralement trois canaux de couleur : rouge, vert, bleu (RVB). Afin de tirer une signification de ces valeurs, l'ordinateur doit effectuer ce que l'on appelle une reconstruction d'image. Dans sa forme la plus simplifiée, nous pouvons exprimer mathématiquement cette idée par une fonction inverse :
x = F-1(y)
où :
y représente les mesures des données (c.-à-d. les valeurs des pixels);
x représente une version reconstruite des mesures, y, dans une image.
Cependant, il s'avère que la résolution de ce problème inverse est plus difficile que prévu en raison de la nature « mal posée » du problème.
Qu'est-ce qu'un problème mal posé?
Lorsqu'une image est enregistrée, il se produit une perte inhérente de renseignements puisque le monde en 3D est projeté sur un plan en 2D. Même pour nous, la compression de l'information spatiale que nous recueillons du monde physique peut rendre difficile de distinguer ce que nous voyons sur les photos.
Michel-Ange (1475-1564). L'occlusion causée par les différents points de vue peut rendre difficile la reconnaissance d'une même personne.
Description - Figure 2
L'image montre trois tableaux de personnages différents, chacun avec une expression différente sur le visage. L'un des personnages semble être en pleine réflexion, tandis que les deux autres semblent être dans un état de contemplation. Les tableaux sont réalisés dans un matériau sombre et brut, et les détails des visages sont bien définis. L'effet global de l'image en est un de profondeur et de complexité. Les tableaux sont soumis à une rotation dans chaque cadre pour créer un sentiment de changement.
Fond de canettes de soda. Des orientations différentes peuvent rendre impossible l'identification du contenu de la canette.
Description - Figure 3
L'image montre cinq canettes en métal. Quatre de ces canettes ont une tache de couleur différente sur le dessus. Les couleurs sont le bleu, le vert, le rouge et le jaune. Les canettes sont disposées sur un comptoir. Le comptoir comporte une surface sombre, semblable à du granit ou du béton.
Base de données des visages de Yale. Les variations d'éclairage peuvent rendre difficile la reconnaissance d'une même personne (rappel : tout ce que les ordinateurs « voient », ce sont des valeurs de pixels).
Description - Figure 4
L'image montre deux images du même visage. Les images sont prises sous différents angles, ce qui se traduit par deux expressions du visage perçues différemment. Sur l'image de gauche, l'homme a une expression faciale neutre, tandis que sur l'image de droite, il a une expression grave et courroucée.
Rick Scuteri-USA TODAY Sports. Des échelles différentes peuvent rendre difficile la compréhension du contexte des images.
Description - Figure 5
L'image montre quatre images différentes, à des échelles différentes. La première image ne contient seulement que ce qui ressemble à l'œil d'un oiseau. La deuxième image contient la tête et le cou d'une oie. La troisième image montre l'animal en entier, et la quatrième image montre un homme debout devant l'oiseau, indiquant une direction.
Différentes photos de chaises. La variation entre les catégories peut rendre difficile la catégorisation des objets (nous pouvons discerner une chaise grâce à son aspect fonctionnel).
Description - Figure 6
L'image montre cinq chaises différentes. La première est une chaise rouge avec un cadre en bois. La deuxième est une chaise pivotante en cuir noir. La troisième ressemble à une chaise non conventionnelle de forme artistique. La quatrième ressemble à une chaise de bureau de style minimaliste, et la dernière ressemble à un banc.
Il peut être difficile de reconnaître des objets dans des images 2D en raison d'éventuelles propriétés mal posées, notamment :
Manque d'unicité : Plusieurs objets peuvent donner lieu à la même mesure.
Incertitude : Le bruit (p. ex. le flou, la pixillation, les dommages physiques) dans les photos peut rendre difficile, voire impossible, la reconstitution et la reconnaissance d'une image.
Incohérence : de légers changements dans les images (p. ex. différents points de vue, différents éclairages, différentes échelles) peuvent rendre complexe le fait de trouver la solution « x » à partir des points de données disponibles « y »
Si les tâches de vision par ordinateur peuvent, à première vue, sembler superficielles, le problème sous-jacent qu'elles tentent de résoudre est très complexe!
Nous allons maintenant nous pencher sur certaines solutions axées sur l'apprentissage profond pour résoudre les problèmes de vision par ordinateur.
Réseaux neuronaux convolutifs (RNC)
Représentation graphique d'une architecture de réseau neuronal convolutif (RNC) pour la reconnaissance d'images. (Hoeser and Kuenzer, 2020 (en anglais seulement))
Description - Figure 7
Voici un diagramme de l'architecture d'un réseau neuronal convolutif. Le réseau se compose de plusieurs couches, dont une couche d'entrée, une couche convolutive, une couche de sous-échantillonnage et une couche de sortie. La couche d'entrée reçoit une image et la fait passer par la couche convolutive, qui applique un ensemble de filtres à l'image pour en extraire les caractéristiques.
La couche de sous-échantillonnage réduit la taille de l'image en appliquant une opération de sous-échantillonnage à la sortie de la couche convolutive. La couche de sortie traite l'image et produit un résultat final. Le réseau est entraîné à l'aide d'un ensemble de données d'images et de leurs étiquettes correspondantes.
Les réseaux neuronaux convolutifs (RNC) sont un type d'algorithme qui s'est avéré très efficace pour résoudre de nombreux problèmes de vision par ordinateur, comme nous l'avons décrit précédemment. Afin de classer ou d'identifier des objets dans des images, un modèle RNC apprend d'abord à reconnaître des caractéristiques simples dans les images, telles que les contours, les coins et les textures. Pour ce faire, il applique différents filtres à l'image. Ces filtres aident le réseau à se concentrer sur des motifs précis. Au fur et à mesure de son apprentissage, le modèle commence à reconnaître des caractéristiques plus complexes et combine les caractéristiques simples apprises à l'étape précédente pour créer des représentations plus abstraites et plus significatives. Enfin, le RNC utilise les caractéristiques apprises précédemment pour classer les images en fonction des classes avec lesquelles il a été entraîné.
Évolution des architectures RNC et de leur précision pour les tâches de reconnaissance d'images entre 2012 et 2019. (Hoeser and Kuenzer, 2020 (en anglais seulement)).
Description - Figure 8
L'image montre le tracé de la taille des différentes architectures et modèles de RNC entre 2012 et 2019. Chaque réseau neuronal est représenté par un cercle, la taille du cercle correspondant à la taille du réseau neuronal en termes de nombre de paramètres.
Le premier RNC a été proposé par Yann LeCun en 1989 (LeCun, 1989 (en anglais seulement)) pour la reconnaissance des chiffres manuscrits. Depuis lors, les RNC ont évolué de manière importante au fil des ans, grâce aux progrès réalisés à la fois dans l'architecture des modèles et dans la puissance informatique disponible. Aujourd'hui encore, les RNC continuent de faire leurs preuves en tant qu'architectures puissantes pour diverses tâches de reconnaissance et d'analyse de données.
Transformateurs de vision (ViT)
Les transformateurs de vision (ViT) relèvent d'un développement récent dans le domaine de la vision par ordinateur qui applique aux données visuelles le concept des transformateurs, conçu à l'origine pour les tâches de traitement du langage naturel. Au lieu de traiter une image comme un objet en 2D, les transformateurs de vision la considèrent comme une séquence de « cases », de la même manière que les transformateurs traitent une phrase comme une séquence de mots.
L'image montre le diagramme de l'architecture ViT. On peut y voir une image de l'image d'entrée, divisée en différentes cases, et chaque case est introduite dans le réseau neuronal. Le réseau se compose d'un bloc de codage du transformateur et d'un bloc de tête formé d'un perceptron multicouche, suivi d'une tête de classification.
Le processus commence par la division d'une image en une grille de cases. Chaque case est ensuite aplatie en une séquence de vecteurs de pixels. Des codages de position sont ajoutés pour conserver les renseignements sur la position, comme le font les transformateurs pour les tâches linguistiques. L'entrée transformée est ensuite traitée au moyen de plusieurs couches d'encodeurs du transformateur pour créer un modèle capable de comprendre des données visuelles complexes.
Tout comme les réseaux neuronaux convolutifs (RNC) apprennent à identifier les modèles et les caractéristiques d'une image par l'entremise des différentes couches convolutives, les transformateurs de vision identifient les modèles en se concentrant sur les relations entre les cases d'une image. Ils apprennent essentiellement à évaluer l'importance des différentes cases par rapport aux autres afin d'établir des classifications précises. Le modèle ViT a été présenté pour la première fois par l'équipe de Google Brain dans un article publié en 2020. Bien que les RNC aient dominé le domaine de la vision par ordinateur pendant des années, l'introduction des transformateurs de vision a démontré que les méthodes mises au point pour le traitement du langage naturel pouvaient également être utilisées pour des tâches de classification d'images, souvent avec des résultats supérieurs.
L'un des principaux avantages des transformateurs de vision est que, contrairement aux RNC, ils ne reposent pas sur une hypothèse intégrée de localité spatiale et d'invariance de décalage. Cela signifie qu'ils sont mieux adaptés aux tâches nécessitant une compréhension globale d'une image, ou lorsque de légers décalages peuvent modifier radicalement la signification d'une image.
Cependant, les ViT nécessitent généralement une plus grande quantité de données et de ressources de calcul que les RNC. Ce facteur a conduit à une tendance de modèles hybrides qui combinent à la fois les RNC et les transformateurs afin d'exploiter les forces des deux architectures.
Classification des semences
Contexte :
L'industrie des semences et des céréales du Canada, qui représente plusieurs milliards de dollars, s'est taillé une réputation mondiale en ce qui concerne la production, la transformation et l'exportation de semences de qualité supérieure pour la plantation ou de céréales destinées à l'alimentation dans une vaste gamme de cultures. Son succès est attribuable à l'engagement du Canada en faveur de l'innovation et du développement de technologies de pointe, ce qui lui permet de fournir des produits de haute qualité conformes aux normes nationales et internationales, avec une certification diagnostique qui répond aux besoins nationaux et internationaux.
Naturellement, une collaboration entre une équipe de recherche du Centre pour la science et la technologie des semences et du laboratoire d'intelligence artificielle de l'ACIA a été mise en place pour maintenir le rôle du Canada en tant que chef de file de renom dans le secteur mondial des semences ou des céréales et dans les industries de mise à l'essai connexes.
Contexte : Contrôle de la qualité
La qualité des semences d'une culture est consignée dans un rapport de classement. La catégorie finale indique dans quelle mesure un lot de semences satisfait aux normes de qualité minimales, conformément au Règlement sur les semences du Canada. Les facteurs utilisés pour déterminer la qualité des cultures comprennent les graines de mauvaises herbes contaminées, conformément à l'Arrêté sur les graines de mauvaises herbes du Canada, l'analyse de la pureté, ainsi que la germination et les maladies. Bien que la germination offre un potentiel de rendement au champ, il est essentiel d'évaluer la pureté physique de la plante pour s'assurer qu'elle contient une grande quantité des semences désirées et qu'elle est exempte de contaminants, comme des espèces interdites et réglementées, des semences de culture différente ou des graines de mauvaises herbes différentes. L'inspection des semences joue un rôle important dans la prévention de la propagation des espèces interdites et réglementées énumérées dans l'Arrêté sur les graines de mauvaises herbes. Le Canada est l'une des plus importantes bases de production pour l'approvisionnement alimentaire mondial, exportant un grand nombre de céréales comme le blé, le canola, les lentilles et le lin. Pour satisfaire à l'exigence de certification phytosanitaire et avoir accès à de vastes marchés étrangers, l'analyse des semences de mauvaises herbes réglementées pour les destinations d'importation est en forte demande, avec un délai d'exécution rapide et des changements fréquents. La capacité de contrôle pour la détection des graines de mauvaises herbes nécessite le soutien de technologies de pointe, car les méthodes traditionnelles font face à un grand défi en raison de la demande.
Justification
À l'heure actuelle, l'évaluation de la qualité d'une culture est effectuée manuellement par des experts humains. Cependant, ce processus est fastidieux et prend beaucoup de temps. Au laboratoire d'IA, nous tirons parti de modèles de vision par ordinateur avancés pour classer automatiquement les espèces de semences à partir d'images, ce qui rend ce processus plus efficace et plus fiable.
Ce projet vise à développer et à déployer un puissant pipeline de vision par ordinateur pour la classification des espèces de semences. En automatisant ce processus de classification, nous pouvons simplifier et accélérer l'évaluation de la qualité des cultures. Nous développons des solutions fondées sur des algorithmes avancés et des techniques d'apprentissage profond, tout en assurant une évaluation impartiale et efficace de la qualité des cultures, ouvrant ainsi la voie à l'amélioration des pratiques agricoles.
Projet no 1 : Imagerie et analyse multispectrales
Dans le cadre de ce projet, nous utilisons un modèle de vision par ordinateur personnalisé pour évaluer la pureté du contenu, en déterminant et en classifiant les espèces de semences désirées pour les distinguer des espèces de semences non désirées.
Nous parvenons à récupérer et à déterminer les cas de contamination par trois espèces de mauvaises herbes différentes dans un mélange trié d'échantillons de blé.
Notre modèle est personnalisé de manière à accepter des entrées d'images multispectrales uniques à haute résolution à 19 canaux et à atteindre une précision de plus de 95 % sur les données d'essai.
Nous avons exploré plus en profondeur le potentiel de notre modèle à classer de nouvelles espèces, en introduisant cinq nouvelles espèces de canola dans l'ensemble de données et en observant des résultats similaires. Ces résultats encourageants mettent en évidence le potentiel d'utilisation continue de notre modèle, même lorsque de nouvelles espèces de semences sont introduites.
Notre modèle a été formé pour classer les espèces suivantes :
Trois espèces différentes de chardon (mauvaises herbes) :
Cirsium arvense (espèces réglementées)
Carduus nutans (semblables aux espèces réglementées)
Cirsium vulgare (semblables aux espèces réglementées)
Six semences de culture :
Triticum aestivum, sous-espèce aestivum
Brassica napus, sous-espèce napus
Brassica juncea
Brassica juncea (de type jaune)
Brassica rapa, sous-espèce oleifera
Brassica rapa, sous-espèce oleifera (de type brun)
Notre modèle a permis d'identifier correctement chaque espèce de semence avec une précision de plus de 95 %.
De plus, lorsque les semences des trois espèces différentes de chardon ont été intégrées au criblage du blé, le modèle a atteint une précision moyenne de 99,64 % sur 360 semences. Ces résultats ont permis de démontrer la robustesse du modèle et sa capacité à classer de nouvelles images.
Enfin, nous avons introduit cinq nouveaux types et espèces de canola et évalué le rendement de notre modèle. Les résultats préliminaires de cette expérience ont montré une précision d'environ 93 % sur les données de test.
Projet no 2 : Imagerie et analyse en mode RVB au microscope numérique
Dans le cadre de ce projet, nous utilisons un processus en deux étapes pour déterminer un total de 15 espèces de semences différentes ayant une importance réglementaire et présentant un défi morphologique à divers niveaux de grossissement.
Tout d'abord, un modèle de segmentation des semences est utilisé pour déterminer chaque instance d'une semence dans l'image. Ensuite, un modèle de classification permet de classer chaque espèce de semence.
Nous réalisons plusieurs études par ablation en entraînant le modèle sur un profil de grossissement, puis en le testant sur des images de semences provenant d'un autre ensemble d'images à divers niveaux de grossissement. Nous obtenons des résultats préliminaires prometteurs d'une précision de plus de 90 % pour tous les niveaux de grossissement.
Trois niveaux de grossissement différents ont été fournis pour les 15 espèces suivantes :
Ambrosia artemisiifolia
Ambrosia trifida
Ambrosia psilostachya
Brassica junsea
Brassica napus
Bromus hordeaceus
Bromus japonicus
Bromus secalinus
Carduus nutans
Cirsium arvense
Cirsium vulgare
Lolium temulentum
Solanum carolinense
Solanum nigrum
Solanum rostratum
Un mélange de 15 espèces différentes a été pris en photo à différents niveaux de grossissement. Le niveau de grossissement a été indiqué par le nombre total d'occurrences de semences présentes dans l'image, soit : 1, 2, 6, 8 ou 15 semences par image.
Afin d'établir un protocole d'enregistrement d'image normalisé, nous avons entraîné de manière indépendante des modèles distincts à partir d'un sous-ensemble de données à chaque niveau de grossissement, puis nous avons évalué le rendement du modèle sur un ensemble de données de test réservé à tous les niveaux de grossissement.
Les résultats préliminaires ont démontré la capacité du modèle à déterminer correctement les espèces de semences à différents niveaux de grossissement avec une précision de plus de 90 %.
Ces résultats ont permis de révéler le potentiel du modèle à classer avec précision des données jusque-là inconnues à différents niveaux de grossissement.
Tout au long de nos expériences, nous avons essayé et testé différentes méthodologies et différents modèles.
Les modèles avancés équipés d'une forme canonique comme les transformateurs « Swin » ont mieux résisté et se sont révélés moins perturbés par le niveau de grossissement et de zoom.
Discussion et défis
La classification automatique des semences est une tâche difficile. L'entraînement d'un modèle d'apprentissage automatique pour la classification des semences pose plusieurs défis en raison de l'hétérogénéité inhérente aux différentes espèces et entre celles-ci. Par conséquent, de grands ensembles de données sont nécessaires pour entraîner efficacement un modèle à l'apprentissage de caractéristiques propres à une espèce. De plus, le degré élevé de ressemblance entre différentes espèces au sein des genres pour certaines d'entre elles rend difficile, même pour des experts humains, la distinction entre des espèces intragenres étroitement apparentées. De plus, la qualité de la capture d'images peut également avoir une incidence sur le rendement des modèles de classification des semences, car les images de faible qualité peuvent entraîner la perte de renseignements importants nécessaires à une classification précise.
Pour relever ces défis et améliorer la robustesse des modèles, des techniques d'enrichissement des données ont été appliquées dans le cadre des étapes de prétraitement. Les transformations affines, comme la mise à l'échelle et la traduction d'images, ont été utilisées pour augmenter la taille de l'échantillon, tandis que l'ajout de bruit gaussien peut augmenter la variation et améliorer la généralisation sur les données non encore vues par le modèle, empêchant ainsi le surapprentissage sur les données d'entraînement.
Le choix de l'architecture de modèle appropriée a été crucial pour atteindre le résultat souhaité. Un modèle peut ne pas produire de résultats exacts si les utilisateurs finaux ne respectent pas un protocole normalisé, particulièrement lorsque les données fournies ne correspondent pas à la distribution prévue. Par conséquent, il était impératif de tenir compte de diverses sources de données et d'utiliser un modèle qui fait montre d'une capacité de généralisation efficace entre domaines pour assurer une classification exacte des semences.
Conclusion
Le projet de classification des semences est un exemple de la collaboration fructueuse et continue entre le laboratoire d'IA et le Centre pour la science et la technologie des semences de l'ACIA. En mettant en commun leurs connaissances et leur expertise respectives, les deux équipes contribuent à l'avancement des industries des semences et des céréales du Canada. Le projet de classification des semences montre de quelle façon l'utilisation d'outils avancés d'apprentissage automatique peut améliorer considérablement l'exactitude et l'efficacité de l'évaluation de la qualité des semences ou des céréales en conformité avec le Règlement sur la protection des semences ou le Règlement sur la protection des végétaux, au plus grand bénéfice du secteur agricole, des consommateurs, de la biosécurité et de la salubrité des aliments.
En tant que scientifiques des données, nous reconnaissons l'importance de la collaboration ouverte et nous sommes déterminés à respecter les principes de la science ouverte. Notre objectif est de promouvoir la transparence et la mobilisation grâce à un libre échange avec le public.
En rendant notre application accessible, nous invitons les autres chercheurs, les experts en semences et les développeurs à contribuer à son amélioration et à sa personnalisation. Cette approche collaborative favorise l'innovation, ce qui permet à la communauté d'améliorer collectivement les capacités de l'application SeedID et de répondre aux exigences particulières de différents domaines.
Rencontre avec le scientifique des données
Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Code de niveau de production dans le domaine de la science des données
Par David Chiumera, Statistique Canada
Au cours des dernières années, le domaine de la science des données a connu une croissance explosive puisque les entreprises de nombreux secteurs investissent massivement dans des solutions fondées sur les données afin d’optimiser les processus de prise de décision. Cependant, le succès de tout projet de science des données dépend fortement de la qualité du code en arrière-plan. L’écriture du code de niveau de production est essentielle pour veiller à ce que les modèles et les applications de la science des données soient mis en œuvre et appliqués efficacement, permettant ainsi aux entreprises de réaliser la pleine valeur de leur investissement dans la science des données.
Le code de niveau de production correspond à un code conçu pour satisfaire les besoins d’un utilisateur final, l’accent étant mis sur l’extensibilité, la robustesse et la maintenabilité. Cela contraste avec le code écrit uniquement à des fins d’expérimentation et d’exploration, qui peut ne pas être optimisé en vue d’être utilisé dans l’environnement de production. L’écriture du code de niveau de production est essentielle pour les projets en science des données, car elle permet le déploiement efficace de solutions dans des environnements de production, où ils peuvent être intégrés à d’autres systèmes et utilisés pour éclairer la prise de décision.
Le code de niveau de production présente plusieurs avantages clés pour les projets en science des données. Tout d’abord, il garantit que les solutions de science des données peuvent être facilement déployés et appliqués. Deuxièmement, il réduit le risque d’erreurs, de vulnérabilités et de temps d’arrêt. Enfin, il facilite la collaboration entre les scientifiques des données et les réalisateurs de logiciels, ce qui leur permet de travailler ensemble plus efficacement pour fournir des solutions de haute qualité. Enfin, il favorise la réutilisation du code et la transparence, ce qui permet aux scientifiques des données d’échanger leurs travaux avec d’autres et de s’appuyer sur le code existant pour améliorer les projets à venir.
Dans l’ensemble, le code de niveau de production est un élément essentiel de tout projet de science des données réussi. En accordant la priorité au développement d’un code qui est de haute qualité, évolutif et maintenable, les entreprises peuvent ainsi assurer l’optimisation de leur investissement dans la science des données, prendre des décisions plus éclairées et acquérir un avantage concurrentiel dans l’économie actuelle axée sur les données.
La portée de la science des données et ses différentes applications
Le champ d’application de la science des données est vaste; il englobe un large éventail de techniques et d’outils utilisés pour tirer des connaissances à partir de données. À la base, la science des données comprend la collecte, l’épuration et l’analyse des données afin de cerner les tendances et de faire des prédictions. Ses applications sont nombreuses, allant de l’intelligence économique et de l’analyse marketing jusqu’aux soins de santé et à la recherche scientifique. La science des données est utilisée pour résoudre un large éventail de problèmes, comme la prédiction du comportement des consommateurs, la détection de la fraude, l’optimisation des activités et l’amélioration des résultats des soins de santé. Comme la quantité de données générées continue de croître, le champ d’application de la science des données devrait aussi continuer de s’étendre, en mettant de plus en plus l’accent sur l’utilisation de techniques avancées comme l’apprentissage automatique et l’intelligence artificielle.
Pratiques de programmation et de génie logiciel appropriées pour les scientifiques des données
Des pratiques de programmation et de génie logiciel appropriées sont essentielles pour créer des applications de science des données robustes qui peuvent être déployées et tenues à jour efficacement. Les applications robustes sont celles qui sont fiables, évolutives et efficaces et qui répondent aux besoins de l’utilisateur final. Plusieurs types de pratiques de programmation et de génie logiciel sont particulièrement importants dans le contexte de la science des données, comme le contrôle de version, les tests automatisés, la documentation, la sécurité, l’optimisation du code et l’usage adéquat des modèles de conception, pour n’en citer que quelques-uns.
En suivant les bonnes pratiques, les scientifiques des données peuvent créer des applications robustes qui sont fiables, évolutives et efficaces, tout en mettant l’accent sur les besoins de l’utilisateur final. Cela est essentiel pour garantir que les solutions de la science des données apportent une valeur optimale aux entreprises et aux autres organismes.
Projet de prétraitement des données administratives et son objectif : un exemple
Le projet de prétraitement des données administratives (PDA) est une application du secteur 7 qui nécessite la participation de la Division de la science des données pour réusiner une composante élaborée par un citoyen en raison de divers problèmes qui nuisaient à son état de préparation pour l’environnement de production. Plus précisément, la base du code utilisée pour intégrer les flux de travail externes au système ne respectait pas les pratiques de programmation établies, ce qui se traduisait par une expérience utilisateur lourde et difficile. De plus, on remarque une absence notable de rétroaction pertinente de la part du programme lorsqu’il y a une défaillance, ce qui fait en sorte qu’il est difficile de diagnostiquer et de régler les problèmes.
On a aussi constaté des lacunes dans la base de code en ce qui a trait à la documentation, à la journalisation des erreurs et aux messages d’erreur significatifs pour les utilisateurs, ce qui a encore aggravé le problème. Le couplage dans la base de code était excessif, ce qui fait en sorte qu’il a été difficile de modifier ou d’étendre des fonctions du programme, au besoin. De plus, il n’y avait aucun essai unitaire en place pour assurer la fiabilité et l’exactitude. En outre, le code était trop adapté à un exemple précis. Il était donc difficile de l’appliquer d’une façon générale à d’autres scénarios d’utilisation. Il y avait aussi plusieurs caractéristiques souhaitées qui n’étaient pas présentes pour satisfaire les besoins du client.
Ces problèmes nuisaient grandement à la capacité du projet de PDA d’effectuer le prétraitement de données semi-structurées. L’absence de rétroaction et de documentation a fait en sorte qu’il était extrêmement difficile, voire impossible, pour le client d’utiliser efficacement les flux de travail intégrés, ce qui a donné lieu à de la frustration et à des inefficacités. Souvent, les résultats du programme n’étaient pas conformes aux attentes, et l’absence d’essais unitaires ne permettait pas de garantir la fiabilité et la précision. En résumé, le projet de PDA nécessitait le réusinage des flux de travail intégrés (c.-à-d. l’épuration ou le remaniement du code). Ce processus à multiples facettes comprenait le règlement d’un éventail de problèmes de programmation et d’ingénierie pour que l’application soit plus robuste et prête pour l’environnement de production. Pour ce faire, nous avons utilisé une approche de réusinage « Rouge-Vert » pour améliorer la qualité du produit.
Réusinage à l’aide d’une approche « Rouge-Vert » au lieu d’une approche « Vert-Rouge »
Le réusinage est le processus de remaniement du code existant en vue d’en améliorer la qualité, la lisibilité, la maintenance et le rendement. Cela peut nécessiter diverses activités, y compris l’épuration du formatage du code, l’élimination des codes en double, l’amélioration des conventions de dénomination et l’introduction de nouvelles abstractions et de nouveaux modèles de conception.
Le réusinage est avantageux pour diverses raisons. Premièrement, cette approche peut améliorer la qualité globale de la base de code, ce qui facilite la compréhension et la maintenance. Cela permet d’économiser du temps et des efforts à long terme, surtout lorsque les bases de code deviennent plus grandes et plus complexes. De plus, le réusinage peut améliorer la performance et réduire les risques de bogues et d’erreurs, ce qui se traduit par une application plus fiable et robuste.
Une approche courante de réusinage est l’approche « Rouge-Vert », qui fait partie du processus de développement basé sur les tests. Dans l’approche Rouge-Vert, un scénario d’essai défaillant est écrit avant que le code ne soit écrit ou réusiné. À la suite de ce test défaillant, on procède à l’écriture du code minimal qui serait requis pour obtenir un test réussi, après quoi on réusine le code pour l’améliorer, au besoin. Pour l’approche Vert-Rouge, on procède dans le sens inverse : le code est écrit avant l’écriture et l’exécution des scénarios d’essai.
L’un des avantages de l’approche Rouge-Vert est la capacité de détecter les erreurs dès le début du processus de développement, ce qui permet de réduire le nombre de bogues et d’améliorer l’efficacité des cycles de développement. L’approche met également l’accent sur le développement basé sur les tests, ce qui peut mener à un code plus fiable et précis. De plus, elle incite les développeurs à prendre en compte l’expérience de l’utilisateur dès le départ, en veillant à ce que la base de code soit conçue en ayant l’utilisateur final en tête.
Figure 1 : Rouge-Vert-Réusinage
La première étape, la composante « Rouge », désigne l’écriture d’un test qui échoue. À partir de là, le code est modifié pour obtenir un test réussi, ce qui correspond à la composante « Vert ». Enfin, on procède au réusinage, le cas échéant, pour améliorer davantage la base de code. Un autre test sera ensuite créé et exécuté. Si ce test échoue, le processus retourne à la composante « Rouge ». Le cycle se poursuit indéfiniment jusqu’à ce que l’état souhaité soit atteint, ce qui met fin à la boucle de commande.
Dans le cas du projet de PDA, l’approche Rouge-Vert a été appliquée lors du processus de réusinage. Ceci a mené à un processus de déploiement sans heurt, et l’application était plus fiable, plus robuste et plus facile à utiliser. En appliquant cette approche, nous avons pu relever les différents défis de programmation et d’ingénierie auxquels fait face le projet, ce qui a permis d’obtenir une application plus efficiente, plus efficace, plus stable et prête pour l’environnement de production.
Les pratiques normalisées manquent souvent dans les travaux de science des données
Si la science des données est devenue un domaine essentiel dans de nombreuses industries, elle n’est pas exempte de défis. L’un des principaux problèmes est l’absence de pratiques normalisées qui font souvent défaut dans les travaux de science des données. Bien qu’il existe de nombreuses pratiques normalisées qui peuvent améliorer la qualité, la maintenabilité et la reproductibilité du code de la science des données, de nombreux scientifiques des données les négligent au profit de solutions rapides.
La présente section aborde certaines des pratiques normalisées les plus importantes qui font souvent défaut dans les travaux de science des données. Ces pratiques comprennent :
le contrôle de la version;
la vérification du code (unité, intégration, système, acceptation);
la documentation;
l’examen du code;
la garantie de la reproductibilité;
le respect des règles de style (c’est-à-dire les normes PEP);
l’utilisation des annotations de type;
la rédaction de chaînes de documentation claires;
la journalisation des erreurs;
la validation de données;
l’écriture d’un code de faible entretien;
la mise en œuvre de processus d’intégration continue et de déploiement continu (IC/DC).
En suivant ces pratiques normalisées, les scientifiques des données peuvent améliorer la qualité et la fiabilité de leur code, réduire les erreurs et les bogues et rendre leur travail plus accessible aux autres.
Documenter le code
La documentation du code est essentielle pour rendre le code compréhensible et utilisable par d’autres développeurs. Dans le domaine de la science des données, il peut s’agir de documenter les étapes de nettoyage des données, d’ingénierie des caractéristiques, de formation des modèles et d’évaluation. Sans une documentation appropriée, il peut être difficile pour les autres de comprendre ce que fait le code, les hypothèses formulées et les compromis envisagés. L’absence de documentation appropriée peut également rendre difficile la reproduction des résultats, ce qui est un aspect fondamental de la recherche scientifique et de la création d’applications robustes et fiables.
Rédaction de chaînes de documentation claires
Les chaînes de documentation sont des chaînes qui fournissent de la documentation sur les fonctions, les classes et les modules. Elles sont généralement écrites dans un format spécial qui peut être facilement analysé par des outils comme Sphinx pour générer de la documentation. La rédaction d’une documentation claire peut aider les autres développeurs à comprendre ce que fait une fonction ou un module, les arguments qu’elle prend et ce qu’elle renvoie. Elle peut également fournir des exemples d’utilisation du code, ce qui peut permettre à d’autres développeurs d’intégrer plus facilement le code dans leurs propres projets.
def complex (real=0.0, imag=0.0):
"""Form a complex number.
Keyword arguments:
real -- the real part (default 0.0)
imag -- the imaginary part (default 0.0)
"""if imag ==0.0 and real ==0.0:
return compelx_zero
...
Exemple de chaîne de documentation multiligne
Respect des règles de style
Les règles de style relatives au code jouent un rôle crucial pour assurer la lisibilité, la maintenabilité et la cohérence d’un projet. En respectant ces règles, les développeurs peuvent améliorer la collaboration et réduire le risque d’erreurs. Une indentation cohérente, des noms de variables clairs, des commentaires concis et le respect des conventions établies sont quelques-uns des éléments clés de règles de style efficaces qui contribuent à la production d’un code de haute qualité et bien organisé. Les normes PEP (proposition d’amélioration de Python), qui fournissent des lignes directrices et de bonnes pratiques pour l’écriture du code Python, en sont un exemple. Elles garantissent que le code peut être compris par d’autres développeurs Python, ce qui est important dans les projets collaboratifs, mais aussi pour la maintenabilité générale. Certaines normes PEP traitent des conventions d’appellation (en anglais seulement), du formatage du code (en anglais seulement), et de la manière de gérer les erreurs et les exceptions (en anglais seulement).
Utilisation des annotations de type
Les annotations de type sont des annotations qui indiquent le type d’une variable ou d’un argument de fonction. Elles ne sont pas strictement nécessaires à l’exécution du code Python, mais elles peuvent améliorer la lisibilité, la maintenabilité et la fiabilité du code. Les annotations de type peuvent aider à détecter les erreurs plus tôt dans le processus de développement et à rendre le code plus facile à comprendre pour les autres développeurs. Elles offrent également une meilleure prise en charge de l’environnement de développement interactif et peuvent améliorer les performances en permettant une allocation plus efficace de la mémoire.
Contrôle de version
Le contrôle de version est le processus de gestion des modifications apportées au code et à d’autres fichiers au fil du temps. Il permet aux développeurs de suivre et d’annuler les modifications, de collaborer sur le code et de s’assurer que tout le monde travaille avec la même version de code. Dans le domaine de la science des données, le contrôle de version est particulièrement important, car les expériences peuvent générer de grandes quantités de données et de codes. En utilisant le contrôle de version, les scientifiques des données peuvent s’assurer qu’ils peuvent reproduire et comparer les résultats entre les différentes versions de leur code et de leurs données. Le contrôle de version permet également de suivre et de documenter les modifications, ce qui peut s’avérer important à des fins de conformité et de vérification.
Figure 2 : Illustration du contrôle de version
Une branche principale (V1) est créée en tant que projet principal. Une nouvelle branche dérivée de la V1 est créée afin de développer et de tester jusqu’à ce que les modifications soient prêtes à être fusionnées avec la V1, créant ainsi la V2 de la branche principale. La V2 est ensuite publiée.
Vérification du code
La vérification du code est la vérification formelle (et parfois automatisée) de l’exhaustivité, de la qualité et de l’exactitude du code par rapport aux résultats attendus. Il est essentiel de vérifier le code pour s’assurer que la base de code fonctionne comme prévu et que l’on peut s’y fier. Dans le domaine de la science des données, les tests peuvent inclure des essais unitaires pour les fonctions et les classes, des essais d’intégration pour les modèles et les pipelines, et des essais de validation pour les ensembles de données. En vérifiant le code, les scientifiques des données peuvent détecter les erreurs et les bogues plus tôt dans le processus de développement et s’assurer que les changements apportés au code n’introduisent pas de nouveaux problèmes. Cela permet d’économiser du temps et des ressources à long terme en réduisant la probabilité d’erreurs inattendues et en améliorant la qualité générale du code.
Examens du code
Les examens du code sont un processus au cours duquel d’autres développeurs examinent le nouveau code et les modifications apportées au code pour s’assurer qu’ils respectent les normes de qualité et de style, qu’ils sont maintenables et qu’ils répondent aux exigences du projet. Dans le domaine de la science des données, les examens du code peuvent être particulièrement importants, car les expériences peuvent générer du code et des données complexes, et parce que les scientifiques des données travaillent souvent de manière indépendante ou en petites équipes. Les examens du code permettent de détecter les erreurs, de s’assurer que le code respecte les meilleures pratiques et les exigences du projet et de promouvoir l’échange des connaissances et la collaboration entre les membres de l’équipe.
Garantie de la reproductibilité
La reproductibilité est un aspect essentiel de la recherche scientifique et de la science des données. Des résultats reproductibles sont nécessaires pour vérifier et approfondir les études antérieures et pour garantir que les résultats sont cohérents, valides et fiables. Dans le domaine de la science des données, la reproductibilité peut inclure la documentation du code et des données, l’utilisation du contrôle de version, des essais rigoureux et la fourniture d’instructions détaillées pour l’exécution des expériences. En garantissant la reproductibilité, les scientifiques des données peuvent rendre leurs résultats plus fiables et crédibles et accroître la confiance dans leurs conclusions.
Journalisation
La journalisation consiste à tenir un registre des événements qui se produisent dans un système informatique. Cela est important pour le dépannage, la collecte de renseignements, la sécurité, la fourniture de renseignements sur la vérification, entre autres raisons. Il s’agit généralement de l’écriture de messages dans un fichier journal. La journalisation est un élément essentiel du développement de logiciels robustes et fiables, y compris les applications de science des données. La journalisation des erreurs permet de cerner les problèmes liés à l’application, ce qui permet de la déboguer et de l’améliorer. En journalisant les erreurs, les développeurs peuvent savoir ce qui n’a pas fonctionné dans l’application, ce qui peut les aider à diagnostiquer le problème et à prendre des mesures correctives.
À l’aide de la journalisation, les développeurs peuvent également suivre les performances de l’application au fil du temps, ce qui leur permet de déterminer les goulots d’étranglement potentiels et les domaines à améliorer. Cela peut s’avérer particulièrement important pour les applications de science des données qui pourraient devoir traiter de grands ensembles de données ou d’algorithmes complexes.
Dans l’ensemble, la journalisation est une pratique essentielle pour développer et maintenir des applications de haute qualité de science des données.
Écriture d’un code de faible entretien
Lorsqu’il s’agit d’applications de science des données, la performance est souvent un facteur clé. Pour que l’application soit rapide et réactive, il est important d’écrire un code optimisé pour la vitesse et l’efficacité.
L’un des moyens d’y parvenir est d’écrire un code de faible entretien. Un code de faible entretien est un code qui utilise un minimum de ressources et dont le coût de calcul est faible. Cela peut contribuer à améliorer les performances de l’application, en particulier lorsqu’il s’agit de grands ensembles de données ou d’algorithmes complexes.
L’écriture d’un code de faible entretien nécessite un examen minutieux des algorithmes et des structures de données utilisés dans l’application ainsi qu’une attention particulière à l’utilisation de la mémoire et à l’efficacité du traitement. Il convient de réfléchir aux besoins, à l’architecture globale et à la conception d’un système afin d’éviter des modifications importantes de la conception en cours de route.
En outre, le code de faible entretien est facile à tenir à jour et nécessite des révisions et des mises à jour peu fréquentes. Il s’agit d’un point important, car cela réduit le coût de maintenance des systèmes et permet un développement plus axé sur les améliorations ou les nouvelles solutions.
Dans l’ensemble, l’écriture du code de faible entretien est une pratique importante pour les scientifiques des données qui souhaitent développer des applications rapides et réactives capables de gérer de grands ensembles de données et des analyses complexes tout en maintenant des coûts de maintenance faibles.
Validation des données
La validation des données consiste à vérifier que les données d’entrée répondent à certaines exigences ou normes. La validation des données est une autre pratique importante dans le domaine de la science des données, car elle permet de cerner les erreurs ou les incohérences dans les données avant qu’elles n’aient une incidence sur le processus d’analyse ou de modélisation.
La validation des données peut prendre de nombreuses formes, de la vérification du format correct des données à la vérification qu’elles soient dans les fourchettes ou les valeurs attendues. Il existe différents types de contrôles de validation des données, comme le type, le format, l’exactitude, la cohérence et l’unicité. En validant les données, les scientifiques des données peuvent s’assurer que leurs analyses sont basées sur des données exactes et fiables, ce qui peut améliorer la précision et la crédibilité de leurs résultats.
Intégration continue et déploiement continu
L’intégration continue et le déploiement continu (IC/DC) sont un ensemble de bonnes pratiques visant à automatiser le processus de création, d’essai et de déploiement de logiciels. L’IC/DC peut contribuer à améliorer la qualité et la fiabilité des applications de science des données en garantissant que les changements sont testés de manière approfondie et déployés rapidement et de manière fiable.
L’IC/DC suppose l’automatisation du processus de construction, des essais et de déploiement des logiciels, souvent à l’aide d’outils et de plateformes comme Jenkins, GitLab ou GitHub Actions. En automatisant ces processus, les développeurs peuvent s’assurer que l’application est construite et testée de manière cohérente et que les erreurs ou les problèmes qui empêchent le déploiement du code problématique sont déterminés et traités rapidement.
L’IC/DC peut également contribuer à améliorer la collaboration entre les membres de l’équipe, en garantissant que les changements sont intégrés et testés dès qu’ils sont effectués, plutôt que d’attendre un cycle de publication périodique.
Figure 3 : IC/DC
L’image illustre un processus répétitif représenté par le symbole de l’infini divisé en huit parties inégales. En partant du milieu et en allant dans le sens inverse des aiguilles d’une montre, les premières de ces parties sont : planifier, coder, construire et tester en continu. Ensuite, en partant de la dernière partie, qui était au centre, et en se déplaçant dans le sens des aiguilles d’une montre, les parties sont : publier, déployer, opérer et surveiller, avant de revenir à l’état initial de l’image.
Dans l’ensemble, l’IC/DC est une pratique importante pour les scientifiques des données qui souhaitent développer et déployer des applications de science des données de haute qualité de manière rapide et fiable.
Conclusion
En résumé, le code de niveau de production est essentiel pour les projets et les applications de science des données. Des pratiques de programmation appropriées et des principes de génie logiciel comme l’adhésion aux normes PEP, l’utilisation des annotations de type, la rédaction d’une documentation claire, le contrôle de version, la vérification du code, la journalisation des erreurs, la validation des données, l’écriture d’un code de faible entretien, la mise en œuvre d’une intégration continue et d’un déploiement continu (IC/DC) et la garantie de la reproductibilité sont essentiels pour créer des applications robustes, maintenables et évolutives.
Le non-respect de ces pratiques peut entraîner des difficultés comme le manque de documentation, l’absence de journalisation des erreurs, l’absence de messages d’erreur importants pour les utilisateurs, un code fortement couplé, un code trop adapté à un exemple précis, l’absence de caractéristiques souhaitées par les clients et l’absence de rétroaction en cas d’échec. Ces problèmes peuvent avoir de graves répercussions sur la préparation de la production et frustrer les utilisateurs. Si un utilisateur est frustré, sa productivité s’en ressentira, ce qui entraînera des répercussions négatives en aval sur la capacité des entreprises à remplir efficacement leur mission.
Le conseil le plus pratique pour mettre en œuvre un code de niveau de production est de travailler ensemble, d’attribuer des responsabilités et des délais clairs et de comprendre l’importance de chacun de ces concepts. Ce faisant, il devient facile de mettre en œuvre ces pratiques dans les projets et de créer des applications maintenables et évolutives.
Rencontre avec le scientifique des données
Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Collecte par approche participative des données des reçus d’épicerie dans les communautés autochtones à l’aide de la reconnaissance optique de caractères
Par : Shannon Lo, Joanne Yoon et Kimberley Flak
Tout le monde mérite d’avoir accès à des aliments sains et abordables, peu importe où l’on vit. Cependant, de nombreux Canadiens qui vivent dans des communautés nordiques et isolées doivent faire face à des coûts accrus liés aux tarifs d’expédition et aux défis sur le plan des chaînes d’approvisionnement. En réaction aux préoccupations relatives à la sécurité alimentaire dans le Nord, le gouvernement du Canada a créé le programme de subventions Nutrition Nord Canada (NNC). Géré par Relations Couronne-Autochtones et Affaires du Nord Canada (RCAANC), ce programme aide à rendre les aliments nutritifs, comme la viande, le lait, les céréales, les fruits et les légumes, plus abordables et accessibles. Pour mieux comprendre les défis associés à la sécurité alimentaire, il faut disposer de meilleures données sur les prix.
Pour le compte de RCAANC et en collaboration avec le Centre des projets spéciaux sur les entreprises (CPSE), la Division de la science des données de Statistique Canada a réalisé un projet de validation de principe afin d’évaluer si l’approche participative constitue une solution potentielle pour combler les lacunes en matière de données. Ce projet a permis d’évaluer s’il était possible d’utiliser la reconnaissance optique de caractères (ROC) et le traitement du langage naturel (TLN) pour extraire et totaliser des renseignements sur les prix à partir d’images de reçus d’épicerie, en plus de créer une application Web pour téléverser et traiter les images de reçus. Le présent article met l’accent sur un algorithme de détermination et d’extraction de texte. Il ne présente pas le volet réservé à l’application Web.
Données
Les données d’entrée du projet comprenaient des images de reçus d’épicerie pour des achats faits dans des régions autochtones isolées, y compris des photos prises avec un appareil photo et des images numérisées. Le format et le contenu des reçus variaient selon les détaillants. À partir de ces reçus, nous avons cherché à extraire des renseignements sur les prix des produits, ainsi que des renseignements sur les reçus, comme la date et l’emplacement de l’achat, qui fournissent un contexte important en vue d’une analyse subséquente. Les données extraites ont été compilées dans une base de données afin de soutenir les fonctions de validation, d’analyse et de recherche.
Conception générale
La figure 1 illustre le flux de données, de la soumission du reçu à la numérisation, au stockage et à l’affichage. Le présent article se concentre sur le processus de numérisation.
Figure 1: Flux de données
Il s’agit d’un diagramme de processus représentant le flux de données entre les différents processus du projet. Il met en évidence les trois processus de numérisation sur lesquels le présent article sera axé : extraire du texte au moyen de la reconnaissance optique de caractères, corriger l’orthographe et classer le texte, et compiler les données.
Reçu : prendre une photo du reçu
Transférer vers « Application Web » : télécharger à l’aide d’une application Web
Application Web : télécharger à l’aide d’une application Web
Transférer vers « Texte » : extraire du texte au moyen de la reconnaissance optique de caractères
Texte : extraire du texte au moyen de la reconnaissance optique de caractères
Transférer vers « Texte classifié » : corriger l’orthographe et classer le texte
Texte classifié : corriger l’orthographe et classer le texte
Transférer vers « Enregistrement » : compiler les données
Enregistrer : compiler les données
Transférer vers « Base de données protégée » : enregistrer les données
Base de données protégée : enregistrer les données
Transférer vers « Tableau de bord Web » : afficher les données dans le tableau de bord Web
Tableau de bord Web : afficher les données dans le tableau de bord Web
Extraction de texte au moyen de la reconnaissance optique de caractères
Nous avons extrait du texte à partir de reçus en détectant tout d’abord les zones de texte au moyen de la méthode « Character-Region Awareness For Text detection (CRAFT) », puis par la reconnaissance de caractères au moyen de Tesseract, le moteur de ROC de Google. Nous avons choisi CRAFT au lieu d’autres modèles de détection de texte, puisqu’il détecte efficacement du texte dans des zones floues à faible résolution ou dans celles où il manque des points d’encre. Pour en savoir davantage sur CRAFT et Tesseract, voir l’article Comparaison des outils de reconnaissance optique de caractères pour les documents à forte densité de texte et les textes provenant de scènes du Réseau de la science des données.
Tesseract reconnaissait du texte à partir des zones de texte détectées. De manière générale, Tesseract cherchait les alphabets, les chiffres et la ponctuation en français et en anglais. Cependant, dans le cas des zones de texte qui commençaient à l’extrême droite (c.-à-d. celles ayant une coordonnée x à gauche au moins aux trois quarts de la coordonnée x maximale de la zone en question), Tesseract ne cherchait que les chiffres, la ponctuation et certains caractères simples servant à indiquer le type de taxe pour le produit, en supposant que la zone de texte renfermait des renseignements sur le prix. En limitant les caractères à reconnaître, nous évitions que les zéros soient reconnus comme des « O ».
Si Tesseract ne reconnaissait pas de texte dans la zone de texte ou si le niveau de confiance de la reconnaissance était inférieur à 50 %, nous avons d’abord essayé de nettoyer l’image. Les parties de texte qui présentaient une noirceur inégale ou des zones sans encre ont été comblées au moyen de l’égalisation adaptative d’histogramme à contraste limité (CLAHE en anglais). Cette méthode a permis d’améliorer le contraste global de l’image, en calculant l’histogramme de l’intensité des pixels et en répartissant ces pixels dans des plages ayant moins de pixels. La luminosité et le contraste de l’image ont été ajustés pour que le texte noir se démarque encore plus. Ces méthodes de nettoyage ont permis à Tesseract de mieux reconnaître le texte. Cependant, il n’était pas recommandé d’appliquer cette méthode de traitement préalable des images à toutes les zones de texte, puisqu’elle empêchait Tesseract de traiter certaines images prises dans des conditions différentes. Après cette méthode de traitement préalable des images, la reconnaissance de texte n’était utilisée que si la probabilité de reconnaissance de texte augmentait. Lorsque Tesseract échouait même après un traitement préalable des images, le programme utilisait le modèle « Scene Text Recognition (STR) » d’EasyOCR. Cet autre modèle de reconnaissance de texte offrait un meilleur rendement en présence d’images plus bruyantes, lorsque le texte était imprimé avec une quantité d’encre irrégulière ou que l’image était floue.
Vérification de l’orthographe
SymSpell a été entraîné au moyen de noms de produits individuels tirés de la base de données de l’Enquête sur les dépenses des ménages (EDM) de 2019. Pour améliorer la qualité de la correction, le correcteur d’orthographe sélectionnait le mot le plus courant en fonction des mots les plus semblables. Par exemple, si la ligne reconnue était « suo dried tomatoes », le correcteur d’orthographe pouvait corriger le premier mot en utilisant « sub », « sun » et « sum ». Cependant, il choisissait « sun » puisqu’il reconnaissait le digramme « sun dried », mais pas « sub dried ». D’autre part, si la ROC prévoyait que la ligne serait « sub dried tomatoes », aucun mot n’était corrigé, puisque chaque mot était une entrée valide dans la base de données. Nous avons cherché à éviter autant que possible les fausses corrections. Si un caractère n’était pas détecté en raison de la présence de lignes verticales ou du manque d’encre, le caractère manquant était aussi récupéré au moyen de la correction de l’orthographe. Par exemple, si la ligne reconnue était « sun dri d tomatoes », le correcteur d’orthographe corrigeait la ligne pour afficher « sun dried tomatoes ».
Un correcteur d’orthographe distinct corrigeait l’orthographe des noms de magasin et des noms de collectivités.
Classification de texte
Pour déterminer ce que décrivait chaque ligne de texte extrait, un classificateur d’entités au niveau du reçu et un classificateur d’entités au niveau du produit ont été créés. Les sections suivantes décrivent les entités pertinentes, les sources de données d’entraînement, les modèles envisagés et leur rendement.
Entités
Chaque rangée de texte qui était extraite a été classée dans l’un des 11 groupes présentés dans le tableau 1. Cette étape permet de caviarder des renseignements de nature délicate et d’utiliser de manière significative le reste des renseignements.
Tableau 1 : Entités extraites des reçu
Entités au niveau du reçu
Entités au niveau du produit
Autres entités
Date
Nom du magasin
Emplacement du magasin
Sommaire de la vente
Produit
Prix par quantité
Subvention
Réduction
Dépôt
Renseignements de nature délicate (comprend l’adresse du client, le numéro de téléphone et le nom)
Autre
Données d’entraînement du classificateur d’entités
Des données d’entraînement ont été recueillies à partir des reçus étiquetés, de la base de données de l’EDM et de sources publiques, comme les données accessibles dans GitHub. Voir le tableau 2 pour obtenir des renseignements détaillés sur chaque source de données d’entraînement.
Tableau 2 : Sources de données d’entraînement
Données
Enregistrements
Source
Détails supplémentaires
Détails supplémentaires
1,803
RCAANC
ROC utilisée pour extraire des renseignements à partir des images de reçus qui ont ensuite été étiquetés par les analystes.
Produits
76,392
Base de données de l’EDM
2 occurrences et plus
Nom de magasins
8,804
Base de données de l’EDM
2 occurrences et plus
Villes canadiennes
3,427
GitHub
Provinces canadiennes
26
GitHub
Communautés admissibles au programme NNC
Collectivités
131
Nutrition Nord Canada
Communautés admissibles au programme NNC
Collectivités
87,960
GitHub
Considérés comme des renseignements de nature délicate.
Sélection de modèles et réglage des hyperparamètres
Deux classificateurs à classes multiples ont été utilisés, un pour classer les entités au niveau du reçu (c.-à-d. le nom et l’emplacement des magasins), et l’autre pour classer les entités au niveau du produit (c.-à-d. la description du produit, la subvention, le prix par quantité, la réduction et le dépôt). Le tableau 3 décrit les différents modèles utilisés lors de l’expérience, afin de classer les entités au niveau du reçu et au niveau du produit. Le score F1 des macros correspondantes pour les deux différents classificateurs est également fourni.
Tableau 3 : Différents modèles mis à l’essai pour le classificateur des reçus et des produits.
Modèles mis à l’essai
Description
Score F1 selon la macro du classificateur de reçus
Score F1 selon la macro du classificateur de produits
Modèle bayésien naïf multinomial
Le classificateur bayésien naïf multinomial est idéal pour assurer une classification avec des fonctions discrètes (p. ex. nombre de mots pour la classification de texte). [1]
0.602
0.188
Machine à vecteurs de support linéaire avec entraînement au moyen de la descente par gradient stochastique
Cet estimateur met en application des modèles linéaires standardisés (p. ex. machine à vecteurs de support (SVM), régression logistique, etc.) avec entraînement au moyen de la descente par gradient stochastique : le gradient de la perte est évalué pour chaque échantillon à la fois, et le modèle est mis à jour pendant le processus, avec une courbe de force à la baisse (c.-à-d. le taux d’apprentissage). [2]
0.828
0.899
Classification à vecteurs de support linéaire
Semblable à la classification à vecteurs de support avec paramètre kernel = « linéaire », mais mis en œuvre en termes de liblinear plutôt que libsvm, ce modèle offre davantage de souplesse quand vient le temps de choisir des pénalités et des fonctions de perte. Il devrait mieux s’adapter à un grand nombre d’échantillons. Cette classe soutient les données denses et à faible densité. Le support à classes multiples est traité en fonction d’un régime axé sur le principe un contre les autres. [3]
0.834
0.900
Arbre décisionnel
Les arbres décisionnels sont une méthode d’apprentissage supervisé non paramétrique utilisée pour la classification et la régression. [4]
0.634
0.398
Forêt aléatoire
Une forêt aléatoire est un méta-estimateur qui correspond à un certain nombre de classificateurs d’arbres décisionnels pour différents sous-échantillons de l’ensemble de données, et qui utilise le calcul d’une moyenne pour améliorer l’exactitude des prédictions et contrôler le surajustement. [5]
0.269
0.206
XGBoost
XGBoost est une bibliothèque d’amplification de gradient réparti optimisée conçue pour être très efficace, souple et transférable. Elle met en œuvre des algorithmes d’apprentissage automatique dans le cadre d’amplification de gradient. [6]
0.812
0.841
Avant de choisir les modèles, on a réalisé un réglage des hyperparamètres au moyen d’une recherche par quadrillage. Nous avons ensuite utilisé la validation croisée K-Folds stratifiée pour entraîner les modèles et les mettre à l’essai, tenant compte des défis associés au déséquilibre des classes dans l’ensemble de données d’entraînement, qui comprenait principalement des renseignements de nature délicate (49 %) et le nom ou le prix des produits (44 %). La proportion restante de l’ensemble de données (7 %) comprenait des renseignements comme le nom du magasin, l’emplacement, la subvention, la réduction, la date et le prix par quantité. Après les tests et l’entraînement, les modèles affichant le meilleur rendement pour les entités au niveau du reçu et du produit ont été choisis en fonction du score F1 de la macro. Le score F1 de la macro a été utilisé comme déterminant du rendement, parce qu’il évalue l’importance de chaque classe de façon égale. Cela signifie que, même si une classe comporte très peu d’exemples parmi les données d’entraînement, la qualité des prédictions pour cette classe est tout aussi importante que celle d’une classe qui comporte de nombreux exemples. Cette situation se produit souvent dans le cadre d’un projet où l’ensemble des données d’entraînement est déséquilibré, c’est-à-dire que certaines classes ont peu d’exemples, alors que d’autres en ont plusieurs.
Une approche fondée sur les règles a été utilisée pour déterminer les dates, car les formats de dates normalisées font en sorte qu’il s’agit d’une méthode plus robuste.
Le classificateur de classification à vecteurs de support linéaire a été retenu comme le meilleur modèle pour les classificateurs de reçus et de produits en fonction de son score F1 des macros de 0,834 (reçus) et de 0,900 (produits), qui était plus élevé que dans tous les autres modèles mis à l’essai. Même s’il s’agissait du modèle affichant le meilleur rendement, il convient de souligner que l’entraînement des classificateurs de la classification à vecteurs de support prend habituellement plus de temps que les classificateurs bayésiens naïfs multinomiaux.
Coupler du texte ayant fait l’objet d’une reconnaissance optique de caractères à l’enregistrement d’un reçu
Nous avons utilisé les classificateurs entraînés d’entités au niveau du reçu et d’entités au niveau du produit sur différentes parties du reçu. Si nous supposons que le reçu était présenté comme indiqué dans la figure 2, le classificateur d’entités au niveau du reçu prédisait la classe de toutes les lignes extraites du reçu, à l’exception de la section 3 : Produits. Le classificateur d’entités au niveau du produit n’a été utilisé qu’avec la section 3 : Produits. Cette présentation fonctionnait pour tous les reçus de notre ensemble de données. Si un élément, comme le nom d’un magasin, avait été coupé de la photo, ce champ était laissé vide dans le résultat final.
Figure 2 : Présentation du reçu
Cette image d’un reçu montre un exemple des différentes sections d’un reçu.
Nom et adresse du magasin
Relevé de transaction
Produits (description, numéro d’article, prix, réduction, subvention et prix par quantité)
Sous-total, taxes et total
Relevé de transaction
Le début du reçu, où l’on trouve les sections 1) Nom et adresse du magasin et 2) Relevé de transaction, comprend des lignes de texte qui précèdent la ligne qui, selon les prédictions du classificateur de produits, affiche un produit et une valeur en dollars. Nous n’obtenions aucun nom et aucun emplacement de magasin si cette partie était vide et si la première ligne décrivait directement un produit. De l’ensemble du texte reconnu dans cette section, le texte prédit par le classificateur de reçus comme étant le nom du magasin avec la probabilité de prédiction la plus élevée a été attribué comme étant le nom du magasin. Un nom valide de communauté a été extrait des lignes qui, selon les prédictions, représentaient un emplacement. Les lignes qui, selon les prédictions du classificateur de reçus, comprenaient des renseignements de nature délicate dans cette section ont été caviardées.
La partie principale d’un reçu comprenait la section 3) Produits. Chaque ligne qui, selon le classificateur de produits, était un produit et affichait une valeur en dollars était considérée comme un nouveau produit. Toutes les lignes de texte qui suivaient ce produit et qui, selon les prédictions, étaient une subvention, une réduction, un dépôt ou le prix par quantité ont été ajoutées comme renseignements auxiliaires pour le produit. Les subventions ont ensuite été réparties entre la subvention de Nutrition Nord Canada (NNC) et la subvention pour le coût de la vie au Nunavik, en fonction de la description du texte.
La fin du reçu comprenait les sections 4) Sous-total, taxes et total et 5) Relevé de transaction. Aucune donnée ne devait être extraite de ces deux sections. Cependant, les lignes qui, selon les prédictions du classificateur de reçu, comprenaient des renseignements de nature délicate dans cette section ont été caviardées.
La date d’achat figurait au début ou à la fin du reçu. Les données ont donc été analysées en cherchant des tendances connues d’expression habituelle du format de la date dans ces sections du reçu.
Résultats
Nous avons évalué l’algorithme au moyen des photos des reçus d’épicerie de détaillants d’alimentation du Nord se trouvant dans des communautés autochtones éloignées. Des analystes du Centre des projets spéciaux sur les entreprises de Statistique Canada ont étiqueté les produits et les renseignements sur les ventes figurant dans chaque image.
Les textes extraits, notamment le nom des magasins, le nom des communautés, la description des produits et les dates, ont été évalués en fonction d’un score de similarité. La similarité entre les deux textes a été calculée en multipliant par deux le nombre total de caractères correspondants et en divisant le tout par le nombre total de caractères dans les deux descriptions. Les chiffres extraits, comme le prix du produit, la subvention, la réduction et le dépôt, ont été évalués de manière à établir une correspondance (1) ou aucune correspondance (0).
Dans le cas des champs simples, comme le nom des magasins, il était facile de comparer la valeur prédite à la valeur réelle. Néanmoins, il n’a pas été possible de réaliser une simple comparaison univoque entre les multiples éléments saisis manuellement et les multiples éléments prédits par l’algorithme de ROC. Ainsi, chaque élément saisi manuellement a été tout d’abord comparé à l’élément le plus similaire extrait par l’algorithme de ROC. Les éléments correspondants de deux sources devaient afficher un degré de similarité d’au moins 50 %. Les éléments saisis manuellement, mais non saisis par l’algorithme, étaient considérés comme des « éléments manquants ». Les éléments saisis par l’algorithme, mais non saisis manuellement, étaient considérés comme des « éléments supplémentaires ». Une fois les éléments communs appariés, la moyenne des scores de similarité pour toutes les paires a été calculée, afin d’obtenir un score de similarité global pour tous les éléments communs se trouvant sur les reçus.
L’algorithme de ROC excellait quand venait le temps de repérer des produits sur les reçus. Parmi les 1 637 produits figurant sur les reçus, 1 633 (99,76 %) ont été saisis (tableau 4). Le taux de similarité moyen de la description du produit atteignait 96,85 % (tableau 5). L’algorithme échouait lorsque le texte dans l’image était coupé, flou ou plissé, ou s’il manquait d’encre. C’est pourquoi nous avons recommandé que les extractions par ROC soient suivies par une vérification humaine réalisée au moyen de l’interface Web. Dans le cas des produits communs, les prix ont été extraits avec exactitude dans 95,47 % des cas, dans 99,14 % des cas pour les subventions de NNC, dans 99,76 % des cas pour la subvention pour le coût de la vie au Nunavik, dans 100,00 % des cas pour les réductions, dans 99,76 % des cas pour les dépôts, dans 95,71 % des cas pour le prix par quantité, et dans 95,22 % des cas pour les numéros d’article (tableau 5).
Même si la description des produits et les prix étaient toujours présents, d’autres champs, comme la subvention de NNC, n’étaient présents que lorsque c’était approprié. C’est pourquoi le tableau 5 fait aussi état des exactitudes limitées aux champs non manquants, afin d’évaluer uniquement le rendement de la ROC. Aucune entrée sur les réductions ne figurait dans ce lot de reçus. Nous avons donc utilisé un autre lot pour évaluer l’exactitude de l’extraction des réductions, qui l’ont été 98,53 % du temps. Le score de similarité du texte pour les champs observés et ayant fait l’objet d’une ROC était de 87,1 %.
Tableau 4 : Produits extraits des reçus de RCAANC
Nombre de reçus
Nombre d’éléments
Nombre d’éléments extraits
Nombre d’éléments en commun
Nombre d’éléments en commun
Pourcentage d’éléments supplémentaires
182
1,637
1,634
1,633
0.24% (4/1,637)
0.06% (1/1,630)
Tableau 5 : Exactitude de la ROC sur les renseignements au niveau du produit
Description du produit
(Score moyen de similarité du texte)
Prix
(% d’exactitude)
Subvention de NNC
(% d’exactitude)
Subvention pour le coût de la vie au Nunavik
(% d’exactitude)
Réduction
(% d’exactitude)
Dépôt
(% d’exactitude)
Numéro d’article
(% d’exactitude)
Numéro d’article
(% d’exactitude)
Exactitude des éléments en commun
96.85%
95.47% (1,559/1,633)
99.14% (1,619/1,633)
99.76% (1,629/1,633)
100.0% (1,633/1633)
99.76% (1,629/1,633)
95.71% (1,563/1,633)
95.22% (1,555/1,633)
Exactitude des éléments en présence de champs
96.85%
95.47% (1,559/1,633)
99.08% (647/653)
100.0% (282/282)
Not available. No actual occurrence
97.56% (160/164)
72.97% (81/111)
95.52% (1,555/1,628)
Les renseignements sur les reçus ont été extraits de façon efficace sans qu’aucune communauté, aucun nom de magasin ou aucune date n’ait été complètement omis ou faussement assigné. Le score moyen de similarité du texte était constamment élevé : 99,12 % pour la communauté, 98,23 % pour les noms de magasins, et 99,89 % pour les dates. L’utilisation de l’algorithme de ROC et du classificateur d’entités de reçu pour traiter les reçus semble prometteuse.
En outre, 88,00 % des renseignements de nature délicate ont été caviardés correctement. Parmi les renseignements qui n’ont pas été caviardés, il s’agissait en grande partie des numéros d’identification des caissiers. Ces données n’ont pas été caviardées, car le classificateur d’entités n’avait jamais vu ce type de renseignement de nature délicate. Un nouvel entraînement du classificateur d’entités au moyen d’exemples de numéros d’identification de caissiers permettra d’améliorer les résultats, comme cela se produit dans le cas du nom des caissiers, alors que le classificateur reconnaît que les noms des caissiers sont des renseignements de nature délicate, en raison d’exemples comme « <Nom du caissier> était votre caissier aujourd’hui » dans ses données d’entraînement.
Tableau 6 : Exactitude de la ROC sur les renseignements au niveau du reçu
Nombre de reçus
Nom du magasin
(Score moyen de similarité du texte)
Nom du magasin
(Score moyen de similarité du texte)
Nom du magasin
(Score moyen de similarité du texte)
Renseignements de nature délicate
(% de rappel)
Évaluation
182
98.23%
99.12%
99.89%
88.80
Évaluation en présence de champs
164
99.02%
99.88%
98.03%
Not applicable
Conclusion
Ce projet a montré qu’une classification d’entités et un algorithme de ROC peuvent saisir, avec exactitude, différentes composantes des reçus d’épicerie des détaillants du Nord. L’automatisation de ce processus facilite la collecte de données sur le coût de la vie dans le Nord. Si cette solution est mise de l’avant, l’automatisation devrait être suivie par un processus de validation avec intervention humaine, par l’intermédiaire d’une interface Web, afin de s’assurer que les reçus soient numérisés correctement et que les corrections soient utilisées, de manière itérative, pour réaliser un nouvel entraînement. Cette fonction de validation a été mise en œuvre, mais n’est pas abordée dans le présent article.
Les données anonymisées agrégées qui sont recueillies dans le cadre d’une approche participative pourraient fournir de meilleures explications associées au coût élevé des aliments dans les communautés autochtones isolées, en plus d’accroître la transparence et la reddition de comptes des bénéficiaires de la subvention Nutrition Nord Canada auprès des résidents de ces communautés. Si vous souhaitez en apprendre davantage sur le volet de l’application Web, veuillez envoyer un courriel, à datascience@statcan.gc.ca.
Rencontre avec le scientifique des données
Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 15 juin
De 13 00 h à 16 00 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Alors que les mouvements sociaux en faveur des droits des Autochtones, de la lutte contre le racisme et de l’équité économique prennent de l’ampleur au Canada, de nombreuses discussions se tiennent à l’échelle nationale sur l’équité, la diversité et l’inclusion. Statistique Canada répond à l’appel des Canadiens qui souhaitent obtenir des données détaillées pour éliminer les disparités entre les genres, le racisme et les autres barrières systémiques.
Dans le cadre du Plan d’action sur les données désagrégées annoncé dans le budget de 2021, Statistique Canada travaille en collaboration avec les Canadiens en vue de produire de meilleures données, qui permettront de prendre de meilleures décisions.
Ce plan d’action vise à combiner les données et à les répartir en sous-catégories selon le genre, la race, l’âge, l’orientation sexuelle, l’incapacité (ou une combinaison de ces facteurs). Le processus permettra de lever le voile sur les inégalités économiques et sociales au pays. Pour que chaque Canadien puisse atteindre son plein potentiel, nous devons bien comprendre les circonstances dans lesquelles vivent les gens ainsi que les obstacles auxquels ils sont confrontés. Nous ne pouvons pas améliorer ce que nous ne pouvons pas mesurer.
Pour pouvoir offrir davantage de données désagrégées, Statistique Canada explore de nouvelles façons sécuritaires de tirer le maximum des données qui ont déjà été recueillies (p. ex. en combinant de façon sécuritaire ses données de recensement et d’enquête avec des données déjà recueillies par d’autres organismes fédéraux, provinciaux ou territoriaux [parfois appelées « données administratives »]).
En couplant ainsi les données, nous pourrons réduire le fardeau des Canadiens en réutilisant les données qu’ils ont déjà transmises au gouvernement. Nous pourrons également améliorer l’exactitude des données et élargir l’éventail de résultats et de renseignements qu’elles permettent d’obtenir. Le couplage de données est une activité qui se fait depuis de nombreuses années à Statistique Canada, conformément à la Directive sur le couplage de microdonnées de l’organisme.
La nouvelle Infrastructure sécurisée pour l’intégration des données (ISID) de Statistique Canada, qui en est actuellement aux phases de consultation et de construction, offre un ensemble de méthodes, de technologies et de protocoles qui permettront d’améliorer la façon dont l’organisme combine ses données existantes avec celles d’autres organisations.
L’ISID repose sur de solides principes en matière de protection de la vie privée. Les fichiers de données couplées sont nettoyés de tout identificateur personnel (nom, adresse, numéro d’assurance sociale, etc.) immédiatement après le couplage et avant l’analyse et l’utilisation des données.
Tous les renseignements recueillis dans le cadre des recensements et des enquêtes de Statistique Canada, ainsi que les données administratives provenant de tiers, sont protégés en vertu de la Loi sur la statistique, de la Loi sur l’accès à l’information et de la Loi sur la protection des renseignements personnels. En vertu de la loi, aucun renseignement personnel recueilli par Statistique Canada n’est communiqué à une autre organisation ou à une autre personne, même au sein du gouvernement du Canada. De plus, les employés de Statistique Canada prêtent un serment de discrétion et sont passibles d’une amende et/ou d’une peine d’emprisonnement s’ils divulguent illégalement des renseignements confidentiels.
En créant un environnement sécuritaire pour combiner les données, Statistique Canada maximise les renseignements dont il dispose, ce qui permettra de bâtir un Canada plus équitable en intégrant les facteurs d’équité et d’inclusion dans la prise de décisions.
Si vous désirez en savoir plus sur notre infrastructure sécurisée pour l’intégration des données, envoyez-nous un courriel pour obtenir plus de détails sur l’expérience canadienne dans la construction d’une infrastructure de registres statistiques intégrés de manière responsable sur le plan de la protection des renseignements personnels : statcan.statisticalregisters-registresstatistiques.statcan@statcan.gc.ca
L’application StatsCAN recueille-t-elle des renseignements personnels?
Comment puis-je enregistrer une publication?
Non. L’application StatsCAN ne recueille pas de renseignements personnels, comme votre nom, votre numéro de téléphone ou votre adresse de courriel. Aucun renseignement personnel n’est requis pour accéder à l’application ou l’utiliser. Statistique Canada obtiendrait ce type de renseignement seulement si vous le fournissez, en envoyant un courriel ou en remplissant un formulaire en ligne.
Pendant combien de temps les publications sont-elles conservées dans mes Éléments sauvegardés?
Avec votre consentement, Statistique Canada reçoit des statistiques agrégées et des renseignements anonymes sur votre utilisation de l’application StatsCAN fournis par Firebase, un tiers fournisseur de services, qui utilise Google Analytics.
Par renseignements agrégés, on entend des données qui ont été combinées ou résumées à partir de points de données individuels sous une forme collective. Ce type de renseignement fournit une vue d’ensemble ou un résumé général des renseignements sans révéler de détails particuliers sur les points de données individuels. Par exemple, des renseignements agrégés peuvent comprendre des valeurs moyennes, des totaux ou des pourcentages obtenus à partir de multiples points de données.
Les renseignements anonymes sont des données qui ont été rendues anonymes ou ont été dépersonnalisées dans la mesure où elles ne peuvent pas être utilisées pour identifier ou distinguer des personnes, ce qui permet de protéger leur vie privée.
Quels renseignements StatsCAN recueille-t-elle?
Comment puis-je supprimer une publication sauvegardée?
Avec votre consentement, l’application StatsCAN recueille les renseignements suivants :
Renseignements sur votre appareil et l’application
marque, modèle, type, système d’exploitation et version de l’appareil;
données de localisation (pays, province, ville);
installations, mises à jour et désinstallations de l’application;
version de l’application;
renseignements sur les pannes de l’application ou d’autres problèmes liés à l’application;
identifiant publicitaire de l’appareil;
identifiant d’instance de l’application;
Renseignements sur vous, à titre d’utilisateur ou d’utilisatrice
fourchette d’âge;
genre;
sujets que vous suivez;
types de publications que vous avez lues, enregistrées et partagées;
temps que vous avez passé à utiliser l’application;
préférences concernant les réglages que vous avez choisis à titre d’utilisateur ou d’utilisatrice et renseignements sur l’utilisation;
préférences sur les notifications intégrées à l’application et les notifications poussées, et renseignements sur l’utilisation.
Il convient de noter que des seuils sont imposés pour les données démographiques (c’est-à-dire la fourchette d’âge et le genre) et que les données seront affichées uniquement si elles respectent les seuils d’agrégation minimaux.
Les renseignements sur vos préférences, comme vos sujets d’intérêt, votre langue préférée et vos réglages, y compris les notifications, qui sont désactivées par défaut et que vous pouvez activer si vous le souhaitez, seront stockés sur votre appareil et utilisés pour afficher les renseignements selon vos préférences.
Avec qui les renseignements sont-ils partagés?
Comment puis-je partager une publication?
Avec votre consentement, l’application StatsCAN partage les données recueillies directement et en toute sécurité avec Firebase, le tiers fournisseur de services analytiques. L’application ne partagera jamais vos données personnelles avec l’équipe de l’application StatsCAN ou tout autre représentant de Statistique Canada. Les renseignements sur l’utilisation de l’application partagés avec Firebase sont agrégés et anonymisés avant d’être partagés avec l’équipe de l’application StatsCAN.
Comment les renseignements recueillis par l’application StatsCAN sont-ils utilisés?
Comment puis-je savoir que de nouvelles publications sont accessibles?
Statistique Canada utilisera seulement les statistiques agrégées et les renseignements anonymes fournis par les tiers fournisseurs de services analytiques dans le but d’améliorer le rendement de l’application StatsCAN, sa fonctionnalité et l’expérience utilisateur globale.
Les données que nous recueillons sont analysées pour évaluer le rendement du contenu et favoriser l’élaboration de contenu qui correspond aux intérêts et aux préférences des utilisateurs. Les données peuvent également être utilisées pour analyser les modèles d’interaction des utilisateurs, leur comportement et leurs préférences de navigation (p. ex. la façon dont les utilisateurs accèdent au contenu et ce qu’ils lisent dans l’application StatsCAN) en vue d’optimiser la circulation des renseignements dans l’application ou de mener des études de marché.
Les renseignements recueillis au moyen du formulaire Contactez-nous servent strictement à répondre aux demandes de renseignements, à obtenir des commentaires sur l’application, à corriger les bogues ou les erreurs.
Pendant combien de temps les renseignements sont-ils stockés?
Avec qui puis-je communiquer si j'ai des questions à propos d'une publication?Depuis une publication, vous pouvez communiquer avec nous en touchant le menu des options (...) situé au coin supérieur droit de l'écran, et en sélectionnant l'option Contactez-nous.
Pour connaître les politiques et les procédures de conservation et de suppression des données du tiers fournisseur de services analytiques de l’application StatsCAN, veuillez consulter la documentation suivante :
Cette application peut-elle localiser ma position?
Avec qui puis-je communiquer si j'ai des questions à propos d'une publication?
Avec votre consentement, Statistique Canada reçoit des statistiques agrégées et des renseignements anonymes sur votre utilisation de l’application StatsCAN fournis par Firebase, un tiers fournisseur de services, dont les données sur votre emplacement (pays, province et ville).
StatsCAN n’utilise pas de renseignements provenant de réseaux cellulaires, Wi-Fi et GPS (système mondial de positionnement), ni n’utilise Bluetooth pour déterminer et suivre votre emplacement précis, vos mouvements ou vos activités (comme la géolocalisation, l’accès à la caméra, l’accès au microphone ou l’intégration au calendrier).
Publications
Comment puis-je enregistrer une publication?
Comment puis-je enregistrer une publication?
Vous n’avez peut-être pas toujours le temps de lire vos publications préférées immédiatement. Vous pouvez sauvegarder une publication pour la lire à un moment qui vous convient en sélectionnant l’icône représentant le contour d’un signet, dans le coin supérieur droit de la page d’une publication. Un message s’affichera temporairement pour confirmer que la publication a été ajoutée à votre page Sauvegardés, et l’icône de signet deviendra pleine.
Vous pouvez accéder à vos publications enregistrées en allant à la page Sauvegardés à partir du menu au bas de l’écran.
Veuillez noter que vous pouvez consulter vos publications sauvegardées uniquement lorsque vous êtes connecté(e) à Internet.
Pendant combien de temps les publications sont-elles conservées dans mes Éléments sauvegardés?
Pendant combien de temps les publications sont-elles conservées dans mes Éléments sauvegardés?
Il n'y a pas de limite de temps. Les publications figureront parmi vos Éléments sauvegardés jusqu'à ce que vous choisissiez de les supprimer.
Comment puis-je supprimer une publication sauvegardée?
Comment puis-je supprimer une publication sauvegardée?
Vous pouvez supprimer une publication de vos Éléments sauvegardés en touchant l’icône représentant un signet rempli s’affichant dans la vignette de la publication, à côté de l’image de l’article.
Un message apparaîtra, vous demandant de confirmer que vous souhaitez supprimer la publication en question.
Comment puis-je partager une publication?
Comment puis-je partager une publication?
Vous pouvez partager des faits divertissants, des éléments visuels, de brèves histoires et des renseignements clés depuis l'application StatsCAN avec des amis et des collègues.
Vous pouvez partager du contenu par courriel, par texto ou au moyen de vos plateformes préférées des médias sociaux.
Accédez à la fonction 'Partager' en choisissant tout d'abord une publication, puis en sélectionnant Partager cette publication dans le menu des options (…) situé au coin supérieur droit.
La fonction 'Partager' est également accessible au bas de l'écran de la publication.
Les plateformes par défaut de votre appareil vous seront suggérées pour partager le contenu.
Comment puis-je savoir que de nouvelles publications sont accessibles?
Comment puis-je savoir que de nouvelles publications sont accessibles?
Vous pouvez être informé lorsque de nouvelles publications sont accessibles en activant les notifications dans l'application. Pour ce faire, allez à Paramètres > Préférences > Gérer les notifications.
Dans la section Type de notification, faites glisser le bouton à bascule de Notifications dans l'application à Activées.
Vous serez ainsi informé lorsqu'une nouvelle publication associée à un sujet que vous suivez est accessible.
Avec qui puis-je communiquer si j'ai des questions à propos d'une publication?
Avec qui puis-je communiquer si j'ai des questions à propos d'une publication?
Depuis une publication, vous pouvez communiquer avec nous en touchant le menu des options (...) situé au coin supérieur droit de l'écran, et en sélectionnant l'option Contactez-nous.
Une fonction de clavardage (icône bleue avec bulles de clavardage se trouvant au coin inférieur droit de l'écran) est également offerte à l'écran Contactez-nous. Il s'agit du clavardage en direct de Statistique Canada, au moyen duquel vous pouvez communiquer avec des agents de Statistique Canada pour obtenir immédiatement du soutien, pendant les heures d'ouverture habituelles.
Vous pouvez également fournir vos commentaires, suggestions ou questions à Paramètres > Soutien et rétroactions > Contactez-nous.
Vous trouverez aussi notre adresse de courriel et notre numéro de téléphone à Paramètres > Soutien et rétroactions > Aide et FAQ.
Rechercher
Pourquoi les mots-clés utilisés pour faire mes recherches sont-ils conservés sous Recherches récentes?
Pourquoi les mots-clés utilisés pour faire mes recherches sont-ils conservés sous Recherches récentes?
StatsCAN stocke les cinq mots-clés les plus récents qui ont servi à faire une recherche. Vous pouvez donc les réutiliser rapidement s'il y a lieu.
Puis-je effacer l'historique de la recherche?
Puis-je effacer l'historique de la recherche?
Oui. Vous pouvez effacer vos recherches récentes à Paramètres > Préférences > Effacer l'historique de recherche. Touchez Effacer dans la fenêtre en incrustation pour confirmer, ou Annuler pour annuler l'action.
Notifications
Comment puis-je activer ou désactiver les notifications?
Comment puis-je activer ou désactiver les notifications?
Vous pouvez gérer vos préférences en matière de notifications à Paramètres > Préférences > Gérer les notifications.
Dans la section Type de notification, faites glisser le bouton à bascule de Notifications dans l’application à Activées ou à Désactivées.
Comment puis-je indiquer qu'une notification a été lue?
Comment puis-je indiquer qu'une notification a été lue?
En touchant le titre d'une publication à l'écran Notifications, vous pouvez lire la publication. De plus, cette action permet d'indiquer que la notification a été lue.
Si vous souhaitez indiquer que toutes les notifications ont été lues, sélectionnez le menu des options (...) se trouvant au coin supérieur droit de l'écran Notifications, avant de sélectionner Tout marquer comme lu.
Comment puis-je supprimer une notification?
Comment puis-je supprimer une notification?
Vous ne pouvez pas supprimer manuellement des notifications. Les 25 notifications les plus récentes qui ont été reçues s'afficheront à l'écran Notifications et les notifications plus anciennes seront supprimées automatiquement.
Pendant combien de temps les notifications sont-elles conservées?
Pendant combien de temps les notifications sont-elles conservées?
Il n'y a pas de limite de temps. Les 25 notifications les plus récentes qui ont été reçues s'afficheront à l'écran Notifications. Les notifications plus anciennes seront supprimées automatiquement.
Autre
Je veux informer mes amis et ma famille au sujet de StatsCAN. Puis-je partager l'application avec eux?
Je veux informer mes amis et ma famille au sujet de StatsCAN. Puis-je partager l'application avec eux?
Absolument. Pour partager l'application StatsCAN, allez à Paramètres > Soutien et rétroactions > Partager cette application.
Les options de partage de votre appareil s'afficheront au bas de l'écran. Vous pourrez ensuite choisir comment partager l'application au moyen de ces options.
Avec qui puis-je communiquer si j'ai des questions à propos de StatsCAN ou souhaite fournir une rétroaction sur l'application?
Avec qui puis-je communiquer si j'ai des questions à propos de StatsCAN ou souhaite fournir une rétroaction sur l'application?
Si vous souhaitez évaluer ou commenter publiquement l’application, vous pouvez le faire par l’intermédiaire de l’App Store ou Google Play.
Pour fournir une évaluation au moyen d’un appareil Apple, touchez l’icône de l’App Store. Allez ensuite à la page de l’application StatsCAN. Vous devez avoir téléchargé l’application pour pouvoir laisser un commentaire. Faites défiler la page de l’application jusqu’à la section Notes et avis et touchez Tout voir. Depuis la page Notes et avis, touchez les icônes en forme d’étoile pour évaluer l’application. Touchez le lien Rédiger un avis pour rédiger un commentaire. Touchez Envoyer.
Pour fournir une rétroaction au moyen d’un appareil Android, touchez l’icône du Play Store. Allez ensuite à la page des détails de l’application StatsCAN. Vous devez avoir téléchargé l’application pour pouvoir laisser un commentaire. Faites défiler la page jusqu’à la section Avis. Sélectionnez le nombre d’étoiles, et touchez Donnez votre avis. Suivez les directives figurant à l’écran pour rédiger un commentaire et ajouter des détails. Touchez Afficher.
Où puis-je trouver les conditions d'utilisation de StatsCAN lorsque je les ai acceptées?
Où puis-je trouver les conditions d'utilisation de StatsCAN lorsque je les ai acceptées?
Vous pouvez consulter les conditions d'utilisation à Paramètres > Plus d'information > Conditions d'utilisation.
Statistique Canada se réserve le droit de modifier ces conditions d'utilisation à sa seule discrétion. Il vous incombe d'en prendre connaissance de temps en temps. Toute modification aux conditions d'utilisation entrera en vigueur au moment de sa publication. Votre utilisation continue de l'application à la suite de la publication des conditions d'utilisation modifiées constitue votre acceptation de celles-ci.
Utilisation responsable de l'apprentissage automatique à Statistique Canada
Par : Keven Bosa, Statistique Canada
De plus en plus de données sont générées au quotidien. On n'a qu'à penser aux données de téléphonie cellulaire, d'images satellites, de navigation sur internet ou de lecteur optique. La profusion de données fait grandir l'appétit de la population pour des statistiques nouvelles, plus détaillées et plus actuelles. Comme plusieurs autres organismes nationaux de statistique, Statistique Canada a adhéré à cette nouvelle réalité et utilise de plus en plus de sources de données alternatives afin d'améliorer et moderniser ses différents programmes statistiques. Étant donné leur volume et leur vélocité, des méthodes d'apprentissage automatique sont souvent nécessaires pour utiliser ces nouvelles sources de données.
L'utilisation de l'apprentissage automatique comprend son lot d'avantages : traitement des données volumineuses et non structurées, automatisation des processus en place, amélioration de la couverture et de la précision et bien d'autres. Toutefois, elle soulève aussi plusieurs questions. Par exemple :
Est-ce que le processus protège l'intégrité et la confidentialité des données?
Est-ce que la qualité des données d'entraînement est adéquate pour le but poursuivi?
Une fois l'algorithme mis en place, qui est responsable des résultats et des effets qui en découlent?
Suite à ces questions et à l'augmentation de l'utilisation de méthodes d'apprentissage automatique à Statistique Canada, la Direction des méthodes statistiques modernes et de la science des données a reconnu le besoin d'un cadre pour guider l'élaboration des processus d'apprentissage automatique et d'en faire des processus responsables.
Avant de présenter le cadre de travail dont s'est doté Statistique Canada, nous ferons un bref survol de la Directive sur la prise de décisions automatisée établie par le Secrétariat du conseil du trésor. Celle-ci a d'ailleurs fait l'objet d'un article présenté dans l'édition du mois de juin du bulletin. Il y est mentionné que : « La présente Directive a pour objet de veiller à ce que les systèmes décisionnels automatisés soient déployés d'une manière qui permet de réduire les risques pour les Canadiens et les institutions fédérales, et qui donne lieu à une prise de décisions plus efficace, exacte et conforme, qui peut être interprétée en vertu du droit canadien. » Il est aussi mentionné que la Directive « … s'applique à tout système, outil ou modèle statistique utilisé pour recommander ou prendre une décision administrative au sujet d'un client.». À Statistique Canada, tous les projets utilisant l'apprentissage automatique ou, de façon plus générale la modélisation, font partie d'un programme statistique dont le but n'est pas de prendre des décisions administratives sur un client, du moins, pas jusqu'à présent. Statistique Canada n'a donc pas encore eu à se conformer à cette Directive et à évaluer l'incidence de ces décisions à l'aide de l'Outil d'évaluation de l'incidence algorithmique. Toutefois, comme mentionné à la fin de la section précédente, Statistique Canada a été proactif en adoptant ce Cadre afin de s'assurer d'une utilisation responsable de l'apprentissage automatique au sein de l'agence.
La figure 1 donne un bon aperçu du Cadre pour l’utilisation des processus d’apprentissage automatique de façon responsable à Statistique Canada.
Description - Figure 1
Diagramme de flux circulaire décrivant les 4 concepts essentiels pour la production d'informations fiables à partir de processus d'apprentissage automatique responsables. À partir du haut à gauche et en se déplaçant dans le sens des aiguilles d'une montre :
Concept # 1: Respect des Personnes avec pour attributs : Valeur pour les Canadiens; Prévention des dommages; Équité et responsabilité.
Concept #2 : Application Rigoureuse avec pour attributs : Transparence; Reproductibilité du processus et des résultats.
Concept #3 : Méthodes Éprouvées avec pour attributs : Qualité des données d'apprentissage; Inférence valide; Modélisation rigoureuse et Explicabilité.
Concept #4 : Respect des Données avec pour attributs : Protection de la vie privée; Sécurité et Confidentialité.
Évaluation au moyen de l'auto-évaluation et de l'examen par les pairs, liste de vérification et production d'un rapport ou d'un tableau de bord.
Le cadre comprend des lignes directrices pour l'usage responsable de l'apprentissage automatique organisées en quatre thèmes : respect des personnes; respect des données; application rigoureuse; méthodes éprouvées. Les quatre thèmes mis en commun assurent l'utilisation éthique des algorithmes et des résultats de l'apprentissage automatique. Ces lignes directrices s'appliquent à tous les programmes et projets statistiques menés par Statistique Canada qui utilisent des algorithmes d'apprentissage automatique, particulièrement ceux mis en production. Cela comprend les algorithmes d'apprentissage supervisé et non supervisé.
Le thème respect des personnes est décrit à l'aide de quatre attributs.
Le concept de valeur pour les Canadiens dans un contexte d'apprentissage automatique implique que son utilisation doit avoir une valeur ajoutée, que ce soit dans les produits eux-mêmes ou par une plus grande efficacité dans le processus de production.
La prévention des préjudices nécessite d'être au courant des dangers potentiels et d'avoir un dialogue constructif avec les intervenants et les porte-paroles du milieu avant la mise en œuvre d'un projet d'apprentissage automatique.
L'équité implique que le principe de la proportionnalité entre les moyens et les fins soit respecté, et qu'un équilibre soit maintenu entre des intérêts et des objectifs différents. L'équité veille à ce que les personnes et les groupes ne soient pas victimes de préjugés injustes, de discrimination ou de stigmatisation.
L'imputabilité est l'obligation juridique et éthique d'une personne ou d'une organisation d'être responsable de son travail et de communiquer les résultats du travail de façon transparente. Les algorithmes ne sont pas responsables; quelqu'un est responsable des algorithmes.
Statistique Canada prend les données au sérieux. Le thème respect des données a trois attributs : la protection de la vie privée des personnes auxquelles les données appartiennent; la sécurité des renseignements tout au long du cycle de vie des données; et la confidentialité de renseignements identifiables.
La vie privée est le droit de se retirer et de ne pas être sujet à une quelconque forme de surveillance ou d'intrusion. Lors de l'acquisition de renseignements de nature délicate, les gouvernements ont des obligations relativement à la collecte, à l'utilisation, à la divulgation et à la conservation des renseignements personnels. Le terme vie privée réfère généralement à des renseignements concernant des particuliers (définition tirée de Politique sur la protection des renseignements personnels et la confidentialité).
La sécurité représente les dispositions fondées sur l'évaluation de la menace et des risques qu'utilisent les organisations pour empêcher l'obtention ou la divulgation inadéquate de renseignements confidentiels. Les mesures de sécurité protègent aussi l'intégrité, la disponibilité et la valeur des fonds de renseignements. Cela englobe les protections matérielles, comme l'accès restreint aux zones où les renseignements sont entreposés et utilisés ou les autorisations de sécurité des employés, ainsi que les protections technologiques utilisées pour empêcher l'accès électronique non autorisé (définition tirée de la Politique sur la protection des renseignements personnels et la confidentialité).
La confidentialité fait référence à la protection contre la divulgation de renseignements personnels identifiables concernant une personne, une entreprise ou une organisation. La confidentialité suppose une relation de « confiance » entre le fournisseur de renseignements et l'organisation qui les recueille; cette relation s'appuie sur l'assurance que ces renseignements ne seront pas divulgués sans l'autorisation de la personne ou sans l'autorité législative appropriée (définition tirée de la Politique sur la protection des renseignements personnels et la confidentialité).
Une application rigoureuse signifie de mettre en place, de maintenir et de documenter les processus d'apprentissage automatique de façon à ce que les résultats soient toujours fiables et que l'ensemble du processus puisse être compris et recréé. Ce thème a deux attributs : la transparence et la reproductibilité du processus et des résultats.
La transparence fait référence au fait d'avoir une justification claire de la raison pour laquelle cet algorithme et les données d'apprentissage sont les plus appropriés pour l'étude en cours. Pour être transparents, les développeurs devraient produire une documentation complète, y compris rendre accessible le code informatique à d'autres personnes, et ce, sans compromettre la confidentialité ou la protection des renseignements personnels.
La reproductibilité du processus signifie qu'il y a suffisamment de documentation et que le code informatique a été suffisamment partagé pour faire en sorte que le processus soit reproduit, à partir de rien. La reproductibilité des résultats signifie que les mêmes résultats peuvent être reproduits de façon fiable lorsque toutes les conditions sont contrôlées. Il n'y a pas d'étapes qui modifient les résultats à la suite d'une intervention ponctuelle ou humaine.
Les méthodes éprouvées sont celles qui peuvent être invoquées de manière efficace et efficiente afin de produire les résultats espérés. Statistique Canada suit habituellement des protocoles reconnus qui comportent une consultation avec des pairs et des experts, de la documentation et des tests lorsque nous élaborons des méthodes éprouvées. Ce thème a quatre attributs : la qualité des données d'apprentissage; l'inférence valide; la modélisation rigoureuse; l'explicabilité.
Dans un contexte d'apprentissage automatique, la qualité des données d'apprentissage est mesurée par la cohérence et l'exactitude des données étiquetées. La couverture, ce qui signifie que les étiquettes et les descriptions couvrent tous les cas auxquels l'algorithme peut faire face dans la production, est également importante pour réduire le risque de partialité ou de discrimination (équité). La couverture est également importante pour assurer la représentativité des variables, ce qui est important lorsqu'on veut obtenir des mesures de rendement réalistes.
Une inférence valide désigne la capacité d'obtenir, à partir d'un échantillon, des conclusions plausibles et d'une précision connue de la population cible. Dans un contexte d'apprentissage automatique, une conclusion valable signifie que les prédictions à partir de données tests (jamais utilisées pour la modélisation) doivent être, dans une grande proportion, raisonnablement près de leurs vraies valeurs ou, dans le cas de données catégoriques, les prédictions sont exactes dans une grande proportion.
Une modélisation rigoureuse en apprentissage automatique consiste à s'assurer que les algorithmes sont vérifiés et validés. Cela permettra aux utilisateurs et aux décideurs de faire confiance à l'algorithme à juste titre du point de vue de l'adaptation des données à leur utilisation, de la fiabilité et de la robustesse.
Un modèle qui est explicable est un modèle qui est suffisamment documenté. Les documents doivent expliquer clairement de quelle façon les résultats devraient être utilisés et permettre de déterminer quelles conclusions on peut tirer ou encore ce qui devrait être exploré plus en profondeur. En d'autres mots, un modèle explicable n'est pas une boîte noire.
Processus de revue
Le processus de revue constitue la mise en œuvre du Cadre. L'accent est mis sur les projets ayant des visées pour l'utilisation de méthodes d'apprentissage automatique dans une ou plusieurs étapes menant à la production de statistiques officielles. Le processus comprend trois étapes : l'auto-évaluation à l'aide de la liste de contrôle; l'évaluation par des pairs; une présentation du projet au comité d'examen scientifique de la Direction des méthodes statistiques modernes et de la science des données.
Dans un premier temps, l'équipe ayant développé le projet à l'aide de méthodes d'apprentissage automatique devra faire une auto-évaluation concernant l'utilisation de ces techniques. Pour se faire, l'équipe devra prendre connaissance du Cadre et répondre aux questions présentes dans la liste de contrôle. La liste de contrôle prend la forme d'un questionnaire où, de façon générale, chaque ligne directrice du Cadre est reformulée sous forme d'une ou plusieurs questions. Par la suite, ce questionnaire et la documentation du projet et des méthodes utilisées sont envoyés à l'équipe de revue.
L'évaluation par les pairs peut maintenant débuter. Des réviseurs provenant de deux équipes différentes seront impliqués. Les questions et la documentation concernant les deux premiers thèmes du Cadre, respect des personnes et respect des données, seront évaluées par l'équipe du Secrétariat de l'éthique des données alors que la partie concernant les deux derniers thèmes, application rigoureuse et méthodes éprouvées, sera évaluée par une équipe de la section des méthodes et de la qualité en science des données. À la fin de cette évaluation, un rapport contenant des recommandations sera envoyé au gestionnaire du projet.
La dernière étape du processus de revue est la présentation du projet au comité d'examen scientifique de la Direction des méthodes statistiques modernes et de la science des données. Cette présentation expose la méthodologie utilisée lors du processus d'apprentissage automatique devant un comité d'experts. Le rôle de ce comité est de remettre en question la méthodologie notamment en identifiant certaines lacunes ou problèmes potentiels et en proposant des améliorations et des corrections. Ultimement, ce comité recommandera ou non la mise en œuvre de la méthodologie proposée dans le contexte de production de statistiques officielles.
Et après?
Est-ce la fin de l'histoire? Non, en fait c'est plutôt le début. De nouvelles sources de données et méthodes d'apprentissage automatique émergent pratiquement chaque jour. Afin de demeurer pertinent, le Cadre présenté dans cet article devra être fréquemment adapté et révisé pour tenir compte des nouveaux enjeux d'éthique et de qualité. Statistique Canada continue à appliquer ce Cadre aux processus qui utilisent l'apprentissage automatique et est à l'affût d'applications où la Directive sur la prise de décisions automatisée pourrait s'appliquer. L'agence va constituer un registre de toutes les applications qui ont passé ce processus de revue pour pouvoir y référer facilement. Et vous, faites-vous face à des questions concernant l'utilisation responsable de certaines méthodes d'apprentissage automatique? Avez-vous déjà appliqué la Directive du Secrétariat du Conseil du trésor et avez-vous déjà dû obtenir une évaluation indépendante d'une de vos applications? À Statistique Canada nous avons déjà fait ce genre de revue pour un autre ministère à l'aide du Cadre discuté dans cet article et sommes disponibles pour faire d'autres revues si le besoin se présente. Veuillez contacter statcan.dscd-ml-review-dscd-revue-aa.statcan@statcan.gc.ca.